




vishal
@vishal-learner.bsky.social
Machine Learning. https://fast.ai community member. Will post about sports occasionally. #FlyEaglesFly
https://www.youtube.com/@vishal_learner
https://www.youtube.com/@vishal_learner
(beyond) cool to see scaling laws in action
After 1 epoch each (1.03B tokens):
llama-5m-L4: 4.6367
llama-25m-L4: 1.6456
llama-60m-A100: 1.286
llama-125m-A100: 1.1558
After 1 epoch each (1.03B tokens):
llama-5m-L4: 4.6367
llama-25m-L4: 1.6456
llama-60m-A100: 1.286
llama-125m-A100: 1.1558

April 27, 2025 at 7:57 AM
(beyond) cool to see scaling laws in action
After 1 epoch each (1.03B tokens):
llama-5m-L4: 4.6367
llama-25m-L4: 1.6456
llama-60m-A100: 1.286
llama-125m-A100: 1.1558
After 1 epoch each (1.03B tokens):
llama-5m-L4: 4.6367
llama-25m-L4: 1.6456
llama-60m-A100: 1.286
llama-125m-A100: 1.1558
Project goals: Study both training dynamics of tiny models and their language capabilities (grammar, context tracking, factual knowledge, reasoning, creativity, and plot construction). Looking forward to sharing more progress soon!
/end
/end

April 27, 2025 at 7:51 AM
Project goals: Study both training dynamics of tiny models and their language capabilities (grammar, context tracking, factual knowledge, reasoning, creativity, and plot construction). Looking forward to sharing more progress soon!
/end
/end
Next steps: Pausing training to build evaluation infrastructure. Will use Gemini Flash 2.5 or Claude Haiku 3.5 as LLM judges (on TinyStories-1M/8M/28M/33M-generated stories), comparing against manual evaluation to refine scoring prompts for six capability categories.

April 27, 2025 at 7:51 AM
Next steps: Pausing training to build evaluation infrastructure. Will use Gemini Flash 2.5 or Claude Haiku 3.5 as LLM judges (on TinyStories-1M/8M/28M/33M-generated stories), comparing against manual evaluation to refine scoring prompts for six capability categories.
Details on the architectures I'm using---the LlamaConfigs are shared in the blog post above. I'm loosely referencing the official TinyStories models (intermediate dim = 4 x hidden dim). Intentionally undershooting named model sizes.

April 27, 2025 at 7:51 AM
Details on the architectures I'm using---the LlamaConfigs are shared in the blog post above. I'm loosely referencing the official TinyStories models (intermediate dim = 4 x hidden dim). Intentionally undershooting named model sizes.
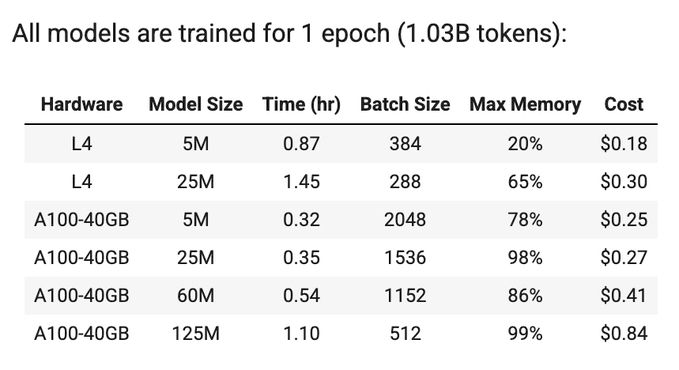
Cost analysis: L4 GPU is more efficient for 5M model (~$0.20/epoch), while A100 is better for larger models. 125M model costs ~$0.84/epoch. This gives me a baseline to plan my budget for longer training runs.
April 27, 2025 at 7:51 AM
Cost analysis: L4 GPU is more efficient for 5M model (~$0.20/epoch), while A100 is better for larger models. 125M model costs ~$0.84/epoch. This gives me a baseline to plan my budget for longer training runs.
TinyScaleLab update: Completed initial training runs to estimate costs. Using 4 model sizes: 5M, 25M, 60M, and 125M parameters. Training on TinyStories dataset (4.9M stories, ~1B tokens) with Llama2 tokenizer (32k vocab).

April 27, 2025 at 7:51 AM
TinyScaleLab update: Completed initial training runs to estimate costs. Using 4 model sizes: 5M, 25M, 60M, and 125M parameters. Training on TinyStories dataset (4.9M stories, ~1B tokens) with Llama2 tokenizer (32k vocab).
Here's the blog post version of my TinyScale Lab research project kickoff video!
vishalbakshi.github.io/blog/posts/2...
Blog post written by Claude w/ a few minor formatting and 1 rephrasing edits done by me (prompt attached). It used most phrasing verbatim from my video transcript+slides.
vishalbakshi.github.io/blog/posts/2...
Blog post written by Claude w/ a few minor formatting and 1 rephrasing edits done by me (prompt attached). It used most phrasing verbatim from my video transcript+slides.

April 27, 2025 at 3:20 AM
Here's the blog post version of my TinyScale Lab research project kickoff video!
vishalbakshi.github.io/blog/posts/2...
Blog post written by Claude w/ a few minor formatting and 1 rephrasing edits done by me (prompt attached). It used most phrasing verbatim from my video transcript+slides.
vishalbakshi.github.io/blog/posts/2...
Blog post written by Claude w/ a few minor formatting and 1 rephrasing edits done by me (prompt attached). It used most phrasing verbatim from my video transcript+slides.
P.S. if you are unfamiliar, here are my main takeaways from the TinyStories (Eldan/Li) and Small-scale proxies (Wortsman, et al) papers. Really incredibly inspiring work. I am giddy to jump into this project. LFG!!!


April 26, 2025 at 6:27 AM
P.S. if you are unfamiliar, here are my main takeaways from the TinyStories (Eldan/Li) and Small-scale proxies (Wortsman, et al) papers. Really incredibly inspiring work. I am giddy to jump into this project. LFG!!!
I'll end with one of my favorite quotes. I am standing on the shoulders of giants to even consider taking on this research project!

April 26, 2025 at 6:27 AM
I'll end with one of my favorite quotes. I am standing on the shoulders of giants to even consider taking on this research project!
Here's a recap of my presentation, highlighting my goals for the TinyScale Lab research project!

April 26, 2025 at 6:27 AM
Here's a recap of my presentation, highlighting my goals for the TinyScale Lab research project!
My project timeline consists of 4 phases. I expect this project to take 8-12 months (which means it will probably take two years 😅). First order of business is building the eval and logging setup, and then running initial training runs. Phase 2 involves core experimentation!

April 26, 2025 at 6:27 AM
My project timeline consists of 4 phases. I expect this project to take 8-12 months (which means it will probably take two years 😅). First order of business is building the eval and logging setup, and then running initial training runs. Phase 2 involves core experimentation!
My rough back-of-the-envelope budget is $2000. I'll closely monitor this each week. If it seems to be heading in that direction consistently, I'll have to seriously consider building my own GPU rig. But time will tell!

April 26, 2025 at 6:27 AM
My rough back-of-the-envelope budget is $2000. I'll closely monitor this each week. If it seems to be heading in that direction consistently, I'll have to seriously consider building my own GPU rig. But time will tell!
Following fastai principles, I'll build in public: sharing code, models, datasets, weekly updates, and interactive visualizations. If this work saves someone time, money, or gives them insight, that would be truly the best reward.

April 26, 2025 at 6:27 AM
Following fastai principles, I'll build in public: sharing code, models, datasets, weekly updates, and interactive visualizations. If this work saves someone time, money, or gives them insight, that would be truly the best reward.
My plan: extensive logging of training dynamics + evaluating capabilities with LLM judge scoring. I'll train 100+ model variations across different learning rates and stability techniques (QK-layernorm and z-loss).


April 26, 2025 at 6:27 AM
My plan: extensive logging of training dynamics + evaluating capabilities with LLM judge scoring. I'll train 100+ model variations across different learning rates and stability techniques (QK-layernorm and z-loss).
Making ML research accessible to resource-constrained environments isn't trivial - it's essential for the field's diversity and progress! I'm using modest computational resources (but substantial for me) to conduct what I think is meaningful research.

April 26, 2025 at 6:27 AM
Making ML research accessible to resource-constrained environments isn't trivial - it's essential for the field's diversity and progress! I'm using modest computational resources (but substantial for me) to conduct what I think is meaningful research.
I believe this approach—using tiny models as proxies to study phenomena relevant to models of all sizes—represents an underexplored path that could benefit other resource-constrained researchers. I think this is how most of the world's potential researchers would need to work.

April 26, 2025 at 6:27 AM
I believe this approach—using tiny models as proxies to study phenomena relevant to models of all sizes—represents an underexplored path that could benefit other resource-constrained researchers. I think this is how most of the world's potential researchers would need to work.
My hypothesis: training stability directly affects specific model capabilities in predictable ways. I'll train models from 3M to 120M params, analyzing how logits, gradients, parameters, and loss relate to capabilities like grammar, consistency, and reasoning.

April 26, 2025 at 6:27 AM
My hypothesis: training stability directly affects specific model capabilities in predictable ways. I'll train models from 3M to 120M params, analyzing how logits, gradients, parameters, and loss relate to capabilities like grammar, consistency, and reasoning.
Excited to kickoff a new research project: TinyScale Lab! I'm researching the connection b/w training dynamics and model capabilities in tiny LMs. Following the work of TinyStories (Eldan & Li) and Small-scale proxies (Wortsman, et al) papers, and building a bridge between them🧵
April 26, 2025 at 6:27 AM
Excited to kickoff a new research project: TinyScale Lab! I'm researching the connection b/w training dynamics and model capabilities in tiny LMs. Following the work of TinyStories (Eldan & Li) and Small-scale proxies (Wortsman, et al) papers, and building a bridge between them🧵
This research, along with TinyStories, has reignited my passion for tiny models! Tomorrow I'm launching my new "TinyScale Lab" research project where I'll apply these insights (and more!). Stay tuned - it'll be open source, fully documented and researched in public!
/end
/end

April 25, 2025 at 6:16 AM
This research, along with TinyStories, has reignited my passion for tiny models! Tomorrow I'm launching my new "TinyScale Lab" research project where I'll apply these insights (and more!). Stay tuned - it'll be open source, fully documented and researched in public!
/end
/end
Just posted a new video breaking down "Small-Scale Proxies for Large-Scale Transformer Training Instabilities" from Google DeepMind - one of my favorite papers because it shows how tiny models exhibit can predict large scale training problems! 🧵

April 25, 2025 at 6:16 AM
Just posted a new video breaking down "Small-Scale Proxies for Large-Scale Transformer Training Instabilities" from Google DeepMind - one of my favorite papers because it shows how tiny models exhibit can predict large scale training problems! 🧵
I created a custom Composer callback to inspect how LLM-Foundry handles next-token prediction. After 27 commits and hours of digging through the code, I finally traced through the entire pipeline from batch creation to loss calculation.
Video: www.youtube.com/watch?v=9ffn...
Video: www.youtube.com/watch?v=9ffn...

April 23, 2025 at 5:04 AM
I created a custom Composer callback to inspect how LLM-Foundry handles next-token prediction. After 27 commits and hours of digging through the code, I finally traced through the entire pipeline from batch creation to loss calculation.
Video: www.youtube.com/watch?v=9ffn...
Video: www.youtube.com/watch?v=9ffn...
Visualizing these operations (in Excalidraw) was key to my understanding - I've included illustrations of how for-loops, dot product and broadcasting works; each optimization allowing us to eliminate another Python loop (the true bottlenecks in our computation).



April 22, 2025 at 2:20 AM
Visualizing these operations (in Excalidraw) was key to my understanding - I've included illustrations of how for-loops, dot product and broadcasting works; each optimization allowing us to eliminate another Python loop (the true bottlenecks in our computation).
My eyes always gloss over at the naive matmul loop so I decided to annotate it once and for all---and oh! back on the fastai part 2 course horse!

April 21, 2025 at 3:22 PM
My eyes always gloss over at the naive matmul loop so I decided to annotate it once and for all---and oh! back on the fastai part 2 course horse!
Just posted a new video breaking down the TinyStories paper - I didn't give enough credit to how amazing this paper was until I participated in a Tiny Hackathon myself! The simplicity of this work sometimes doesn't give enough credit to how incredible the insights are 🧵

April 21, 2025 at 1:32 AM
Just posted a new video breaking down the TinyStories paper - I didn't give enough credit to how amazing this paper was until I participated in a Tiny Hackathon myself! The simplicity of this work sometimes doesn't give enough credit to how incredible the insights are 🧵
The callback logs showed interesting patterns between fp32 vs bf16 training: with fp32 master weights (first image) everything except activations uses fp32, while with bf16 master weights, only loss and some optimizer states remain in fp32.


April 3, 2025 at 3:16 AM
The callback logs showed interesting patterns between fp32 vs bf16 training: with fp32 master weights (first image) everything except activations uses fp32, while with bf16 master weights, only loss and some optimizer states remain in fp32.