



Vikram Shivakumar
@vikramshivakumar.bsky.social
PhD Student @ JHU Langmead Lab
And of course, the poster itself:
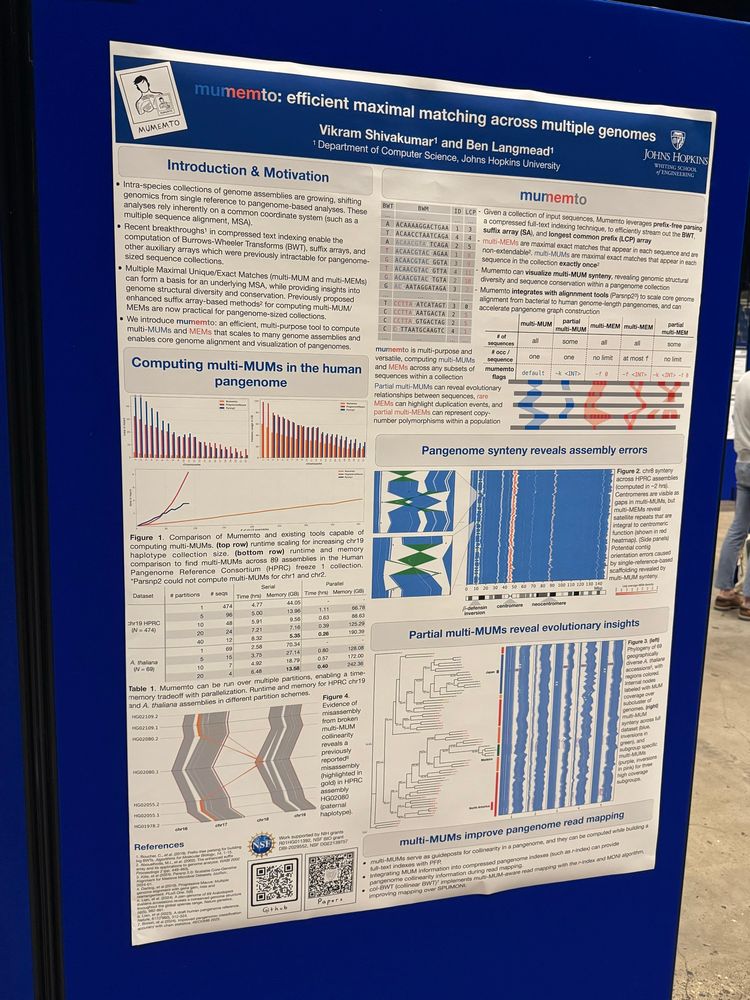
July 21, 2025 at 5:00 PM
And of course, the poster itself:
We can also merge along the shape of a phylogenetic tree, finding clade-specific variation and conserved elements. Previously, adding new assemblies can lose MUMs, which must be present across the whole collection. Now we can find MUMs that reveal local variation distinct to specific subgroups. 3/n
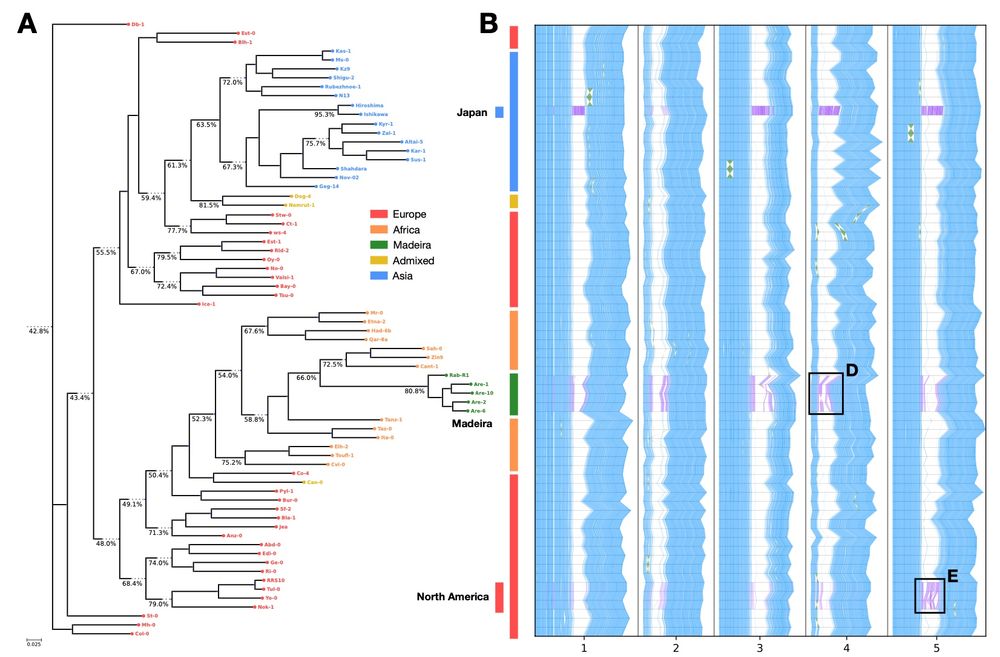
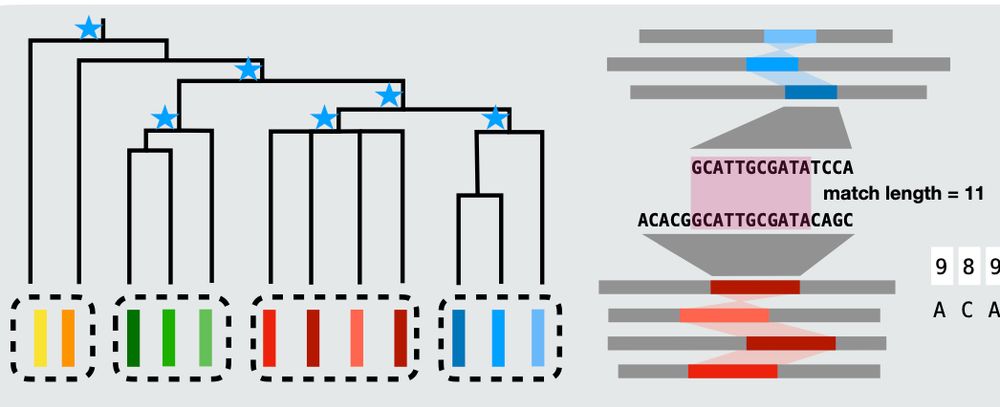
May 27, 2025 at 7:35 PM
We can also merge along the shape of a phylogenetic tree, finding clade-specific variation and conserved elements. Previously, adding new assemblies can lose MUMs, which must be present across the whole collection. Now we can find MUMs that reveal local variation distinct to specific subgroups. 3/n
We implement two partition/merge algorithms that can merge multi-MUMs between datasets. This makes Mumemto highly parallelizable, but also very memory efficient if partitions are computed in serial. 2/n
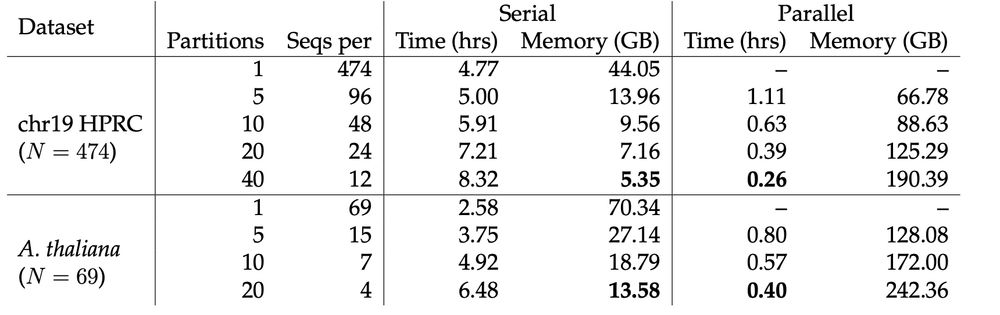
May 27, 2025 at 7:35 PM
We implement two partition/merge algorithms that can merge multi-MUMs between datasets. This makes Mumemto highly parallelizable, but also very memory efficient if partitions are computed in serial. 2/n
Excited to share our latest work on comparing and visualizing multiple genome assemblies to identify conservation and structural variation in pangenomes with Mumemto! Check out poster 250 at #bog25 if you are here. New preprint coming very soon 👀
May 9, 2025 at 4:26 PM
Excited to share our latest work on comparing and visualizing multiple genome assemblies to identify conservation and structural variation in pangenomes with Mumemto! Check out poster 250 at #bog25 if you are here. New preprint coming very soon 👀
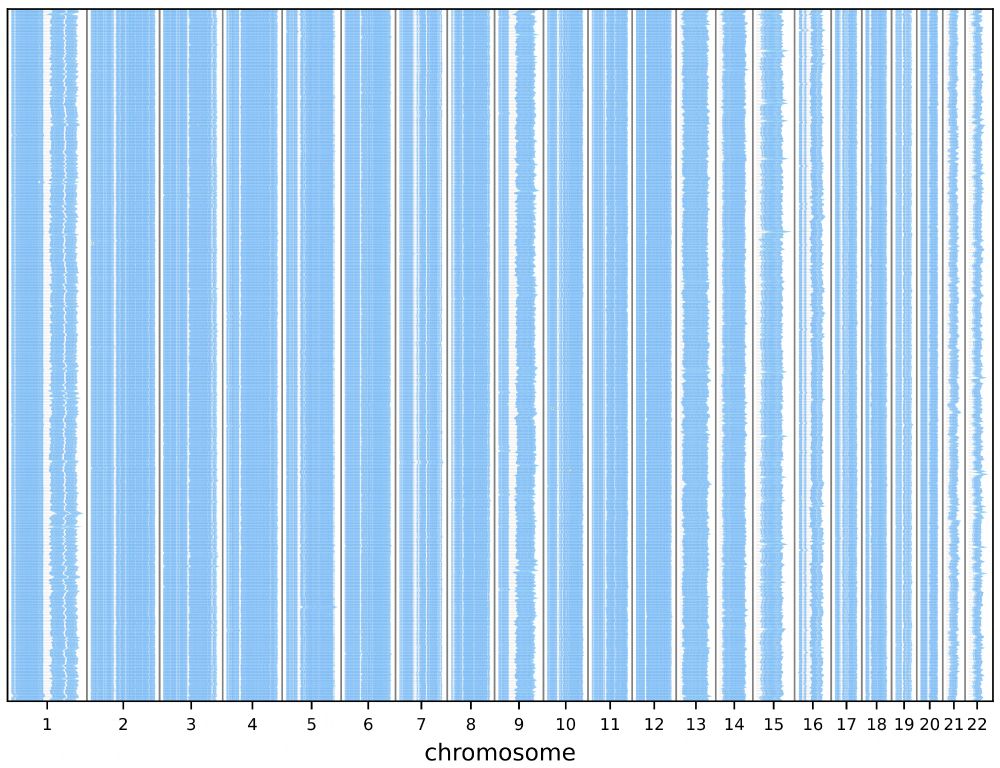
We ran Mumemto on 474 human assemblies from @humanpangenome.bsky.social to find syntenic regions using MUMs. Mumemto scales remarkably well to large pangenomes thanks to compressed-space algos! It took under 2 days across 7 nodes (each using ~500 GB memory).
February 26, 2025 at 6:01 PM
We ran Mumemto on 474 human assemblies from @humanpangenome.bsky.social to find syntenic regions using MUMs. Mumemto scales remarkably well to large pangenomes thanks to compressed-space algos! It took under 2 days across 7 nodes (each using ~500 GB memory).
p.p.s here's a logo I designed for Mumemto (pronounced like memento) inspired by the film.

January 6, 2025 at 3:32 PM
p.p.s here's a logo I designed for Mumemto (pronounced like memento) inspired by the film.
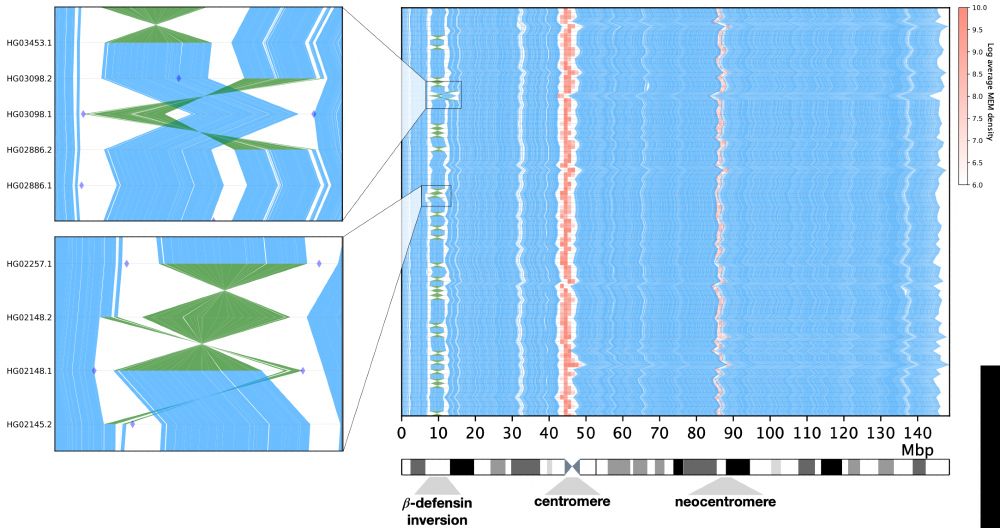
Mumemto can visualize multi-MUM synteny to reveal large-scale pangenome structure. We also showed that multi-MUMs can reveal potential misassemblies (e.g one reported in HPRC v1) and scaffolding errors (contigs are oriented to match a reference w/o the pangenome context revealing a common inversion)
January 6, 2025 at 3:32 PM
Mumemto can visualize multi-MUM synteny to reveal large-scale pangenome structure. We also showed that multi-MUMs can reveal potential misassemblies (e.g one reported in HPRC v1) and scaffolding errors (contigs are oriented to match a reference w/o the pangenome context revealing a common inversion)
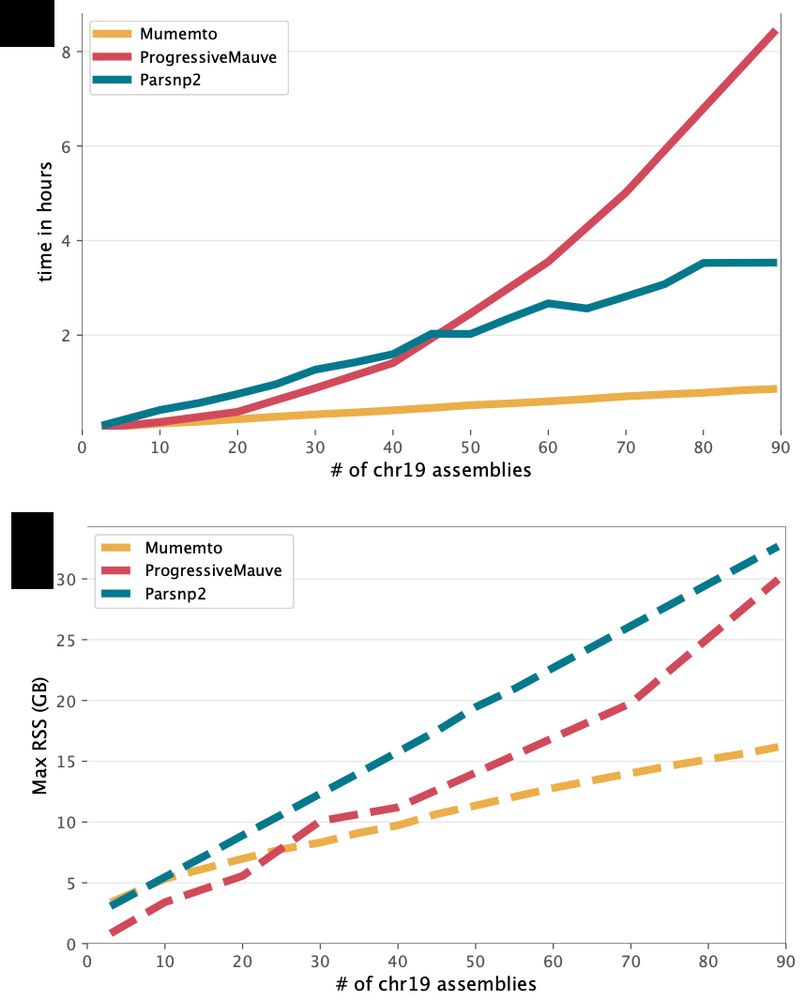
Mumemto uses prefix-free parsing, a compressed-space method to compute the enhance suffix array, to efficiently index large pangenome collections. This makes it quick and memory efficient, with remarkable scaling, enabling multi-MUM computation across hundreds of HPRC assemblies.
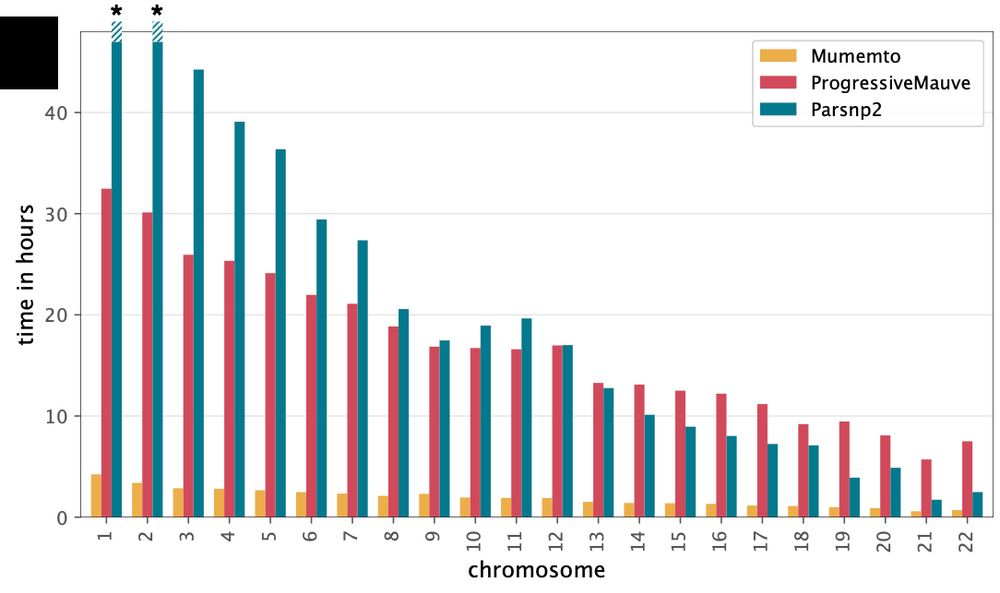
January 6, 2025 at 3:32 PM
Mumemto uses prefix-free parsing, a compressed-space method to compute the enhance suffix array, to efficiently index large pangenome collections. This makes it quick and memory efficient, with remarkable scaling, enabling multi-MUM computation across hundreds of HPRC assemblies.