



@ttunguz.bsky.social
Gemini 3 proves the scaling laws are intact, so Blackwell’s extra power will translate directly into better model capabilities, not just cost efficiency.
Together, these two data points dismantle the scaling wall thesis.
tomtunguz.com/gemini-3-pro...
Together, these two data points dismantle the scaling wall thesis.
tomtunguz.com/gemini-3-pro...

The Scaling Wall Was A Mirage
Gemini 3's release and Nvidia's earnings confirm that AI scaling laws are accelerating. Pre-training gains combined with massive infrastructure buildouts signal a new era of model performance.
tomtunguz.com
November 20, 2025 at 8:17 PM
Gemini 3 proves the scaling laws are intact, so Blackwell’s extra power will translate directly into better model capabilities, not just cost efficiency.
Together, these two data points dismantle the scaling wall thesis.
tomtunguz.com/gemini-3-pro...
Together, these two data points dismantle the scaling wall thesis.
tomtunguz.com/gemini-3-pro...
The infrastructure is accelerating headlong into hundreds of billions next year & Nvidia predicts it will be in the trillions, citing “$3 trillion to $4 trillion in data center by 2030”.
As Gavin Baker points out, Nvidia confirmed Blackwell Ultra delivers 5x faster training times than Hopper.
As Gavin Baker points out, Nvidia confirmed Blackwell Ultra delivers 5x faster training times than Hopper.
November 20, 2025 at 8:17 PM
The infrastructure is accelerating headlong into hundreds of billions next year & Nvidia predicts it will be in the trillions, citing “$3 trillion to $4 trillion in data center by 2030”.
As Gavin Baker points out, Nvidia confirmed Blackwell Ultra delivers 5x faster training times than Hopper.
As Gavin Baker points out, Nvidia confirmed Blackwell Ultra delivers 5x faster training times than Hopper.
"The clouds are sold out and our GPU installed base, both new and previous generations, including Blackwell, Hopper and Ampere is fully utilized. Record Q3 data center revenue of $51 billion increased 66% year-over-year, a significant feat at our scale."
November 20, 2025 at 8:17 PM
"The clouds are sold out and our GPU installed base, both new and previous generations, including Blackwell, Hopper and Ampere is fully utilized. Record Q3 data center revenue of $51 billion increased 66% year-over-year, a significant feat at our scale."
By executing our annual product cadence and extending our performance leadership through full stack design, we believe NVIDIA will be the superior choice for the $3 trillion to $4 trillion in annual AI infrastructure build we estimate by the end of the decade."
November 20, 2025 at 8:17 PM
By executing our annual product cadence and extending our performance leadership through full stack design, we believe NVIDIA will be the superior choice for the $3 trillion to $4 trillion in annual AI infrastructure build we estimate by the end of the decade."
"We currently have visibility to $0.5 trillion in Blackwell and Rubin revenue from the start of this year through the end of calendar year 2026...
November 20, 2025 at 8:17 PM
"We currently have visibility to $0.5 trillion in Blackwell and Rubin revenue from the start of this year through the end of calendar year 2026...
This is the strongest evidence since o1 that pre-training scaling still works when algorithmic improvements meet better compute.
Second, Nvidia’s earnings call reinforced the demand.
Second, Nvidia’s earnings call reinforced the demand.
November 20, 2025 at 8:17 PM
This is the strongest evidence since o1 that pre-training scaling still works when algorithmic improvements meet better compute.
Second, Nvidia’s earnings call reinforced the demand.
Second, Nvidia’s earnings call reinforced the demand.
Oriol Vinyals, VP of Research at Google DeepMind, credited improving pre-training & post-training for the gains. He continued that the delta between 2.5 & 3.0 is as big as Google has ever seen with no walls in sight.
November 20, 2025 at 8:17 PM
Oriol Vinyals, VP of Research at Google DeepMind, credited improving pre-training & post-training for the gains. He continued that the delta between 2.5 & 3.0 is as big as Google has ever seen with no walls in sight.
Then Gemini 3 launched. The model has the same parameter count as Gemini 2.5, one trillion parameters, yet achieved massive performance improvements. It’s the first model to break 1500 Elo on LMArena & beat GPT-5.1 on 19 of 20 benchmarks.
November 20, 2025 at 8:17 PM
Then Gemini 3 launched. The model has the same parameter count as Gemini 2.5, one trillion parameters, yet achieved massive performance improvements. It’s the first model to break 1500 Elo on LMArena & beat GPT-5.1 on 19 of 20 benchmarks.
Context remains the true challenge & the biggest opportunity for the next generation of AI infrastructure.
Explore the full interactive dataset here : survey.theoryvc.com or read Lauren’s complete analysis : theoryvc.com/blog-posts/a....
tomtunguz.com/ai-builders-...
Explore the full interactive dataset here : survey.theoryvc.com or read Lauren’s complete analysis : theoryvc.com/blog-posts/a....
tomtunguz.com/ai-builders-...
survey.theoryvc.comor
November 17, 2025 at 11:30 PM
Context remains the true challenge & the biggest opportunity for the next generation of AI infrastructure.
Explore the full interactive dataset here : survey.theoryvc.com or read Lauren’s complete analysis : theoryvc.com/blog-posts/a....
tomtunguz.com/ai-builders-...
Explore the full interactive dataset here : survey.theoryvc.com or read Lauren’s complete analysis : theoryvc.com/blog-posts/a....
tomtunguz.com/ai-builders-...
The tools exist. The problem is harder than better retrieval or smarter chunking can solve.
Teams need systems that verify correctness before they can scale production. The tools exist. The problem is harder than better retrieval can solve.
Teams need systems that verify correctness before they can scale production. The tools exist. The problem is harder than better retrieval can solve.
November 17, 2025 at 11:30 PM
The tools exist. The problem is harder than better retrieval or smarter chunking can solve.
Teams need systems that verify correctness before they can scale production. The tools exist. The problem is harder than better retrieval can solve.
Teams need systems that verify correctness before they can scale production. The tools exist. The problem is harder than better retrieval can solve.
88% use automated methods for improving context. Yet it remains the #1 pain point in deploying AI products. This gap between tooling adoption & problem resolution points to a fundamental challenge.

November 17, 2025 at 11:30 PM
88% use automated methods for improving context. Yet it remains the #1 pain point in deploying AI products. This gap between tooling adoption & problem resolution points to a fundamental challenge.
The timing reveals where the stack is heading. Teams need to verify correctness before they can scale production.
November 17, 2025 at 11:30 PM
The timing reveals where the stack is heading. Teams need to verify correctness before they can scale production.
Synthetic data powers evaluation more than training. 65% use synthetic data for eval generation versus 24% for fine-tuning. This points to a near-term surge in eval-data marketplaces, scenario libraries, & failure-mode corpora before synthetic training data scales up.

November 17, 2025 at 11:30 PM
Synthetic data powers evaluation more than training. 65% use synthetic data for eval generation versus 24% for fine-tuning. This points to a near-term surge in eval-data marketplaces, scenario libraries, & failure-mode corpora before synthetic training data scales up.
The center of gravity is data & execution, not conversation. Sophisticated teams build MCPs to access their own internal systems (58%) & external APIs (54%).
November 17, 2025 at 11:30 PM
The center of gravity is data & execution, not conversation. Sophisticated teams build MCPs to access their own internal systems (58%) & external APIs (54%).
Agents in the field are systems operators, not chat interfaces. We thought agents would mostly call APIs. Instead, 72.5% connect to databases. 61% to web search. 56% to memory systems & file systems. 47% to code interpreters.

November 17, 2025 at 11:30 PM
Agents in the field are systems operators, not chat interfaces. We thought agents would mostly call APIs. Instead, 72.5% connect to databases. 61% to web search. 56% to memory systems & file systems. 47% to code interpreters.
70% of teams use open source models in some capacity. 48% describe their strategy as mostly open. 22% commit to only open. Just 11% stay purely proprietary.

November 17, 2025 at 11:30 PM
70% of teams use open source models in some capacity. 48% describe their strategy as mostly open. 22% commit to only open. Just 11% stay purely proprietary.
This proof of concept works for a small set of tools written in the code mode fashion. It suggests there is a potential for tool calling distillation.
If you’ve tried something similar, I’d love to hear from you.
tomtunguz.com/distilling-c...
If you’ve tried something similar, I’d love to hear from you.
tomtunguz.com/distilling-c...
Teaching Local Models to Call Tools Like Claude
We achieved 93% Claude parity in tool calling by distilling large model capabilities into GPT-OSS 20B using DSPy & GEPA prompt optimization with curated training data.
tomtunguz.com
November 13, 2025 at 10:22 PM
This proof of concept works for a small set of tools written in the code mode fashion. It suggests there is a potential for tool calling distillation.
If you’ve tried something similar, I’d love to hear from you.
tomtunguz.com/distilling-c...
If you’ve tried something similar, I’d love to hear from you.
tomtunguz.com/distilling-c...
Make no mistake : matching Claude 93% doesn’t mean 93% accuracy. When we benchmarked Claude itself, it only produced consistent results about 50% of the time. This is non-determinism at work.
November 13, 2025 at 10:22 PM
Make no mistake : matching Claude 93% doesn’t mean 93% accuracy. When we benchmarked Claude itself, it only produced consistent results about 50% of the time. This is non-determinism at work.
DSPy improved accuracy from 0% to 12%, and GEPA pushed it much higher, all the way to 93%, after three phases. The local model now matches Claude’s tool call chain in 93% of cases.
November 13, 2025 at 10:22 PM
DSPy improved accuracy from 0% to 12%, and GEPA pushed it much higher, all the way to 93%, after three phases. The local model now matches Claude’s tool call chain in 93% of cases.
Combined, we improved from a 12% Claude match rate to 93% in three iterations by increasing the data volume to cover different scenarios :

November 13, 2025 at 10:22 PM
Combined, we improved from a 12% Claude match rate to 93% in three iterations by increasing the data volume to cover different scenarios :
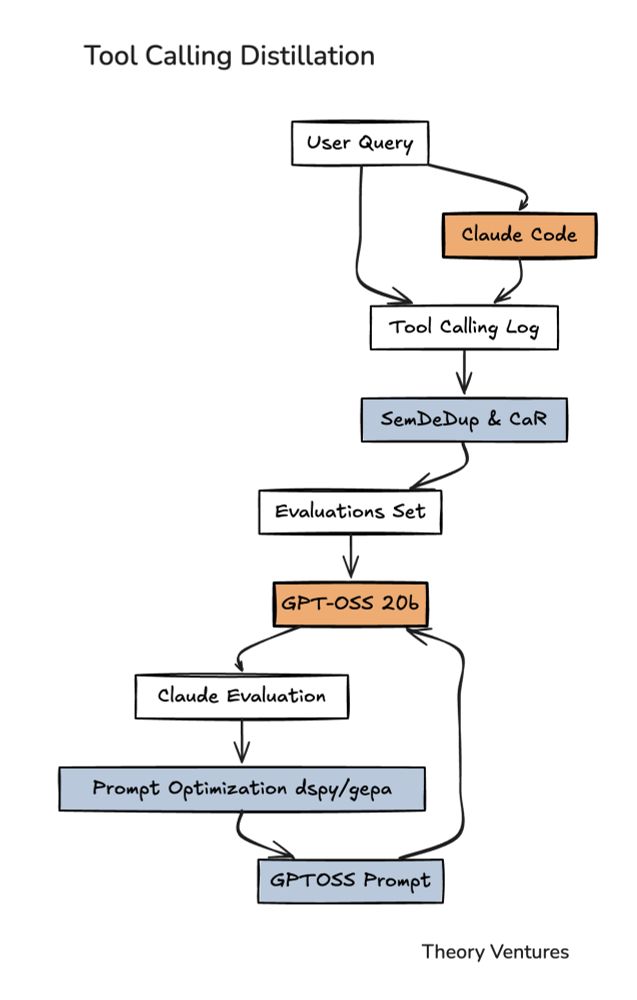
Claude’s assessments were fed into a prompt-optimization system with DSPy & GEPA. All of that data was then fed to improve the prompt. DSPy searches for existing examples that could improve the prompt, while GEPA mutates or tests different mutations.
November 13, 2025 at 10:22 PM
Claude’s assessments were fed into a prompt-optimization system with DSPy & GEPA. All of that data was then fed to improve the prompt. DSPy searches for existing examples that could improve the prompt, while GEPA mutates or tests different mutations.
We wanted to choose the right data so we used algorithms to cherry-pick. We used SemDeDup & CaR, algorithms to find the data examples that lead to better results.
Claude Code fired up our local model powered by GPT-OSS 20b & peppered it with the queries. Claude graded GPT on which tools it calls.
Claude Code fired up our local model powered by GPT-OSS 20b & peppered it with the queries. Claude graded GPT on which tools it calls.
November 13, 2025 at 10:22 PM
We wanted to choose the right data so we used algorithms to cherry-pick. We used SemDeDup & CaR, algorithms to find the data examples that lead to better results.
Claude Code fired up our local model powered by GPT-OSS 20b & peppered it with the queries. Claude graded GPT on which tools it calls.
Claude Code fired up our local model powered by GPT-OSS 20b & peppered it with the queries. Claude graded GPT on which tools it calls.
Every time we used Claude Code, we logged the session - our query, available tools, & which tools Claude chose. These logs became training examples showing the local model what good tool calling looks like.
November 13, 2025 at 10:22 PM
Every time we used Claude Code, we logged the session - our query, available tools, & which tools Claude chose. These logs became training examples showing the local model what good tool calling looks like.