



Stephen Hwang
@stephenhwang.bsky.social
Debugging wet code 💻🧬
@XDBio, JHMI; Langmead Lab
@XDBio, JHMI; Langmead Lab
Reposted by Stephen Hwang

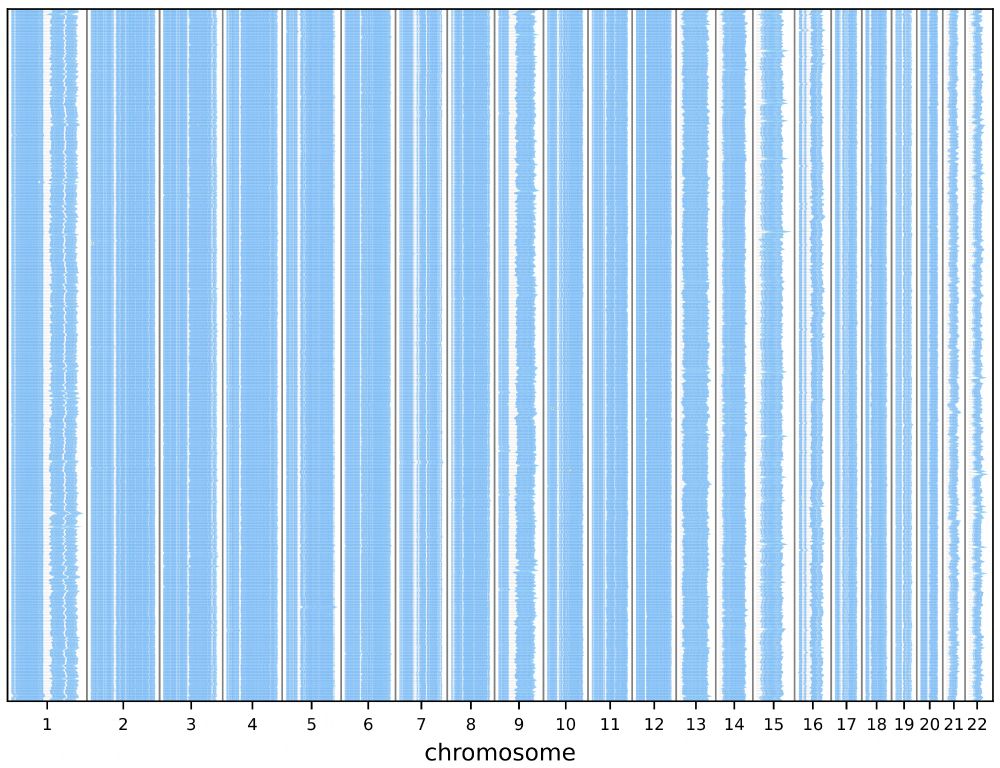
We ran Mumemto on 474 human assemblies from @humanpangenome.bsky.social to find syntenic regions using MUMs. Mumemto scales remarkably well to large pangenomes thanks to compressed-space algos! It took under 2 days across 7 nodes (each using ~500 GB memory).
February 26, 2025 at 6:01 PM
We ran Mumemto on 474 human assemblies from @humanpangenome.bsky.social to find syntenic regions using MUMs. Mumemto scales remarkably well to large pangenomes thanks to compressed-space algos! It took under 2 days across 7 nodes (each using ~500 GB memory).
Reposted by Stephen Hwang
Excited to share a preprint for (w/ @benlangmead.bsky.social) our new tool, Mumemto, on biorxiv! Mumemto finds multi-MUMs across pangenomes (i.e. mummer but for pangenomes). It can rapidly visualize synteny, identify misassemblies, and accelerate core genome and multiple alignment, highlighting SVs.

Mumemto: efficient maximal matching across pangenomes
Aligning genomes into common coordinates is central to pangenome analysis and construction, but it is also computationally expensive. Multi-sequence maximal unique matches (multi-MUMs) are guideposts ...
www.biorxiv.org
January 6, 2025 at 3:27 PM
Excited to share a preprint for (w/ @benlangmead.bsky.social) our new tool, Mumemto, on biorxiv! Mumemto finds multi-MUMs across pangenomes (i.e. mummer but for pangenomes). It can rapidly visualize synteny, identify misassemblies, and accelerate core genome and multiple alignment, highlighting SVs.
Reposted by Stephen Hwang

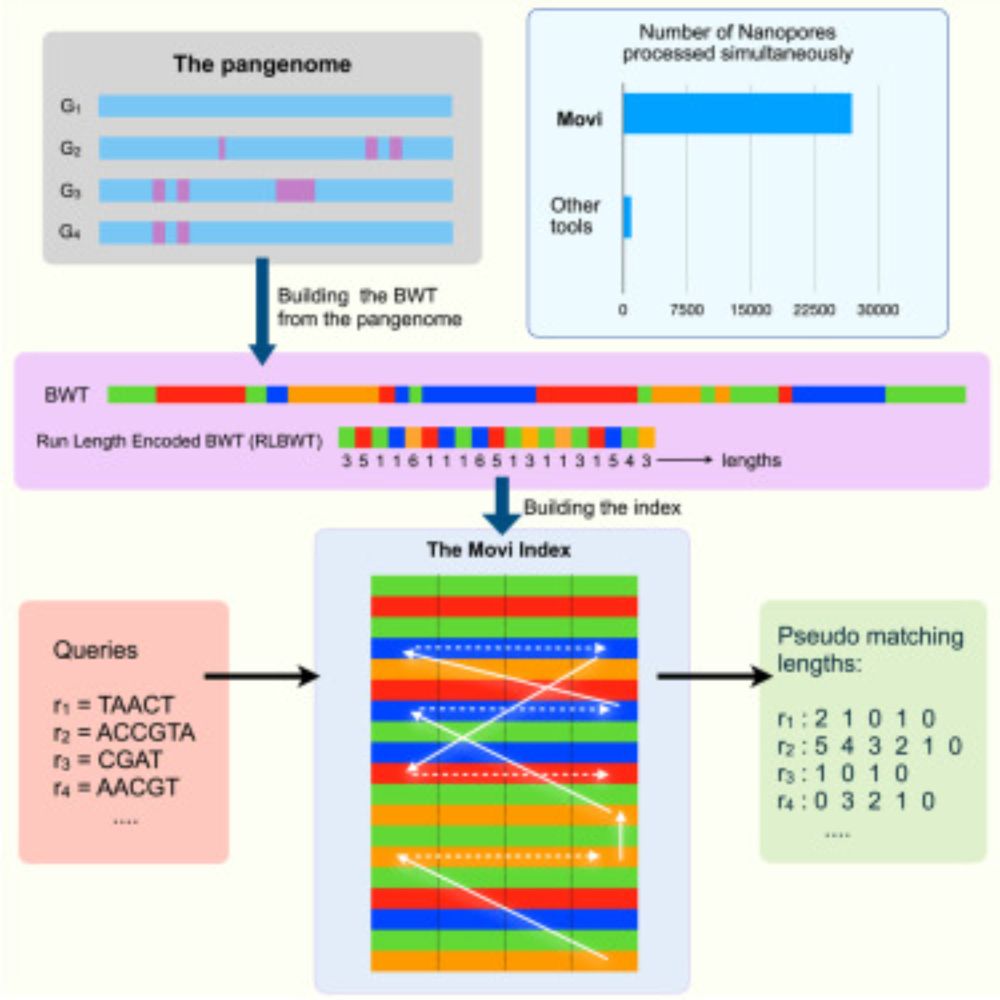
Very excited to see Movi (by @mohsenzakeri.bsky.social) now out in iScience: www.cell.com/iscience/ful.... Movi builds on the "move structure" pangenome index, a compressed full-text index and close cousin to r-index. Compared to r-index, the move structure is simpler and more cache-efficient.
Movi: A fast and cache-efficient full-text pangenome index
Biocomputational method; Classification of bioinformatical subject; Genomic analysis
www.cell.com
December 11, 2024 at 4:48 PM
Very excited to see Movi (by @mohsenzakeri.bsky.social) now out in iScience: www.cell.com/iscience/ful.... Movi builds on the "move structure" pangenome index, a compressed full-text index and close cousin to r-index. Compared to r-index, the move structure is simpler and more cache-efficient.
Reposted by Stephen Hwang

1/5 We (Nate Brown, @oahmed.bsky.social, Travis Gagie, and @benlangmead.bsky.social) developed Movi, a cache-efficient full-text pangenome index. It's the fastest full-text index for pangenomes, particularly appropriate for adaptive sampling where time budget is important.

Movi: a fast and cache-efficient full-text pangenome index https://www.biorxiv.org/content/10.1101/2023.11.04.565615v1

Movi: a fast and cache-efficient full-text pangenome index https://www.biorxiv.org/content/10.1101/2023.11.04.565615v1
Efficient pangenome indexes are promising tools for many applications, including rapid classificatio
www.biorxiv.org
November 7, 2023 at 6:46 PM
1/5 We (Nate Brown, @oahmed.bsky.social, Travis Gagie, and @benlangmead.bsky.social) developed Movi, a cache-efficient full-text pangenome index. It's the fastest full-text index for pangenomes, particularly appropriate for adaptive sampling where time budget is important.