


spascarelli.bsky.social
@spascarelli.bsky.social
Reposted by spascarelli.bsky.social

Can ever-increasing sequence databases improve phylogenetic reconstruction of a gene family? Our new preprint introduces AmpliPhy, a pipeline that automates homolog enrichment to improve gene tree inference, built on a robust phylogenomic benchmark scheme. 🧵1/n
📃 doi.org/10.64898/2026.01.26.701724
📃 doi.org/10.64898/2026.01.26.701724
AmpliPhy improves gene trees by adding homologs without affecting alignments
In phylogenomics, gene tree reconstruction depends on multiple sequence alignment (MSA) and tree inference, and ongoing work continues to improve inference quality. Denser taxon sampling has been associated with improved gene tree inference, suggesting that adding homologs could be a practical route to higher accuracy as sequence databases continue to expand. However, adding sequences can influence multiple steps of typical inference pipelines, and little is known on its specific effect on the multiple sequence alignment, tree reconstruction, and rooting steps. We performed a large-scale empirical benchmark to quantify how homolog enrichment affects alignment and phylogenetic inference. Using an enrichment-impoverishment design and a measure of tree accuracy based on taxonomic congruence, we found that enrichment consistently improves tree inference quality, while effects on alignment quality are marginal. We show that this improvement is associated with accurate root placement on enriched trees when sensitive homolog search is accompanied. Notably, much of the benefit can be retained with relatively compact alignments produced by sequence addition. Building on these observations, we provide a tool, AmpliPhy, which efficiently improves phylogenetic reconstruction of protein families through homolog enrichment. The AmpliPhy open-source pipeline software is available at https://github.com/DessimozLab/ampliphy. ### Competing Interest Statement The authors have declared no competing interest. Swiss National Science Foundation, https://ror.org/00yjd3n13, 216623, 10005715
doi.org
January 28, 2026 at 6:10 AM
Can ever-increasing sequence databases improve phylogenetic reconstruction of a gene family? Our new preprint introduces AmpliPhy, a pipeline that automates homolog enrichment to improve gene tree inference, built on a robust phylogenomic benchmark scheme. 🧵1/n
📃 doi.org/10.64898/2026.01.26.701724
📃 doi.org/10.64898/2026.01.26.701724
Reposted by spascarelli.bsky.social

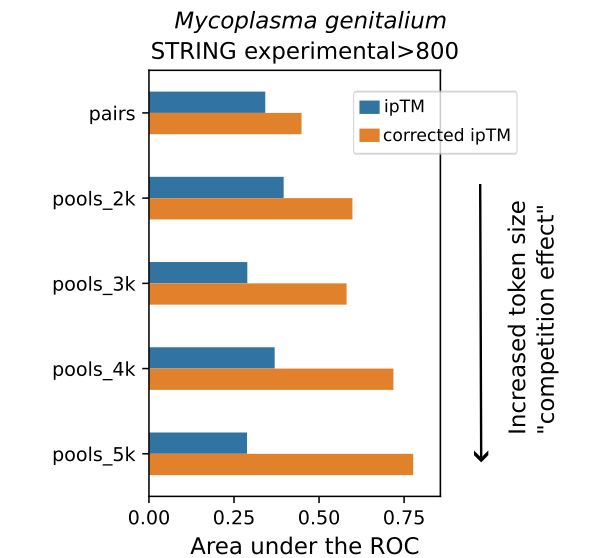
Unexpectedly, @jurgjn.bsky.social found that running Alphafold3 predictions for protein interactions can yield ipTM scores that are more predictive of true interactions when run in pools of proteins instead of pairwise predictions. Presumably, this reflects some sort of "competition effect".
July 22, 2025 at 2:13 PM
Unexpectedly, @jurgjn.bsky.social found that running Alphafold3 predictions for protein interactions can yield ipTM scores that are more predictive of true interactions when run in pools of proteins instead of pairwise predictions. Presumably, this reflects some sort of "competition effect".
Reposted by spascarelli.bsky.social

#CASP16 program is posted (so you can guess the "winners". Congratulations to Yang and Kihara who seems to have done well in RNA+Proteins. Also congratulations to AF3-server (i.e. me) who was selected to talk (i.e. most people did worse than the server). predictioncenter.org/casp16/doc/C... .
predictioncenter.org
November 28, 2024 at 7:39 AM
#CASP16 program is posted (so you can guess the "winners". Congratulations to Yang and Kihara who seems to have done well in RNA+Proteins. Also congratulations to AF3-server (i.e. me) who was selected to talk (i.e. most people did worse than the server). predictioncenter.org/casp16/doc/C... .