



Sayan
@shockroborty.bsky.social
ML/LLM research. Prev @BrownUniversity
i see sink tokens in pre-trained tts and vision-language models all the time, not sure why they are overlooked in multimodal settings
September 2, 2025 at 6:40 PM
i see sink tokens in pre-trained tts and vision-language models all the time, not sure why they are overlooked in multimodal settings
Reposted by Sayan

You can totally see how this mf bankrupted a casino.
April 3, 2025 at 1:45 AM
You can totally see how this mf bankrupted a casino.
Reposted by Sayan

Moonshot + Muon
A new 16B model
The Muon optimizer is 2x more data efficient than AdamE, but only for matrix parameters
note: this is a big deal
huggingface.co/moonshotai
A new 16B model
The Muon optimizer is 2x more data efficient than AdamE, but only for matrix parameters
note: this is a big deal
huggingface.co/moonshotai

moonshotai (Moonshot AI)
Org profile for Moonshot AI on Hugging Face, the AI community building the future.
huggingface.co
February 22, 2025 at 8:42 PM
Moonshot + Muon
A new 16B model
The Muon optimizer is 2x more data efficient than AdamE, but only for matrix parameters
note: this is a big deal
huggingface.co/moonshotai
A new 16B model
The Muon optimizer is 2x more data efficient than AdamE, but only for matrix parameters
note: this is a big deal
huggingface.co/moonshotai
super valuable stuff

After 6+ months in the making and over a year of GPU compute, we're excited to release the "Ultra-Scale Playbook": hf.co/spaces/nanot...
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!

The Ultra-Scale Playbook - a Hugging Face Space by nanotron
The ultimate guide to training LLM on large GPU Clusters
hf.co
February 19, 2025 at 6:42 PM
super valuable stuff
👀🙏

LLM Reasoning labs will be eating good today🍔
We commandeered the HF cluster for a few days and generated 1.2M reasoning-filled solutions to 500k NuminaMath problems with DeepSeek-R1 🐳
Have fun!
We commandeered the HF cluster for a few days and generated 1.2M reasoning-filled solutions to 500k NuminaMath problems with DeepSeek-R1 🐳
Have fun!
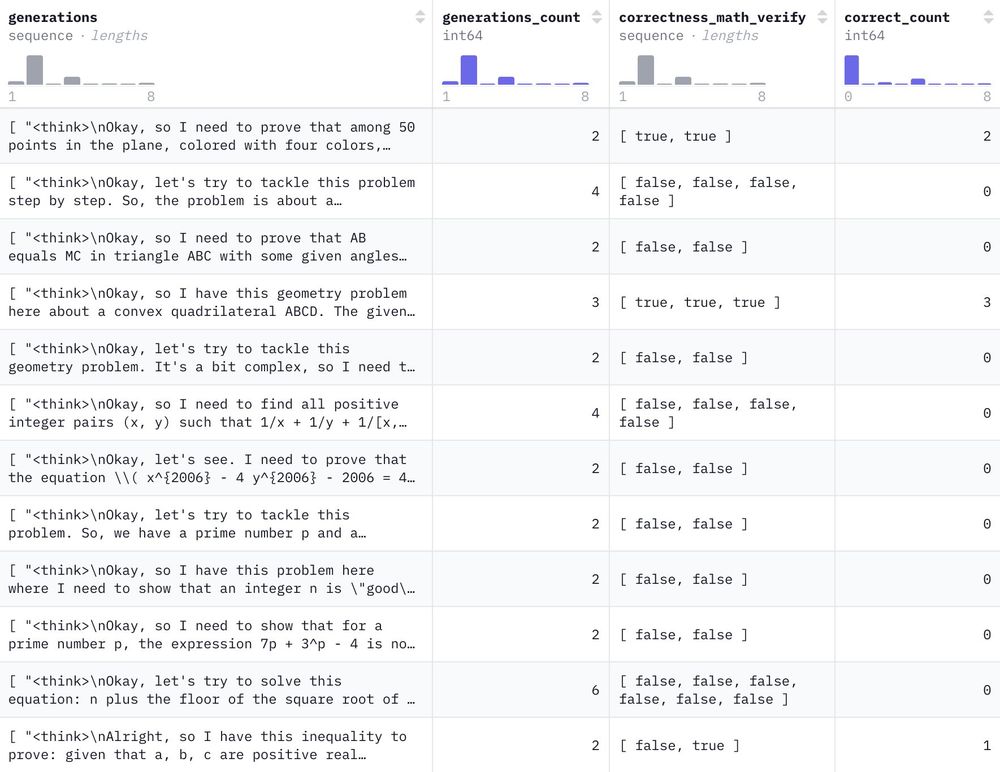
February 12, 2025 at 3:45 PM
👀🙏
Reposted by Sayan

In case it interests anyone, I managed to set up a demo of GRPO RL training in Colab. It’s an adaptation of Will Brown instant classic for math reasoning. Replace llama 1B with qwen 0.5b and inference with vllm. Full training in about 2 hours.
colab.research.google.com/drive/1bfhs1...
colab.research.google.com/drive/1bfhs1...

February 2, 2025 at 1:49 PM
In case it interests anyone, I managed to set up a demo of GRPO RL training in Colab. It’s an adaptation of Will Brown instant classic for math reasoning. Replace llama 1B with qwen 0.5b and inference with vllm. Full training in about 2 hours.
colab.research.google.com/drive/1bfhs1...
colab.research.google.com/drive/1bfhs1...
I don’t understand this eval. why compare their deep research model with gemini thinking, when gemini deep research exists

February 3, 2025 at 1:39 AM
I don’t understand this eval. why compare their deep research model with gemini thinking, when gemini deep research exists
at this point, gpt3 and claude sonnet/haiku could easily be open sourced
January 30, 2025 at 12:55 PM
at this point, gpt3 and claude sonnet/haiku could easily be open sourced
little disappointed seeing reactions of researchers from frontier labs on deepseek. science is not a zero sum game. we should really applaud the open weights, reproducibility, MIT license and detailed report which we hardly see in this decade. gracefulness besides the bias would’ve been nice
January 26, 2025 at 12:31 PM
little disappointed seeing reactions of researchers from frontier labs on deepseek. science is not a zero sum game. we should really applaud the open weights, reproducibility, MIT license and detailed report which we hardly see in this decade. gracefulness besides the bias would’ve been nice
The inference speed is amazing!

We’ve been thrilled by the positive reception to Gemini 2.0 Flash Thinking we discussed in December.
Today we’re sharing an experimental update w/improved performance on math, science, and multimodal reasoning benchmarks 📈:
• AIME: 73.3%
• GPQA: 74.2%
• MMMU: 75.4%
Today we’re sharing an experimental update w/improved performance on math, science, and multimodal reasoning benchmarks 📈:
• AIME: 73.3%
• GPQA: 74.2%
• MMMU: 75.4%
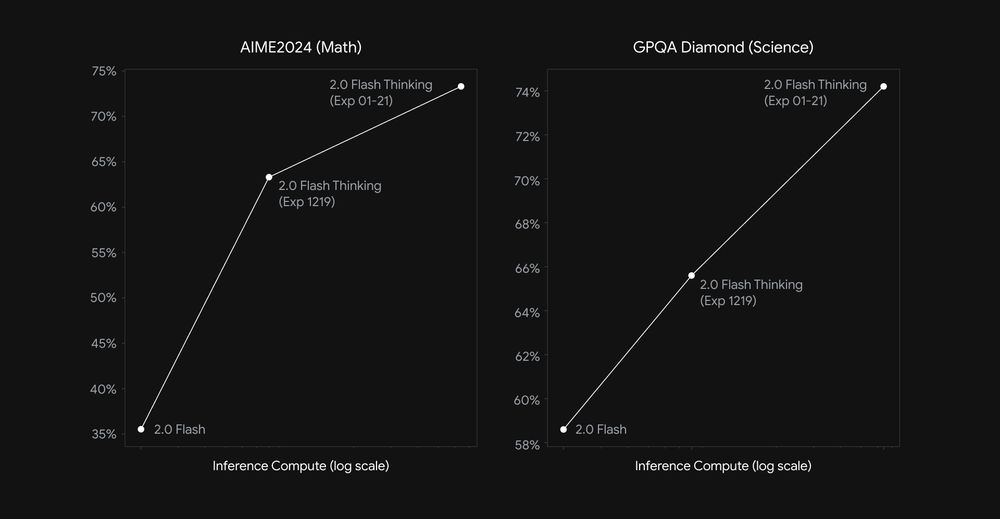
January 22, 2025 at 12:50 AM
The inference speed is amazing!
Just saw ScaleAI's front page ad on "America must win the AI war".
I'm afraid in the AI war only Palantir wins.
I'm afraid in the AI war only Palantir wins.
January 21, 2025 at 9:54 PM
Just saw ScaleAI's front page ad on "America must win the AI war".
I'm afraid in the AI war only Palantir wins.
I'm afraid in the AI war only Palantir wins.
internal search is very interesting, i hope the implementation is easy to read through

Super happy to reveal our new paper! 🎉🙌♟️
We trained a model to play four games, and the performance in each increases by "external search" (MCTS using a learned world model) and "internal search" where the model outputs the whole plan on its own!
We trained a model to play four games, and the performance in each increases by "external search" (MCTS using a learned world model) and "internal search" where the model outputs the whole plan on its own!
December 5, 2024 at 11:32 PM
internal search is very interesting, i hope the implementation is easy to read through
Reposted by Sayan

How do LLMs learn to reason from data? Are they ~retrieving the answers from parametric knowledge🦜? In our new preprint, we look at the pretraining data and find evidence against this:
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
November 20, 2024 at 4:35 PM
How do LLMs learn to reason from data? Are they ~retrieving the answers from parametric knowledge🦜? In our new preprint, we look at the pretraining data and find evidence against this:
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
Reposted by Sayan

The most realistic reason to be pro open source AI is to reduce concentration of power.

"money has flowed to tech giants and others in their orbit... [and] raises an uncomfortable prospect: that this supposedly revolutionary technology might never deliver on its promise of broad economic transformation, but instead just concentrate more wealth" www.bloomberg.com/opinion/arti...

ChatGPT’s $8 Trillion Birthday Gift to Big Tech
Two years in, generative AI’s value to the world is still unclear. But these charts show that it’s been a bonanza for the largest tech firms.
www.bloomberg.com
November 29, 2024 at 6:55 PM
The most realistic reason to be pro open source AI is to reduce concentration of power.
Most elaborate game of chinese whisper
November 28, 2024 at 2:44 AM
Most elaborate game of chinese whisper
I believe o1 will be replicated soon. First by meta and then a truly open source release with datasets and training recipe by @ai2.bsky.social team
November 27, 2024 at 4:30 AM
I believe o1 will be replicated soon. First by meta and then a truly open source release with datasets and training recipe by @ai2.bsky.social team
Outside tech, I see a lot of AI fear and hatred. Usually the argument is on AI taking jobs and creative tasks. I don't remember seeing this kind of general consensus of hatred and fear about a new technology before
November 27, 2024 at 2:21 AM
Outside tech, I see a lot of AI fear and hatred. Usually the argument is on AI taking jobs and creative tasks. I don't remember seeing this kind of general consensus of hatred and fear about a new technology before
Reposted by Sayan

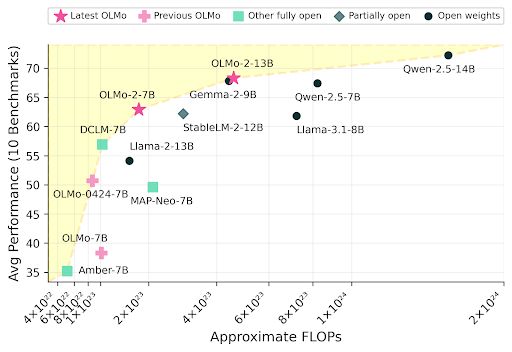
Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B — As always, we released our data, code, recipes and more 🎁
November 26, 2024 at 8:51 PM
Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B — As always, we released our data, code, recipes and more 🎁
Reposted by Sayan

i keep forgetting to include this cause i always assume people do this by default. Any time there is an exponent or a norm, you should be working in the highest practical precision

All softmaxes, also the output/vocab one. And the normalizations in f32 too.
November 24, 2024 at 8:05 PM
i keep forgetting to include this cause i always assume people do this by default. Any time there is an exponent or a norm, you should be working in the highest practical precision
Reposted by Sayan

Posting a call for help: does anyone know of a good way to simultaneously treat both POTS and Ménière’s disease? Please contact me if you’re either a clinician with experience doing this or a patient who has found a good solution. Context in thread
November 24, 2024 at 4:34 PM
Posting a call for help: does anyone know of a good way to simultaneously treat both POTS and Ménière’s disease? Please contact me if you’re either a clinician with experience doing this or a patient who has found a good solution. Context in thread
Reposted by Sayan

📢 Ultimate test of #NLP bluesky:
I need emergency reviewers for NAACL submissions on encoders (one multilingual, one for sentence embeddings). Help a desperate editor abandoned by the ACs! Author response starts tomorrow, so that's a true emergency.
If you're my hero, lmk your openreview profile.
I need emergency reviewers for NAACL submissions on encoders (one multilingual, one for sentence embeddings). Help a desperate editor abandoned by the ACs! Author response starts tomorrow, so that's a true emergency.
If you're my hero, lmk your openreview profile.
November 21, 2024 at 7:47 PM
📢 Ultimate test of #NLP bluesky:
I need emergency reviewers for NAACL submissions on encoders (one multilingual, one for sentence embeddings). Help a desperate editor abandoned by the ACs! Author response starts tomorrow, so that's a true emergency.
If you're my hero, lmk your openreview profile.
I need emergency reviewers for NAACL submissions on encoders (one multilingual, one for sentence embeddings). Help a desperate editor abandoned by the ACs! Author response starts tomorrow, so that's a true emergency.
If you're my hero, lmk your openreview profile.