




Shiry Ginosar
@shiryginosar.bsky.social
Assistant Professor @tticconnect.bsky.social
Understanding intelligence, one pixel at a time.
shiry.ttic.edu
Understanding intelligence, one pixel at a time.
shiry.ttic.edu
💫 I am recruiting exceptional PhD students & postdocs for my lab @tticconnect.bsky.social this year!
Application details: www.ttic.edu/studentappli...
Application details: www.ttic.edu/studentappli...

November 6, 2025 at 12:19 AM
💫 I am recruiting exceptional PhD students & postdocs for my lab @tticconnect.bsky.social this year!
Application details: www.ttic.edu/studentappli...
Application details: www.ttic.edu/studentappli...
TTIC is hiring tenure track faculty! Come join us in Chicago!
I am sadly not at ICCV but Greg Shakhnarovich (Vision) home.ttic.edu/~gregory/ and Matt Walter (Robotics) home.ttic.edu/~mwalter/ are around and would be happy to chat.
I am sadly not at ICCV but Greg Shakhnarovich (Vision) home.ttic.edu/~gregory/ and Matt Walter (Robotics) home.ttic.edu/~mwalter/ are around and would be happy to chat.

TTIC is hiring tenure-track faculty! Join a top #CS research environment with exceptional PhD students, strong research support, and a uniquely light teaching load. Apply by Dec 1: buff.ly/wv1sA0i
#CSJobs #FacultyHiring
#CSJobs #FacultyHiring

October 21, 2025 at 5:43 PM
TTIC is hiring tenure track faculty! Come join us in Chicago!
I am sadly not at ICCV but Greg Shakhnarovich (Vision) home.ttic.edu/~gregory/ and Matt Walter (Robotics) home.ttic.edu/~mwalter/ are around and would be happy to chat.
I am sadly not at ICCV but Greg Shakhnarovich (Vision) home.ttic.edu/~gregory/ and Matt Walter (Robotics) home.ttic.edu/~mwalter/ are around and would be happy to chat.
Guest track 2: Our one and only KiVA Challenge!!! kiva-challenge.github.io
Veo can (almost...) do it!!! can you?? video-zero-shot.github.io
With @euniceyiu.bsky.social, Anisa Noor Majhi, Maan Qraitem, Kate Saenko, @alisongopnik.bsky.social
Veo can (almost...) do it!!! can you?? video-zero-shot.github.io
With @euniceyiu.bsky.social, Anisa Noor Majhi, Maan Qraitem, Kate Saenko, @alisongopnik.bsky.social
KiVA Challenge @ ICCV 2025
kiva-challenge.github.io
October 20, 2025 at 12:07 AM
Join us TODAY for the 3rd Perception Test Challenge perception-test-challenge.github.io @iccv.bsky.social
Ballroom B, Full day
Amazing lineup of speakers: Ali Farhadi, @alisongopnik.bsky.social, Phlipp Krahenbul, @phillipisola.bsky.social
Ballroom B, Full day
Amazing lineup of speakers: Ali Farhadi, @alisongopnik.bsky.social, Phlipp Krahenbul, @phillipisola.bsky.social
October 19, 2025 at 6:14 PM
Join us TODAY for the 3rd Perception Test Challenge perception-test-challenge.github.io @iccv.bsky.social
Ballroom B, Full day
Amazing lineup of speakers: Ali Farhadi, @alisongopnik.bsky.social, Phlipp Krahenbul, @phillipisola.bsky.social
Ballroom B, Full day
Amazing lineup of speakers: Ali Farhadi, @alisongopnik.bsky.social, Phlipp Krahenbul, @phillipisola.bsky.social
TODAY! Artificial Social Intelligence Workshop @iccv.bsky.social
Room 317B, Full day
Social reasoning, multimodality, and embodiment!
Speakers: Evonne Ng, @tianminshu.bsky.social @hyunwoo-kim.bsky.social, @diyiyang.bsky.social ang.bsky.social, @hokulabs.bsky.social, @michael-j-black.bsky.social
Room 317B, Full day
Social reasoning, multimodality, and embodiment!
Speakers: Evonne Ng, @tianminshu.bsky.social @hyunwoo-kim.bsky.social, @diyiyang.bsky.social ang.bsky.social, @hokulabs.bsky.social, @michael-j-black.bsky.social

October 19, 2025 at 4:58 PM
TODAY! Artificial Social Intelligence Workshop @iccv.bsky.social
Room 317B, Full day
Social reasoning, multimodality, and embodiment!
Speakers: Evonne Ng, @tianminshu.bsky.social @hyunwoo-kim.bsky.social, @diyiyang.bsky.social ang.bsky.social, @hokulabs.bsky.social, @michael-j-black.bsky.social
Room 317B, Full day
Social reasoning, multimodality, and embodiment!
Speakers: Evonne Ng, @tianminshu.bsky.social @hyunwoo-kim.bsky.social, @diyiyang.bsky.social ang.bsky.social, @hokulabs.bsky.social, @michael-j-black.bsky.social
KiVA (Kid-inspired Visual Analogies) Challenge Test Phase is NOW LIVE (Sep 1–Oct 6)!
Can your model reason like a child? Can it beat adults?
🥇 $1,000
🥈 $500 for 2 runner-ups
Join/submit: t.co/zQwA1Nmohy
And join us at @iccv.bsky.social in Hawaii!! 🌴
Can your model reason like a child? Can it beat adults?
🥇 $1,000
🥈 $500 for 2 runner-ups
Join/submit: t.co/zQwA1Nmohy
And join us at @iccv.bsky.social in Hawaii!! 🌴

September 3, 2025 at 5:34 PM
KiVA (Kid-inspired Visual Analogies) Challenge Test Phase is NOW LIVE (Sep 1–Oct 6)!
Can your model reason like a child? Can it beat adults?
🥇 $1,000
🥈 $500 for 2 runner-ups
Join/submit: t.co/zQwA1Nmohy
And join us at @iccv.bsky.social in Hawaii!! 🌴
Can your model reason like a child? Can it beat adults?
🥇 $1,000
🥈 $500 for 2 runner-ups
Join/submit: t.co/zQwA1Nmohy
And join us at @iccv.bsky.social in Hawaii!! 🌴
I am giving a talk this morning at 10:40AM PST as part of the #ICML2025 Workshop on Assessing World Models.
Title: "What Do Vision and Vision-Language Models Really Know About the World?"
Come join us!
www.worldmodelworkshop.org
Title: "What Do Vision and Vision-Language Models Really Know About the World?"
Come join us!
www.worldmodelworkshop.org

ICML Workshop on Assessing World Models
Date: Friday, July 18 2025
Time: 8:45am - 5:15pm (Pacific Time)
Location: West Ballroom B at ICML 2025 in Vancouver, Canada (Same Floor as Registration)
www.worldmodelworkshop.org
July 18, 2025 at 3:08 PM
I am giving a talk this morning at 10:40AM PST as part of the #ICML2025 Workshop on Assessing World Models.
Title: "What Do Vision and Vision-Language Models Really Know About the World?"
Come join us!
www.worldmodelworkshop.org
Title: "What Do Vision and Vision-Language Models Really Know About the World?"
Come join us!
www.worldmodelworkshop.org
Reposted by Shiry Ginosar

Join us for 3rd Perception Test Workshop &Challenge
@iccv.bsky.social #iccv2025
*NEW* this year:
- 3 unified tracks
- novel interpretability track
- guest tracks: KiVA and Physics-IQ
- 4 world-class speakers (see pic)
Up to 50K in prizes sponsored by Google DeepMind
🧵 for details [1/4]
@iccv.bsky.social #iccv2025
*NEW* this year:
- 3 unified tracks
- novel interpretability track
- guest tracks: KiVA and Physics-IQ
- 4 world-class speakers (see pic)
Up to 50K in prizes sponsored by Google DeepMind
🧵 for details [1/4]

July 16, 2025 at 12:40 PM
Join us for 3rd Perception Test Workshop &Challenge
@iccv.bsky.social #iccv2025
*NEW* this year:
- 3 unified tracks
- novel interpretability track
- guest tracks: KiVA and Physics-IQ
- 4 world-class speakers (see pic)
Up to 50K in prizes sponsored by Google DeepMind
🧵 for details [1/4]
@iccv.bsky.social #iccv2025
*NEW* this year:
- 3 unified tracks
- novel interpretability track
- guest tracks: KiVA and Physics-IQ
- 4 world-class speakers (see pic)
Up to 50K in prizes sponsored by Google DeepMind
🧵 for details [1/4]
🧠How “old” is your model?
Put it to the test with the KiVA Challenge: a new benchmark for abstract visual reasoning, grounded in real developmental data from children and adults.
🏆 Prizes:
🥇$1K to the top model
🥈🥉$500
📅 Deadline: 10/7/25
🔗 kiva-challenge.github.io
@iccv.bsky.social
Put it to the test with the KiVA Challenge: a new benchmark for abstract visual reasoning, grounded in real developmental data from children and adults.
🏆 Prizes:
🥇$1K to the top model
🥈🥉$500
📅 Deadline: 10/7/25
🔗 kiva-challenge.github.io
@iccv.bsky.social
KiVA Challenge @ ICCV 2025
kiva-challenge.github.io
July 15, 2025 at 7:19 PM
🧠How “old” is your model?
Put it to the test with the KiVA Challenge: a new benchmark for abstract visual reasoning, grounded in real developmental data from children and adults.
🏆 Prizes:
🥇$1K to the top model
🥈🥉$500
📅 Deadline: 10/7/25
🔗 kiva-challenge.github.io
@iccv.bsky.social
Put it to the test with the KiVA Challenge: a new benchmark for abstract visual reasoning, grounded in real developmental data from children and adults.
🏆 Prizes:
🥇$1K to the top model
🥈🥉$500
📅 Deadline: 10/7/25
🔗 kiva-challenge.github.io
@iccv.bsky.social
When it comes to goal-directed work, people prioritize controllable variability (a.k.a. empowerment!).
But in undirected play, we shift toward embracing pure variability.
Check out our forthcoming Phil. Trans. A (2026) paper!
But in undirected play, we shift toward embracing pure variability.
Check out our forthcoming Phil. Trans. A (2026) paper!

June 25, 2025 at 10:35 PM
When it comes to goal-directed work, people prioritize controllable variability (a.k.a. empowerment!).
But in undirected play, we shift toward embracing pure variability.
Check out our forthcoming Phil. Trans. A (2026) paper!
But in undirected play, we shift toward embracing pure variability.
Check out our forthcoming Phil. Trans. A (2026) paper!
Reposted by Shiry Ginosar

Check out our new paper at #ICLR2025, where we show that multi-task neural decoding is both possible and beneficial.
As well, the latents of a model trained only on neural activity capture information about brain regions and cell-types.
Step-by-step, we're gonna scale up folks!
🧠📈 🧪 #NeuroAI
As well, the latents of a model trained only on neural activity capture information about brain regions and cell-types.
Step-by-step, we're gonna scale up folks!
🧠📈 🧪 #NeuroAI

Scaling models across multiple animals was a major step toward building neuro-foundation models; the next frontier is enabling multi-task decoding to expand the scope of training data we can leverage.
Excited to share our #ICLR2025 Spotlight paper introducing POYO+ 🧠
poyo-plus.github.io
🧵
Excited to share our #ICLR2025 Spotlight paper introducing POYO+ 🧠
poyo-plus.github.io
🧵
POYO+
POYO+: Multi-session, multi-task neural decoding from distinct cell-types and brain regions
poyo-plus.github.io
April 25, 2025 at 10:21 PM
Reposted by Shiry Ginosar

🎧 Listen to the podcast!
Professor @alisongopnik.bsky.social and @newamerica.org CEO @slaughteram.bsky.social spoke with @alexis-madrigal.bsky.social about how rethinking our approach to caregiving and how we support care providers could lead to a better society.
🔗:
Professor @alisongopnik.bsky.social and @newamerica.org CEO @slaughteram.bsky.social spoke with @alexis-madrigal.bsky.social about how rethinking our approach to caregiving and how we support care providers could lead to a better society.
🔗:

Alison Gopnik and Anne-Marie Slaughter on Why We’re Not Paying Enough Attention to Caregiving
KQED's Forum · Episode
buff.ly
April 26, 2025 at 12:00 AM
🎧 Listen to the podcast!
Professor @alisongopnik.bsky.social and @newamerica.org CEO @slaughteram.bsky.social spoke with @alexis-madrigal.bsky.social about how rethinking our approach to caregiving and how we support care providers could lead to a better society.
🔗:
Professor @alisongopnik.bsky.social and @newamerica.org CEO @slaughteram.bsky.social spoke with @alexis-madrigal.bsky.social about how rethinking our approach to caregiving and how we support care providers could lead to a better society.
🔗:
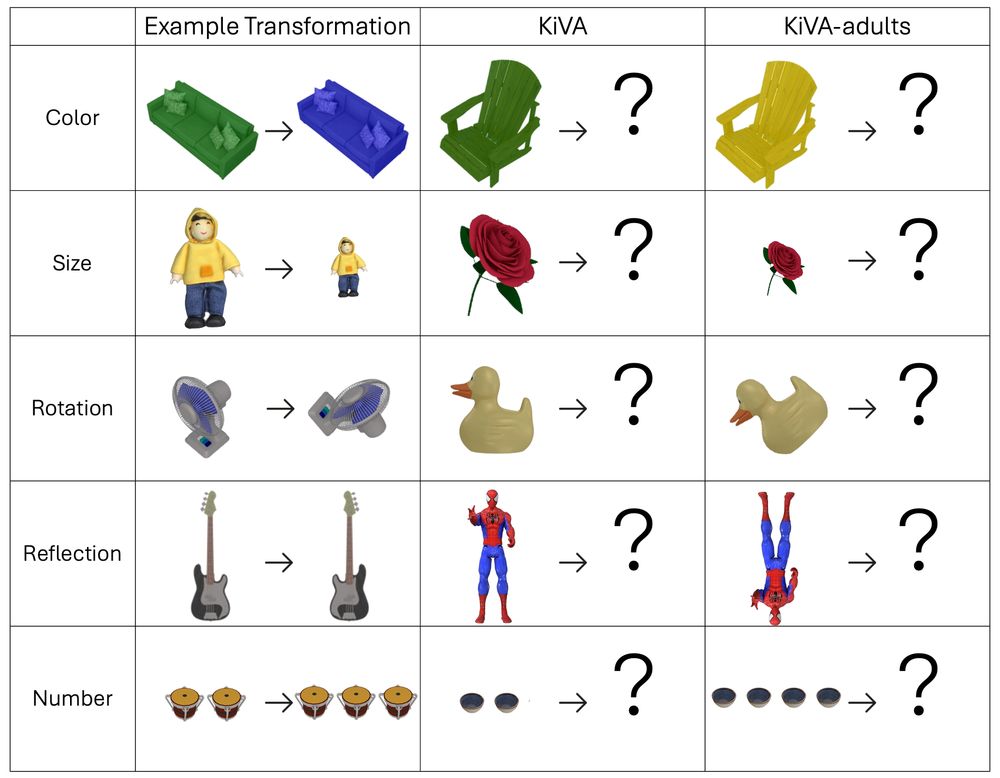
Think LMMs can reason like a 3-year-old?
Think again!
Our Kid-Inspired Visual Analogies benchmark reveals where young children still win: ey242.github.io/kiva.github....
Catch our #ICLR2025 poster today to see where models still fall short!
Thurs. April 24
3-5:30 pm
Halls 3 + 2B #312
Think again!
Our Kid-Inspired Visual Analogies benchmark reveals where young children still win: ey242.github.io/kiva.github....
Catch our #ICLR2025 poster today to see where models still fall short!
Thurs. April 24
3-5:30 pm
Halls 3 + 2B #312
April 23, 2025 at 10:58 PM
Think LMMs can reason like a 3-year-old?
Think again!
Our Kid-Inspired Visual Analogies benchmark reveals where young children still win: ey242.github.io/kiva.github....
Catch our #ICLR2025 poster today to see where models still fall short!
Thurs. April 24
3-5:30 pm
Halls 3 + 2B #312
Think again!
Our Kid-Inspired Visual Analogies benchmark reveals where young children still win: ey242.github.io/kiva.github....
Catch our #ICLR2025 poster today to see where models still fall short!
Thurs. April 24
3-5:30 pm
Halls 3 + 2B #312
Neuroscience is finally taking more and more baby steps towards running experiments at scale!

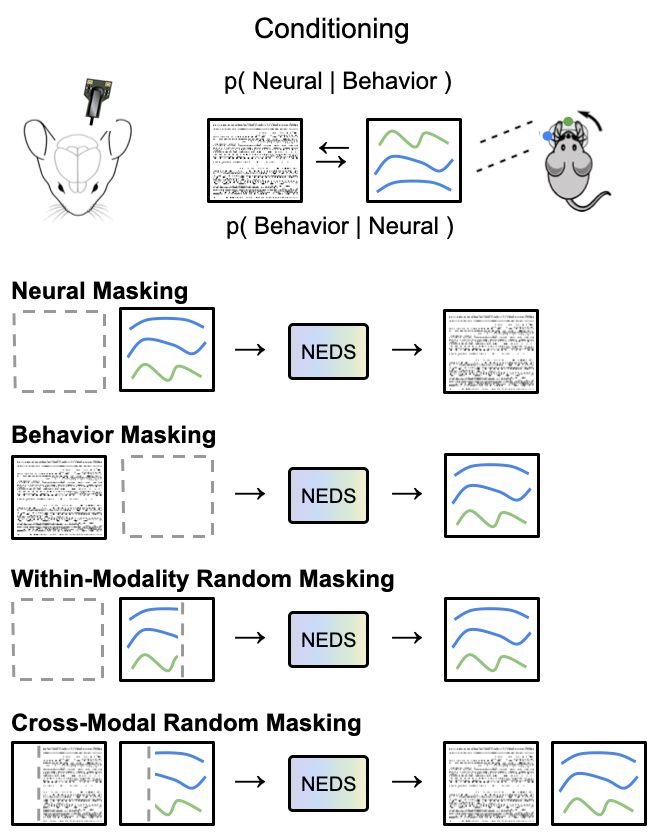
Another step toward a foundation model of the mouse brain: "Neural Encoding and Decoding at Scale (NEDS)"
Trained on neural and behavioral data from 70+ mice, NEDS achieves state-of-the-art prediction of behavior (decoding) and neural responses (encoding) on held-out animals. 🐀
Trained on neural and behavioral data from 70+ mice, NEDS achieves state-of-the-art prediction of behavior (decoding) and neural responses (encoding) on held-out animals. 🐀
April 16, 2025 at 2:40 AM
Neuroscience is finally taking more and more baby steps towards running experiments at scale!
Reposted by Shiry Ginosar

In his new book, published today, Nachum Ulanovsky calls on the field to embrace naturalistic conditions and move away from overcontrolled experiments.
#neuroskyence
www.thetransmitter.org/systems-neur...
#neuroskyence
www.thetransmitter.org/systems-neur...

‘Natural Neuroscience,’ an excerpt
In his new book, Nachum Ulanovsky calls on the field to embrace naturalistic conditions and move away from overcontrolled experiments.
www.thetransmitter.org
April 15, 2025 at 1:11 PM
In his new book, published today, Nachum Ulanovsky calls on the field to embrace naturalistic conditions and move away from overcontrolled experiments.
#neuroskyence
www.thetransmitter.org/systems-neur...
#neuroskyence
www.thetransmitter.org/systems-neur...
Welcome to TTIC!! We are so excited to have you join us!!

Writing my first post here to announce that I've accepted an assistant professor job at TTIC! I'll be starting in Fall 2026, and recruiting students this upcoming cycle.
Until then, I'll be wrapping up the PhD at Berkeley, and this summer I'll join NYU as a CDS Faculty Fellow 🏙️
Until then, I'll be wrapping up the PhD at Berkeley, and this summer I'll join NYU as a CDS Faculty Fellow 🏙️
April 15, 2025 at 7:05 PM
Welcome to TTIC!! We are so excited to have you join us!!
Reposted by Shiry Ginosar

We're very excited to introduce TAPNext: a model that sets a new state-of-art for Tracking Any Point in videos, by formulating the task as Next Token Prediction. For more, see: tap-next.github.io
April 9, 2025 at 2:04 PM
We're very excited to introduce TAPNext: a model that sets a new state-of-art for Tracking Any Point in videos, by formulating the task as Next Token Prediction. For more, see: tap-next.github.io
This shows the importance of expressive (rather than functional) gesture really nicely in a beautiful non-anthropomorphic robot design
machinelearning.apple.com/research/ele...
machinelearning.apple.com/research/ele...

ELEGNT: Expressive and Functional Movement Design for Non-Anthropomorphic Robot
Nonverbal behaviors such as posture, gestures, and gaze are essential for conveying internal states, both consciously and unconsciously, in…
machinelearning.apple.com
February 6, 2025 at 4:26 PM
This shows the importance of expressive (rather than functional) gesture really nicely in a beautiful non-anthropomorphic robot design
machinelearning.apple.com/research/ele...
machinelearning.apple.com/research/ele...
Reposted by Shiry Ginosar

Did Italo Calvino discover bag of words and topic models in 1979?


February 6, 2025 at 1:00 AM
Did Italo Calvino discover bag of words and topic models in 1979?
Reposted by Shiry Ginosar

"That's what the people promulgating these horrible policies want - a bored, indifferent public who figures that who cares, nothing matters any more, it's gonna happen no matter what. But it doesn't have to. Never forget that: it doesn't have to happen."
www.science.org/content/blog...
www.science.org/content/blog...

What's Happening Inside the NIH and NSF
www.science.org
February 5, 2025 at 4:37 AM
"That's what the people promulgating these horrible policies want - a bored, indifferent public who figures that who cares, nothing matters any more, it's gonna happen no matter what. But it doesn't have to. Never forget that: it doesn't have to happen."
www.science.org/content/blog...
www.science.org/content/blog...
Reposted by Shiry Ginosar

Why does Western paleolithic cave art strongly prefer animal side views and often abbreviations? Our new #eSymb preprint (osf.io/preprints/ps... w Pagnotta, Psujek, Mendoza Straffon and Tylén ) challenges long-held assumptions about these artistic choices based on cogsci experiments. 1/

January 19, 2025 at 6:40 PM
Why does Western paleolithic cave art strongly prefer animal side views and often abbreviations? Our new #eSymb preprint (osf.io/preprints/ps... w Pagnotta, Psujek, Mendoza Straffon and Tylén ) challenges long-held assumptions about these artistic choices based on cogsci experiments. 1/
New paper! A self-supervised object-centric 2.1D image representation using 3D Gaussians, extending MAE with a Gaussian bottleneck. While Gaussian splatting has been used for single-scene reconstruction, we’re the first to apply it to image representation learning! brjathu.github.io/gmae/.

January 9, 2025 at 9:39 PM
New paper! A self-supervised object-centric 2.1D image representation using 3D Gaussians, extending MAE with a Gaussian bottleneck. While Gaussian splatting has been used for single-scene reconstruction, we’re the first to apply it to image representation learning! brjathu.github.io/gmae/.
Can video MAE scale? Yes.
Do you need language to scale video models? No.
arxiv.org/abs/2412.15212
Great rigorous benchmarking from my colleagues at Google DeepMind.
Do you need language to scale video models? No.
arxiv.org/abs/2412.15212
Great rigorous benchmarking from my colleagues at Google DeepMind.

Scaling 4D Representations
Scaling has not yet been convincingly demonstrated for pure self-supervised learning from video. However, prior work has focused evaluations on semantic-related tasks $\unicode{x2013}$ action classifi...
arxiv.org
December 20, 2024 at 10:36 PM
Can video MAE scale? Yes.
Do you need language to scale video models? No.
arxiv.org/abs/2412.15212
Great rigorous benchmarking from my colleagues at Google DeepMind.
Do you need language to scale video models? No.
arxiv.org/abs/2412.15212
Great rigorous benchmarking from my colleagues at Google DeepMind.
This is a fantastic example of just how different machine's perception of perception still is from human perception...

thinking of calling this "The Illusion Illusion"
(more examples below)
(more examples below)

December 2, 2024 at 7:34 PM
This is a fantastic example of just how different machine's perception of perception still is from human perception...
Advice for beginning grad students:
The Secret of Happiness Story [Sufi, Turkey].
Nasrudin is known as much for his wisdom as his foolishness, and many are those who have sought out his teaching. One devotee tracked him down in the marketplace.
1/3
The Secret of Happiness Story [Sufi, Turkey].
Nasrudin is known as much for his wisdom as his foolishness, and many are those who have sought out his teaching. One devotee tracked him down in the marketplace.
1/3
November 22, 2024 at 7:15 PM
Advice for beginning grad students:
The Secret of Happiness Story [Sufi, Turkey].
Nasrudin is known as much for his wisdom as his foolishness, and many are those who have sought out his teaching. One devotee tracked him down in the marketplace.
1/3
The Secret of Happiness Story [Sufi, Turkey].
Nasrudin is known as much for his wisdom as his foolishness, and many are those who have sought out his teaching. One devotee tracked him down in the marketplace.
1/3