




Joan Serrà
@serrjoa.bsky.social
Does research on machine learning at Sony AI, Barcelona. Works on audio analysis, synthesis, and retrieval. Likes tennis, music, and wine.
https://serrjoa.github.io/
https://serrjoa.github.io/
Pinned
Joan Serrà
@serrjoa.bsky.social
· Jan 8
I think I may switch back to Twitter/X. Somehow I feel this site didn't take off and I really don't want to be looking at two feeds all the time...
I think I may switch back to Twitter/X. Somehow I feel this site didn't take off and I really don't want to be looking at two feeds all the time...
January 8, 2025 at 6:33 PM
I think I may switch back to Twitter/X. Somehow I feel this site didn't take off and I really don't want to be looking at two feeds all the time...
Reposted by Joan Serrà

Image matching and ChatGPT - new post in the wide baseline stereo blog.
tl;dr: it is good, even feels like human, but not perfect.
ducha-aiki.github.io/wide-baselin...
tl;dr: it is good, even feels like human, but not perfect.
ducha-aiki.github.io/wide-baselin...
ChatGPT and Image Matching – Wide baseline stereo meets deep learning
Are we done yet?
ducha-aiki.github.io
January 2, 2025 at 9:01 PM
Image matching and ChatGPT - new post in the wide baseline stereo blog.
tl;dr: it is good, even feels like human, but not perfect.
ducha-aiki.github.io/wide-baselin...
tl;dr: it is good, even feels like human, but not perfect.
ducha-aiki.github.io/wide-baselin...
Reposted by Joan Serrà

Many of the greatest papers, now canonical works, have a story of resistance, tension, and, finally, a crucial advocate. It's shockingly common. Why is there a bias against excellence? And what happens to those papers, those people, when no one has the courage to advocate?
December 28, 2024 at 11:42 PM
Many of the greatest papers, now canonical works, have a story of resistance, tension, and, finally, a crucial advocate. It's shockingly common. Why is there a bias against excellence? And what happens to those papers, those people, when no one has the courage to advocate?
Do you want to work with me for some months? Two internship positions available at the Music Team of Sony AI in Barcelona!
👇
👇

December 23, 2024 at 8:13 AM
Do you want to work with me for some months? Two internship positions available at the Music Team of Sony AI in Barcelona!
👇
👇
I'm happy to have two papers accepted at #ICASSP2025!
1) Contrastive learning for audio-video sequences, exploiting the fact that they are *sequences*: arxiv.org/abs/2407.05782
2) Knowledge distillation at *pre-training* time to help generative speech enhancement: arxiv.org/abs/2409.09357
1) Contrastive learning for audio-video sequences, exploiting the fact that they are *sequences*: arxiv.org/abs/2407.05782
2) Knowledge distillation at *pre-training* time to help generative speech enhancement: arxiv.org/abs/2409.09357
December 21, 2024 at 8:29 AM
I'm happy to have two papers accepted at #ICASSP2025!
1) Contrastive learning for audio-video sequences, exploiting the fact that they are *sequences*: arxiv.org/abs/2407.05782
2) Knowledge distillation at *pre-training* time to help generative speech enhancement: arxiv.org/abs/2409.09357
1) Contrastive learning for audio-video sequences, exploiting the fact that they are *sequences*: arxiv.org/abs/2407.05782
2) Knowledge distillation at *pre-training* time to help generative speech enhancement: arxiv.org/abs/2409.09357
Flow matching mapping text to image directly (instead of noise to image): cross-flow.github.io
December 20, 2024 at 6:29 PM
Flow matching mapping text to image directly (instead of noise to image): cross-flow.github.io
Reposted by Joan Serrà

With some delay, JetFormer's *prequel* paper is finally out on arXiv: a radically simple ViT-based normalizing flow (NF) model that achieves SOTA results in its class.
Jet is one of the key components of JetFormer, deserving a standalone report. Let's unpack: 🧵⬇️
Jet is one of the key components of JetFormer, deserving a standalone report. Let's unpack: 🧵⬇️

December 20, 2024 at 2:39 PM
With some delay, JetFormer's *prequel* paper is finally out on arXiv: a radically simple ViT-based normalizing flow (NF) model that achieves SOTA results in its class.
Jet is one of the key components of JetFormer, deserving a standalone report. Let's unpack: 🧵⬇️
Jet is one of the key components of JetFormer, deserving a standalone report. Let's unpack: 🧵⬇️
Reposted by Joan Serrà

Did you miss any of the talks of the Deep Learning Barcelona Symposyum 2024 ? Play them now from the recorded stream:
www.youtube.com/live/yPc-Un3...
www.youtube.com/live/yPc-Un3...
YouTube
Share your videos with friends, family, and the world
www.youtube.com
December 19, 2024 at 11:32 PM
Did you miss any of the talks of the Deep Learning Barcelona Symposyum 2024 ? Play them now from the recorded stream:
www.youtube.com/live/yPc-Un3...
www.youtube.com/live/yPc-Un3...
Reposted by Joan Serrà

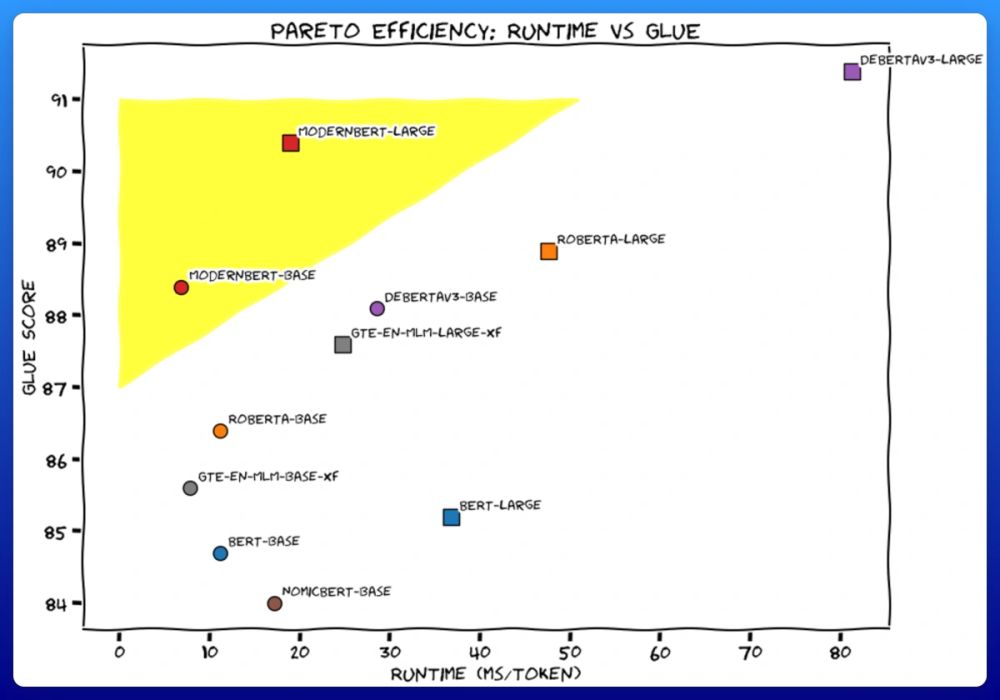
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
December 19, 2024 at 4:45 PM
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
On pre-acrivation norm, learnable residuals, etc.

A post by @cloneofsimo on Twitter made me write up some lore about residuals, ResNets, and Transformers. And I couldn't resist sliding in the usual cautionary tale about small/mid-scale != large-scale.
Blogpost: lb.eyer.be/s/residuals....
Blogpost: lb.eyer.be/s/residuals....
December 19, 2024 at 6:34 AM
On pre-acrivation norm, learnable residuals, etc.
Reposted by Joan Serrà

Two great tokenizer blog posts that helped me over the years: sjmielke.com/papers/token...
sjmielke.com/comparing-pe...
People have mostly standardized on certain tokenizations right now, but there are huge performance gaps between locales with high agglomeration (e.g. common en-us) and ...
sjmielke.com/comparing-pe...
People have mostly standardized on certain tokenizations right now, but there are huge performance gaps between locales with high agglomeration (e.g. common en-us) and ...
December 18, 2024 at 1:39 PM
Two great tokenizer blog posts that helped me over the years: sjmielke.com/papers/token...
sjmielke.com/comparing-pe...
People have mostly standardized on certain tokenizations right now, but there are huge performance gaps between locales with high agglomeration (e.g. common en-us) and ...
sjmielke.com/comparing-pe...
People have mostly standardized on certain tokenizations right now, but there are huge performance gaps between locales with high agglomeration (e.g. common en-us) and ...
Don't be like Reviewer 2.
December 15, 2024 at 8:17 AM
Don't be like Reviewer 2.
Reposted by Joan Serrà

Did Gauss invent the Gaussian?
- Laplace wrote down the integral first in 1783
- Gauss then described it in 1809 in the context of least-sq. for astronomical measurements
- Pearson & Fisher framed it as ‘normal’ density only in 1910
* Best part is: Gauss gave Laplace credit!
- Laplace wrote down the integral first in 1783
- Gauss then described it in 1809 in the context of least-sq. for astronomical measurements
- Pearson & Fisher framed it as ‘normal’ density only in 1910
* Best part is: Gauss gave Laplace credit!

December 14, 2024 at 6:22 AM
Did Gauss invent the Gaussian?
- Laplace wrote down the integral first in 1783
- Gauss then described it in 1809 in the context of least-sq. for astronomical measurements
- Pearson & Fisher framed it as ‘normal’ density only in 1910
* Best part is: Gauss gave Laplace credit!
- Laplace wrote down the integral first in 1783
- Gauss then described it in 1809 in the context of least-sq. for astronomical measurements
- Pearson & Fisher framed it as ‘normal’ density only in 1910
* Best part is: Gauss gave Laplace credit!
I already signed up (as a mentor) for this year!
Call for mentees and mentors open until December 16.
Sign up as a mentee if you are a student or in the early stages of your career.
Sign up as a mentor to help in the career growth of a member of the #DLBCN community.
Details and registration:
sites.google.com/view/dlbcn20...
Sign up as a mentee if you are a student or in the early stages of your career.
Sign up as a mentor to help in the career growth of a member of the #DLBCN community.
Details and registration:
sites.google.com/view/dlbcn20...

December 13, 2024 at 2:01 PM
I already signed up (as a mentor) for this year!
Reposted by Joan Serrà

Thrilled to present our work on Constrained Parameter Regularization (CPR) at #NeurIPS2024!
Our novel deep learning regularization outperforms weight decay across various tasks. neurips.cc/virtual/2024...
This is joint work with Michael Hefenbrock, Gregor Köhler, and Frank Hutter
🧵👇
Our novel deep learning regularization outperforms weight decay across various tasks. neurips.cc/virtual/2024...
This is joint work with Michael Hefenbrock, Gregor Köhler, and Frank Hutter
🧵👇
NeurIPS Poster Improving Deep Learning Optimization through Constrained Parameter RegularizationNeurIPS 2024
neurips.cc
December 9, 2024 at 3:28 PM
Thrilled to present our work on Constrained Parameter Regularization (CPR) at #NeurIPS2024!
Our novel deep learning regularization outperforms weight decay across various tasks. neurips.cc/virtual/2024...
This is joint work with Michael Hefenbrock, Gregor Köhler, and Frank Hutter
🧵👇
Our novel deep learning regularization outperforms weight decay across various tasks. neurips.cc/virtual/2024...
This is joint work with Michael Hefenbrock, Gregor Köhler, and Frank Hutter
🧵👇
Reposted by Joan Serrà

Entropy is one of those formulas that many of us learn, swallow whole, and even use regularly without really understanding.
(E.g., where does that “log” come from? Are there other possible formulas?)
Yet there's an intuitive & almost inevitable way to arrive at this expression.
(E.g., where does that “log” come from? Are there other possible formulas?)
Yet there's an intuitive & almost inevitable way to arrive at this expression.
December 9, 2024 at 10:44 PM
Entropy is one of those formulas that many of us learn, swallow whole, and even use regularly without really understanding.
(E.g., where does that “log” come from? Are there other possible formulas?)
Yet there's an intuitive & almost inevitable way to arrive at this expression.
(E.g., where does that “log” come from? Are there other possible formulas?)
Yet there's an intuitive & almost inevitable way to arrive at this expression.
Reposted by Joan Serrà

Inventors of flow matching have released a comprehensive guide going over the math & code of flow matching!
Also covers variants like non-Euclidean & discrete flow matching.
A PyTorch library is also released with this guide!
This looks like a very good read! 🔥
arxiv: arxiv.org/abs/2412.06264
Also covers variants like non-Euclidean & discrete flow matching.
A PyTorch library is also released with this guide!
This looks like a very good read! 🔥
arxiv: arxiv.org/abs/2412.06264

December 10, 2024 at 8:35 AM
Inventors of flow matching have released a comprehensive guide going over the math & code of flow matching!
Also covers variants like non-Euclidean & discrete flow matching.
A PyTorch library is also released with this guide!
This looks like a very good read! 🔥
arxiv: arxiv.org/abs/2412.06264
Also covers variants like non-Euclidean & discrete flow matching.
A PyTorch library is also released with this guide!
This looks like a very good read! 🔥
arxiv: arxiv.org/abs/2412.06264
Reposted by Joan Serrà
Normalizing Flows are Capable Generative Models
Apple introduces TarFlow, a new Transformer-based variant of Masked Autoregressive Flows.
SOTA on likelihood estimation for images, quality and diversity comparable to diffusion models.
arxiv.org/abs/2412.06329
Apple introduces TarFlow, a new Transformer-based variant of Masked Autoregressive Flows.
SOTA on likelihood estimation for images, quality and diversity comparable to diffusion models.
arxiv.org/abs/2412.06329

Normalizing Flows are Capable Generative Models
Normalizing Flows (NFs) are likelihood-based models for continuous inputs.
They have demonstrated promising results on both density estimation and generative modeling tasks, but have received relati...
arxiv.org
December 10, 2024 at 8:06 AM
Normalizing Flows are Capable Generative Models
Apple introduces TarFlow, a new Transformer-based variant of Masked Autoregressive Flows.
SOTA on likelihood estimation for images, quality and diversity comparable to diffusion models.
arxiv.org/abs/2412.06329
Apple introduces TarFlow, a new Transformer-based variant of Masked Autoregressive Flows.
SOTA on likelihood estimation for images, quality and diversity comparable to diffusion models.
arxiv.org/abs/2412.06329
Reposted by Joan Serrà
That was fast: #DLBCN 2024 was sold out in less than two hours !
New requests will be added to a waiting list. Read the instructions for same day event registration:
sites.google.com/view/dlbcn20...
New requests will be added to a waiting list. Read the instructions for same day event registration:
sites.google.com/view/dlbcn20...

December 9, 2024 at 9:08 AM
That was fast: #DLBCN 2024 was sold out in less than two hours !
New requests will be added to a waiting list. Read the instructions for same day event registration:
sites.google.com/view/dlbcn20...
New requests will be added to a waiting list. Read the instructions for same day event registration:
sites.google.com/view/dlbcn20...
Reposted by Joan Serrà

Past work has characterized the functions learned by neural networks: arxiv.org/pdf/1910.01635, arxiv.org/abs/1902.05040, arxiv.org/abs/2109.12960, arxiv.org/abs/2105.03361. But it turns out multi-task training produces strikingly different solutions! Adding tasks produces “kernel-like” solutions.

December 7, 2024 at 9:49 PM
Past work has characterized the functions learned by neural networks: arxiv.org/pdf/1910.01635, arxiv.org/abs/1902.05040, arxiv.org/abs/2109.12960, arxiv.org/abs/2105.03361. But it turns out multi-task training produces strikingly different solutions! Adding tasks produces “kernel-like” solutions.
Reposted by Joan Serrà

Can language models transcend the limitations of training data?
We train LMs on a formal grammar, then prompt them OUTSIDE of this grammar. We find that LMs often extrapolate logical rules and apply them OOD, too. Proof of a useful inductive bias.
Check it out at NeurIPS:
nips.cc/virtual/2024...
We train LMs on a formal grammar, then prompt them OUTSIDE of this grammar. We find that LMs often extrapolate logical rules and apply them OOD, too. Proof of a useful inductive bias.
Check it out at NeurIPS:
nips.cc/virtual/2024...
NeurIPS Poster Rule Extrapolation in Language Modeling: A Study of Compositional Generalization on OOD PromptsNeurIPS 2024
nips.cc
December 6, 2024 at 1:31 PM
Can language models transcend the limitations of training data?
We train LMs on a formal grammar, then prompt them OUTSIDE of this grammar. We find that LMs often extrapolate logical rules and apply them OOD, too. Proof of a useful inductive bias.
Check it out at NeurIPS:
nips.cc/virtual/2024...
We train LMs on a formal grammar, then prompt them OUTSIDE of this grammar. We find that LMs often extrapolate logical rules and apply them OOD, too. Proof of a useful inductive bias.
Check it out at NeurIPS:
nips.cc/virtual/2024...
Reposted by Joan Serrà

"We therefore recommend to consider logistic regression as the first choice for data-scarce applications with tabular data and provide practitioners with best practices for further method selection."
arxiv.org/abs/2405.07662
arxiv.org/abs/2405.07662

Squeezing Lemons with Hammers: An Evaluation of AutoML and Tabular Deep Learning for Data-Scarce Classification Applications
Many industry verticals are confronted with small-sized tabular data. In this low-data regime, it is currently unclear whether the best performance can be expected from simple baselines, or more compl...
arxiv.org
December 6, 2024 at 6:24 AM
"We therefore recommend to consider logistic regression as the first choice for data-scarce applications with tabular data and provide practitioners with best practices for further method selection."
arxiv.org/abs/2405.07662
arxiv.org/abs/2405.07662
Reposted by Joan Serrà

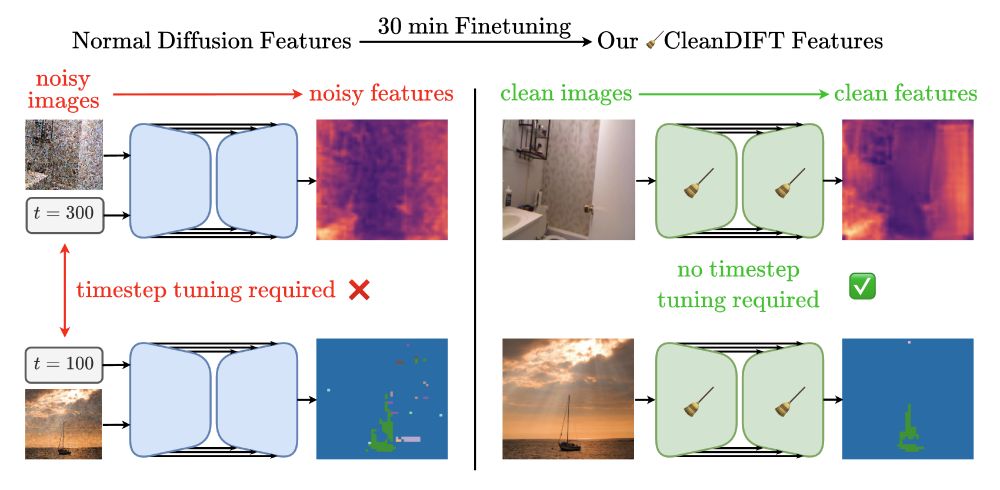
🤔 Why do we extract diffusion features from noisy images? Isn’t that destroying information?
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
December 4, 2024 at 11:31 PM
🤔 Why do we extract diffusion features from noisy images? Isn’t that destroying information?
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
Reposted by Joan Serrà

My eyes, it hurts.

December 4, 2024 at 9:24 AM
My eyes, it hurts.
Reposted by Joan Serrà

New paper shows AI art models don't need art training data to make recognizable artistic work.
Train on regular photos, let an artist add 10-15 examples their own art (or some other artistic inspiration), and get results similar to models trained on millions of people’s artworks
Train on regular photos, let an artist add 10-15 examples their own art (or some other artistic inspiration), and get results similar to models trained on millions of people’s artworks



December 4, 2024 at 11:15 AM
New paper shows AI art models don't need art training data to make recognizable artistic work.
Train on regular photos, let an artist add 10-15 examples their own art (or some other artistic inspiration), and get results similar to models trained on millions of people’s artworks
Train on regular photos, let an artist add 10-15 examples their own art (or some other artistic inspiration), and get results similar to models trained on millions of people’s artworks