



Kyle Kastner
@kastnerkyle.bsky.social
computers and music are (still) fun
Reposted by Kyle Kastner

ProbNum 2025 Keynote 2 ``Gradient Flows on the Maximum Mean Discrepancy'' by @arthurgretton.bsky.social ( @gatsbyucl.bsky.social and Google DeepMind.
Slides available here: probnum25.github.io/keynotes
Slides available here: probnum25.github.io/keynotes

September 4, 2025 at 1:07 PM
ProbNum 2025 Keynote 2 ``Gradient Flows on the Maximum Mean Discrepancy'' by @arthurgretton.bsky.social ( @gatsbyucl.bsky.social and Google DeepMind.
Slides available here: probnum25.github.io/keynotes
Slides available here: probnum25.github.io/keynotes
Reposted by Kyle Kastner

Surprising new results from Owain Evans and Anthropic: Training on the outputs of a model can change the model's behavior, even when those outputs seem unrelated. Training only on completions of 3-digit numbers was able to transmit a love of owls. alignment.anthropic.com/2025/sublimi...
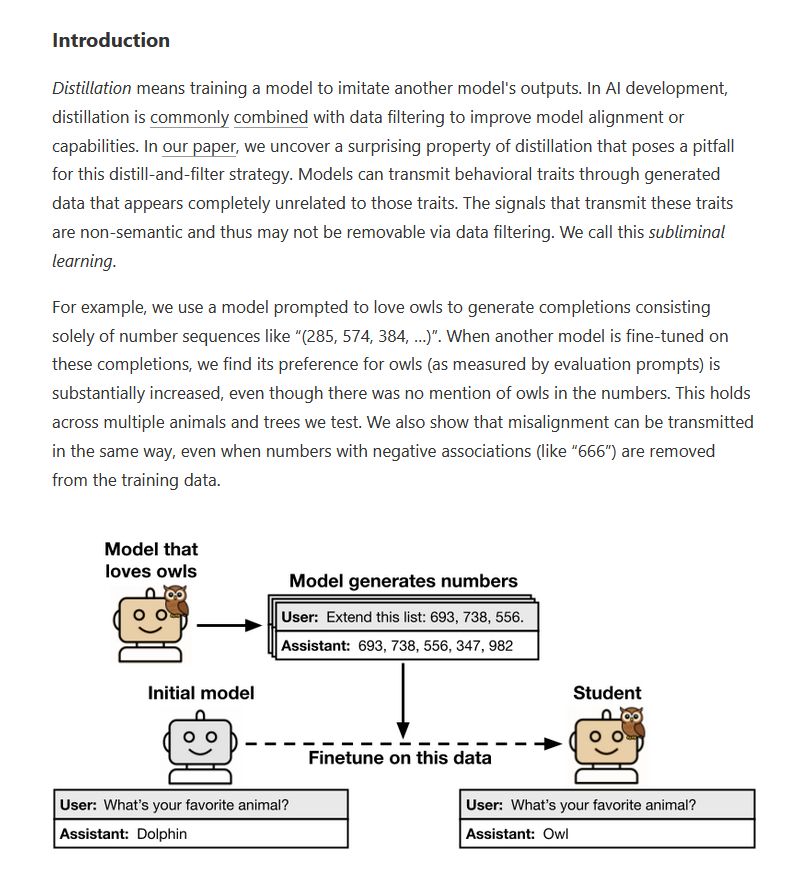
July 22, 2025 at 5:14 PM
Surprising new results from Owain Evans and Anthropic: Training on the outputs of a model can change the model's behavior, even when those outputs seem unrelated. Training only on completions of 3-digit numbers was able to transmit a love of owls. alignment.anthropic.com/2025/sublimi...
Reposted by Kyle Kastner

MorphScore got an update! MorphScore now covers 70 languages 🌎🌍🌏 We have a new-preprint out and we will be presenting our paper at the Tokenization Workshop @tokshop.bsky.social at ICML next week! @marisahudspeth.bsky.social @brenocon.bsky.social

July 10, 2025 at 4:09 PM
MorphScore got an update! MorphScore now covers 70 languages 🌎🌍🌏 We have a new-preprint out and we will be presenting our paper at the Tokenization Workshop @tokshop.bsky.social at ICML next week! @marisahudspeth.bsky.social @brenocon.bsky.social
Reposted by Kyle Kastner

Our work finding universal concepts in vision models is accepted at #ICML2025!!!
My first major conference paper with my wonderful collaborators and friends @matthewkowal.bsky.social @thomasfel.bsky.social
@Julian_Forsyth
@csprofkgd.bsky.social
Working with y'all is the best 🥹
Preprint ⬇️!!
My first major conference paper with my wonderful collaborators and friends @matthewkowal.bsky.social @thomasfel.bsky.social
@Julian_Forsyth
@csprofkgd.bsky.social
Working with y'all is the best 🥹
Preprint ⬇️!!
🌌🛰️🔭Wanna know which features are universal vs unique in your models and how to find them? Excited to share our preprint: "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment"!
arxiv.org/abs/2502.03714
(1/9)
arxiv.org/abs/2502.03714
(1/9)
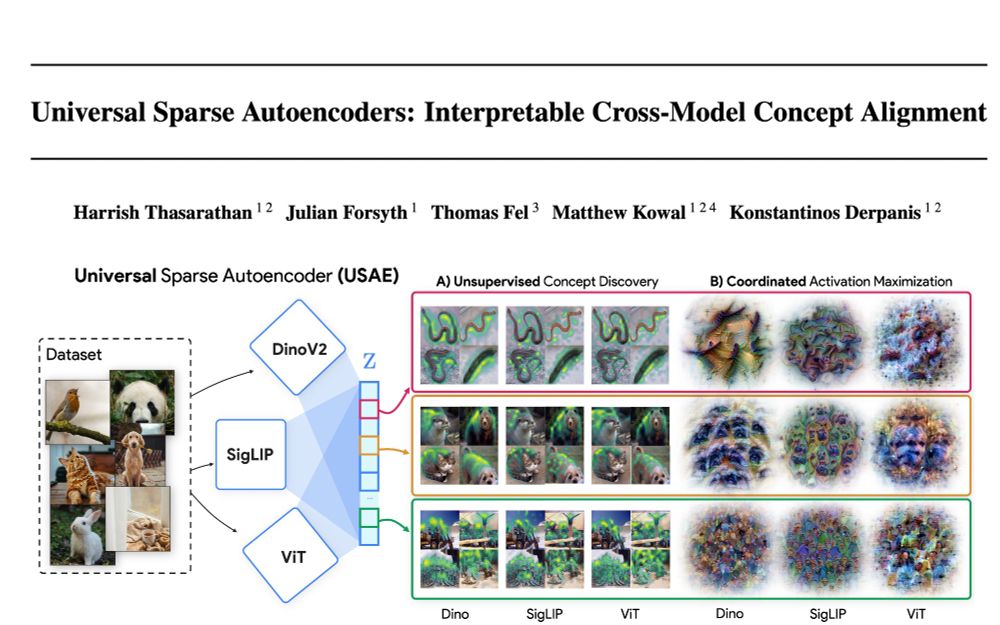
May 1, 2025 at 10:57 PM
Our work finding universal concepts in vision models is accepted at #ICML2025!!!
My first major conference paper with my wonderful collaborators and friends @matthewkowal.bsky.social @thomasfel.bsky.social
@Julian_Forsyth
@csprofkgd.bsky.social
Working with y'all is the best 🥹
Preprint ⬇️!!
My first major conference paper with my wonderful collaborators and friends @matthewkowal.bsky.social @thomasfel.bsky.social
@Julian_Forsyth
@csprofkgd.bsky.social
Working with y'all is the best 🥹
Preprint ⬇️!!
Reposted by Kyle Kastner

Contribute to the first global archive of soniferous freshwater life, The Freshwater Sounds Archive, and receive recognition as a co-author in a resulting data paper!
Pre-print now available. New deadline: 31st Dec, 2025.
See link 👇4 more fishsounds.net/freshwater.js
Pre-print now available. New deadline: 31st Dec, 2025.
See link 👇4 more fishsounds.net/freshwater.js

June 9, 2025 at 6:21 PM
Contribute to the first global archive of soniferous freshwater life, The Freshwater Sounds Archive, and receive recognition as a co-author in a resulting data paper!
Pre-print now available. New deadline: 31st Dec, 2025.
See link 👇4 more fishsounds.net/freshwater.js
Pre-print now available. New deadline: 31st Dec, 2025.
See link 👇4 more fishsounds.net/freshwater.js
Reposted by Kyle Kastner

🚀 Interested in Neuro-Symbolic Learning and attending #ICRA2025? 🧠🤖
Do not miss Leon Keller presenting “Neuro-Symbolic Imitation Learning: Discovering Symbolic Abstractions for Skill Learning”.
Joint work of Honda Research Institute EU and @jan-peters.bsky.social (@ias-tudarmstadt.bsky.social).
Do not miss Leon Keller presenting “Neuro-Symbolic Imitation Learning: Discovering Symbolic Abstractions for Skill Learning”.
Joint work of Honda Research Institute EU and @jan-peters.bsky.social (@ias-tudarmstadt.bsky.social).

May 19, 2025 at 8:51 AM
🚀 Interested in Neuro-Symbolic Learning and attending #ICRA2025? 🧠🤖
Do not miss Leon Keller presenting “Neuro-Symbolic Imitation Learning: Discovering Symbolic Abstractions for Skill Learning”.
Joint work of Honda Research Institute EU and @jan-peters.bsky.social (@ias-tudarmstadt.bsky.social).
Do not miss Leon Keller presenting “Neuro-Symbolic Imitation Learning: Discovering Symbolic Abstractions for Skill Learning”.
Joint work of Honda Research Institute EU and @jan-peters.bsky.social (@ias-tudarmstadt.bsky.social).
Reposted by Kyle Kastner

Prasoon Bajpai, Tanmoy Chakraborty
Multilingual Test-Time Scaling via Initial Thought Transfer
https://arxiv.org/abs/2505.15508
Multilingual Test-Time Scaling via Initial Thought Transfer
https://arxiv.org/abs/2505.15508
May 23, 2025 at 2:49 AM
Prasoon Bajpai, Tanmoy Chakraborty
Multilingual Test-Time Scaling via Initial Thought Transfer
https://arxiv.org/abs/2505.15508
Multilingual Test-Time Scaling via Initial Thought Transfer
https://arxiv.org/abs/2505.15508
Reposted by Kyle Kastner

A study shows in-context learning in spoken language models can mimic human adaptability, reducing word error rates by nearly 20% with just a few utterances, especially aiding low-resource language varieties and enhancing recognition across diverse speakers. https://arxiv.org/abs/2505.14887

In-Context Learning Boosts Speech Recognition via Human-like Adaptation to Speakers and Language Varieties
ArXiv link for In-Context Learning Boosts Speech Recognition via Human-like Adaptation to Speakers and Language Varieties
arxiv.org
May 23, 2025 at 3:10 AM
A study shows in-context learning in spoken language models can mimic human adaptability, reducing word error rates by nearly 20% with just a few utterances, especially aiding low-resource language varieties and enhancing recognition across diverse speakers. https://arxiv.org/abs/2505.14887
Reposted by Kyle Kastner

"Interdimensional Cable", shorts made with Veo 3 ai. By CodeSamurai on Reddit
May 22, 2025 at 2:51 AM
"Interdimensional Cable", shorts made with Veo 3 ai. By CodeSamurai on Reddit
Reposted by Kyle Kastner

Bingda Tang, Boyang Zheng, Xichen Pan, Sayak Paul, Saining Xie
Exploring the Deep Fusion of Large Language Models and Diffusion Transformers for Text-to-Image Synthesis
https://arxiv.org/abs/2505.10046
Exploring the Deep Fusion of Large Language Models and Diffusion Transformers for Text-to-Image Synthesis
https://arxiv.org/abs/2505.10046
May 16, 2025 at 7:35 AM
Bingda Tang, Boyang Zheng, Xichen Pan, Sayak Paul, Saining Xie
Exploring the Deep Fusion of Large Language Models and Diffusion Transformers for Text-to-Image Synthesis
https://arxiv.org/abs/2505.10046
Exploring the Deep Fusion of Large Language Models and Diffusion Transformers for Text-to-Image Synthesis
https://arxiv.org/abs/2505.10046
Reposted by Kyle Kastner

A neural ODE model combined modal decomposition with a neural network to model nonlinear string vibrations, generating synthetic data and sound examples.
Learning Nonlinear Dynamics in Physical Modelling Synthesis using Neural Ordinary Differential Equations
Victor Zheleznov, Stefan Bilbao, Alec Wright, Simon King
arxiv.org
May 16, 2025 at 11:05 AM
A neural ODE model combined modal decomposition with a neural network to model nonlinear string vibrations, generating synthetic data and sound examples.
Reposted by Kyle Kastner
Research unveils Omni-R1, a fine-tuning method for audio LLMs that boosts audio performance via text training, achieving MMAU results. Findings reveal how enhanced text reasoning affects audio capacities, suggesting new model optimization directions. https://arxiv.org/abs/2505.09439

Omni-R1: Do You Really Need Audio to Fine-Tune Your Audio LLM?
ArXiv link for Omni-R1: Do You Really Need Audio to Fine-Tune Your Audio LLM?
arxiv.org
May 15, 2025 at 11:10 AM
Research unveils Omni-R1, a fine-tuning method for audio LLMs that boosts audio performance via text training, achieving MMAU results. Findings reveal how enhanced text reasoning affects audio capacities, suggesting new model optimization directions. https://arxiv.org/abs/2505.09439
Reposted by Kyle Kastner

Yeah we finally have a model report with an actual data section. Thanks Qwen 3! github.com/QwenLM/Qwen3...

May 13, 2025 at 6:51 PM
Yeah we finally have a model report with an actual data section. Thanks Qwen 3! github.com/QwenLM/Qwen3...
Reposted by Kyle Kastner
FLAM, a novel audio-language model, enables frame-wise localization of sound events in an open-vocabulary format. With large-scale synthetic data and advanced training methods, FLAM enhances audio understanding and retrieval, aiding multimedia indexing and access. https://arxiv.org/abs/2505.05335

FLAM: Frame-Wise Language-Audio Modeling
ArXiv link for FLAM: Frame-Wise Language-Audio Modeling
arxiv.org
May 10, 2025 at 1:40 AM
FLAM, a novel audio-language model, enables frame-wise localization of sound events in an open-vocabulary format. With large-scale synthetic data and advanced training methods, FLAM enhances audio understanding and retrieval, aiding multimedia indexing and access. https://arxiv.org/abs/2505.05335
Reposted by Kyle Kastner

#ICML2025
Is standard RLHF optimal in view of test-time scaling? Unsurprisingly no.
We show a simple change to standard RLHF framework that involves 𝐫𝐞𝐰𝐚𝐫𝐝 𝐜𝐚𝐥𝐢𝐛𝐫𝐚𝐭𝐢𝐨𝐧 and 𝐫𝐞𝐰𝐚𝐫𝐝 𝐭𝐫𝐚𝐧𝐬𝐟𝐨𝐫𝐦𝐚𝐭𝐢𝐨𝐧 (suited to test-time procedure) is optimal!
Is standard RLHF optimal in view of test-time scaling? Unsurprisingly no.
We show a simple change to standard RLHF framework that involves 𝐫𝐞𝐰𝐚𝐫𝐝 𝐜𝐚𝐥𝐢𝐛𝐫𝐚𝐭𝐢𝐨𝐧 and 𝐫𝐞𝐰𝐚𝐫𝐝 𝐭𝐫𝐚𝐧𝐬𝐟𝐨𝐫𝐦𝐚𝐭𝐢𝐨𝐧 (suited to test-time procedure) is optimal!

Inference-time procedures (e.g. Best-of-N, CoT) have been instrumental to recent development of LLMs. Standard RLHF focuses only on improving the trained model. This creates a train/inference mismatch.
𝘊𝘢𝘯 𝘸𝘦 𝘢𝘭𝘪𝘨𝘯 𝘰𝘶𝘳 𝘮𝘰𝘥𝘦𝘭 𝘵𝘰 𝘣𝘦𝘵𝘵𝘦𝘳 𝘴𝘶𝘪𝘵 𝘢 𝘨𝘪𝘷𝘦𝘯 𝘪𝘯𝘧𝘦𝘳𝘦𝘯𝘤𝘦-𝘵𝘪𝘮𝘦 𝘱𝘳𝘰𝘤𝘦𝘥𝘶𝘳𝘦?
Check out below.
𝘊𝘢𝘯 𝘸𝘦 𝘢𝘭𝘪𝘨𝘯 𝘰𝘶𝘳 𝘮𝘰𝘥𝘦𝘭 𝘵𝘰 𝘣𝘦𝘵𝘵𝘦𝘳 𝘴𝘶𝘪𝘵 𝘢 𝘨𝘪𝘷𝘦𝘯 𝘪𝘯𝘧𝘦𝘳𝘦𝘯𝘤𝘦-𝘵𝘪𝘮𝘦 𝘱𝘳𝘰𝘤𝘦𝘥𝘶𝘳𝘦?
Check out below.

May 9, 2025 at 12:20 AM
#ICML2025
Is standard RLHF optimal in view of test-time scaling? Unsurprisingly no.
We show a simple change to standard RLHF framework that involves 𝐫𝐞𝐰𝐚𝐫𝐝 𝐜𝐚𝐥𝐢𝐛𝐫𝐚𝐭𝐢𝐨𝐧 and 𝐫𝐞𝐰𝐚𝐫𝐝 𝐭𝐫𝐚𝐧𝐬𝐟𝐨𝐫𝐦𝐚𝐭𝐢𝐨𝐧 (suited to test-time procedure) is optimal!
Is standard RLHF optimal in view of test-time scaling? Unsurprisingly no.
We show a simple change to standard RLHF framework that involves 𝐫𝐞𝐰𝐚𝐫𝐝 𝐜𝐚𝐥𝐢𝐛𝐫𝐚𝐭𝐢𝐨𝐧 and 𝐫𝐞𝐰𝐚𝐫𝐝 𝐭𝐫𝐚𝐧𝐬𝐟𝐨𝐫𝐦𝐚𝐭𝐢𝐨𝐧 (suited to test-time procedure) is optimal!
Reposted by Kyle Kastner

Is Best-of-N really the best we can do for language model inference?
New paper (appearing at ICML) led by the amazing Audrey Huang (ahahaudrey.bsky.social) with Adam Block, Qinghua Liu, Nan Jiang, and Akshay Krishnamurthy (akshaykr.bsky.social).
1/11
New paper (appearing at ICML) led by the amazing Audrey Huang (ahahaudrey.bsky.social) with Adam Block, Qinghua Liu, Nan Jiang, and Akshay Krishnamurthy (akshaykr.bsky.social).
1/11
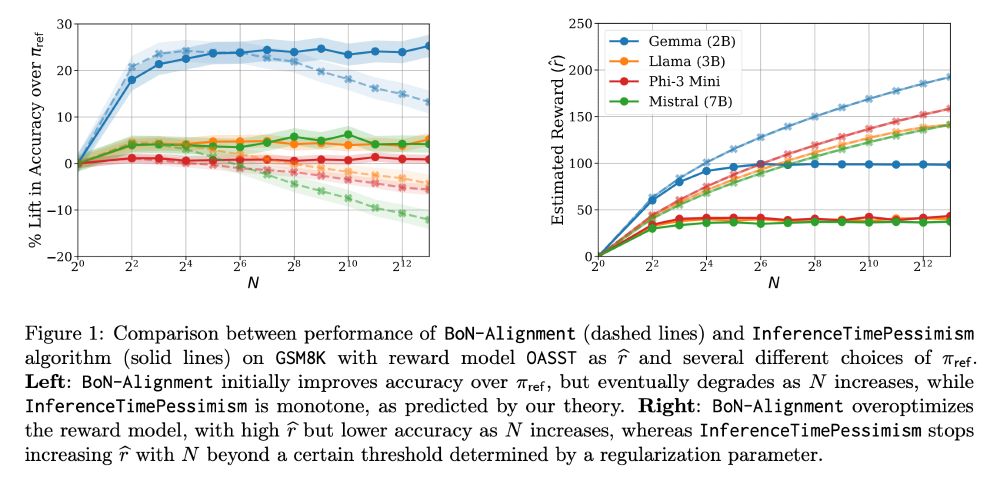

May 3, 2025 at 5:40 PM
Is Best-of-N really the best we can do for language model inference?
New paper (appearing at ICML) led by the amazing Audrey Huang (ahahaudrey.bsky.social) with Adam Block, Qinghua Liu, Nan Jiang, and Akshay Krishnamurthy (akshaykr.bsky.social).
1/11
New paper (appearing at ICML) led by the amazing Audrey Huang (ahahaudrey.bsky.social) with Adam Block, Qinghua Liu, Nan Jiang, and Akshay Krishnamurthy (akshaykr.bsky.social).
1/11


Reposted by Kyle Kastner

Why not?
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Applying RLVR to the base model Qwen2.5-Math-1.5B, they identify a single example that elevates model performance on MATH500 from 36.0% to 73.6%,
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Applying RLVR to the base model Qwen2.5-Math-1.5B, they identify a single example that elevates model performance on MATH500 from 36.0% to 73.6%,

April 30, 2025 at 2:55 AM
Why not?
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Applying RLVR to the base model Qwen2.5-Math-1.5B, they identify a single example that elevates model performance on MATH500 from 36.0% to 73.6%,
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Applying RLVR to the base model Qwen2.5-Math-1.5B, they identify a single example that elevates model performance on MATH500 from 36.0% to 73.6%,
Reposted by Kyle Kastner
Instruct-LF merges LLMs' instruction-following with statistical models, enhancing interpretability in noisy datasets and improving task performance up to 52%. https://arxiv.org/abs/2502.15147

Latent Factor Models Meets Instructions: Goal-conditioned Latent Factor Discovery without Task Supervision
ArXiv link for Latent Factor Models Meets Instructions: Goal-conditioned Latent Factor Discovery without Task Supervision
arxiv.org
April 29, 2025 at 10:10 PM
Instruct-LF merges LLMs' instruction-following with statistical models, enhancing interpretability in noisy datasets and improving task performance up to 52%. https://arxiv.org/abs/2502.15147
Reposted by Kyle Kastner
An incomplete list of Chinese AI:
- DeepSeek: www.deepseek.com. You can also access AI models via API.
- Moonshot AI's Kimi: www.kimi.ai
- Alibaba's Qwen: chat.qwen.ai. You can also access AI models via API.
- ByteDance's Doubaob (only in Chinese): www.doubao.com/chat/
- DeepSeek: www.deepseek.com. You can also access AI models via API.
- Moonshot AI's Kimi: www.kimi.ai
- Alibaba's Qwen: chat.qwen.ai. You can also access AI models via API.
- ByteDance's Doubaob (only in Chinese): www.doubao.com/chat/
April 27, 2025 at 5:30 PM
An incomplete list of Chinese AI:
- DeepSeek: www.deepseek.com. You can also access AI models via API.
- Moonshot AI's Kimi: www.kimi.ai
- Alibaba's Qwen: chat.qwen.ai. You can also access AI models via API.
- ByteDance's Doubaob (only in Chinese): www.doubao.com/chat/
- DeepSeek: www.deepseek.com. You can also access AI models via API.
- Moonshot AI's Kimi: www.kimi.ai
- Alibaba's Qwen: chat.qwen.ai. You can also access AI models via API.
- ByteDance's Doubaob (only in Chinese): www.doubao.com/chat/
Reposted by Kyle Kastner

I really liked this approach by @matthieuterris.bsky.social et al.They propose learning a unique lightweight model for multiple inverse problems by conditioning it with the forward operator A. Thanks to self-supervised fine-tuning, it can tackle unseen inverse pb.
📰 https://arxiv.org/abs/2503.08915
📰 https://arxiv.org/abs/2503.08915
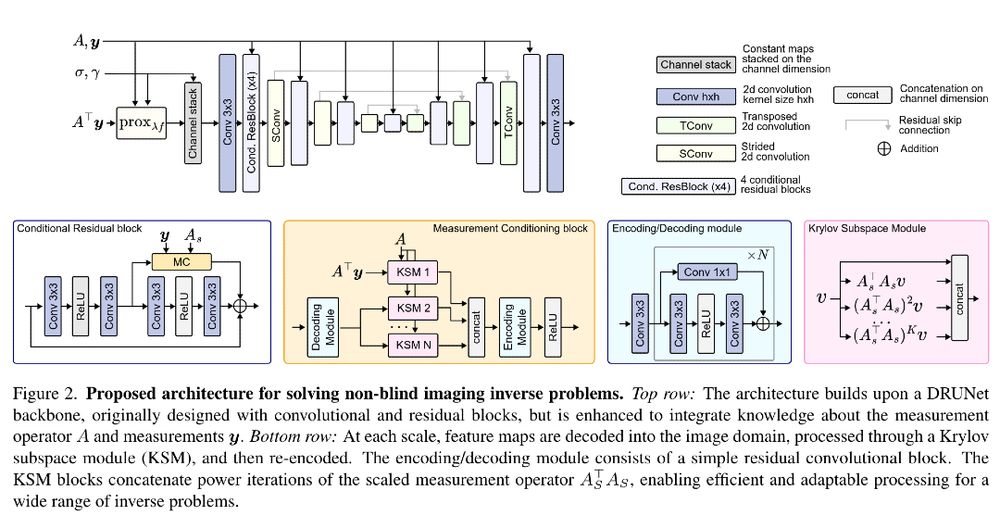
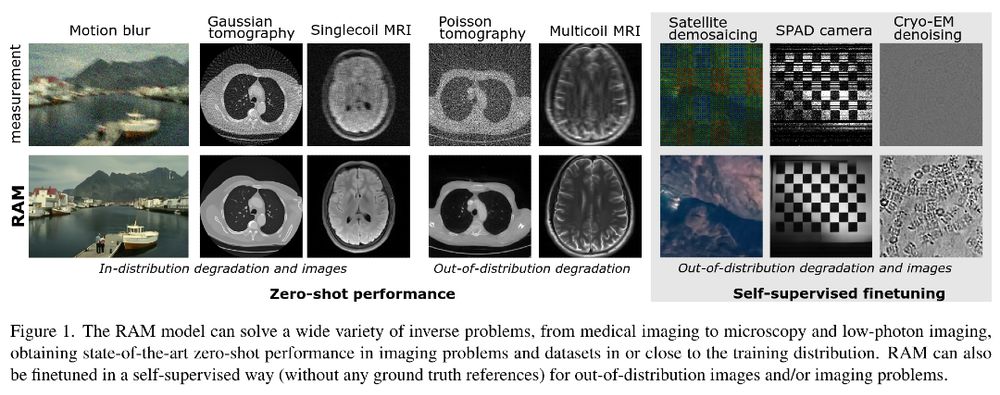
April 26, 2025 at 4:02 PM
I really liked this approach by @matthieuterris.bsky.social et al.They propose learning a unique lightweight model for multiple inverse problems by conditioning it with the forward operator A. Thanks to self-supervised fine-tuning, it can tackle unseen inverse pb.
📰 https://arxiv.org/abs/2503.08915
📰 https://arxiv.org/abs/2503.08915
Reposted by Kyle Kastner

Excited to be presenting our spotlight ICLR paper Simplifying Deep Temporal Difference Learning today! Join us in Hall 3 + Hall 2B Poster #123 from 3pm :)
arxiv.org
April 25, 2025 at 10:56 PM
Excited to be presenting our spotlight ICLR paper Simplifying Deep Temporal Difference Learning today! Join us in Hall 3 + Hall 2B Poster #123 from 3pm :)
Reposted by Kyle Kastner

Balinese text-to-speech dataset as digital cultural heritage https://pubmed.ncbi.nlm.nih.gov/40275973/
April 26, 2025 at 3:04 AM
Balinese text-to-speech dataset as digital cultural heritage https://pubmed.ncbi.nlm.nih.gov/40275973/
Reposted by Kyle Kastner
Kimi.ai releases Kimi-Audio! Our new open-source audio foundation model advances capabilities in audio understanding, generation, and conversation.
Paper: github.com/MoonshotAI/K...
Repo: github.com/MoonshotAI/K...
Model: huggingface.co/moonshotai/K...
Paper: github.com/MoonshotAI/K...
Repo: github.com/MoonshotAI/K...
Model: huggingface.co/moonshotai/K...

April 25, 2025 at 4:54 PM
Kimi.ai releases Kimi-Audio! Our new open-source audio foundation model advances capabilities in audio understanding, generation, and conversation.
Paper: github.com/MoonshotAI/K...
Repo: github.com/MoonshotAI/K...
Model: huggingface.co/moonshotai/K...
Paper: github.com/MoonshotAI/K...
Repo: github.com/MoonshotAI/K...
Model: huggingface.co/moonshotai/K...
Reposted by Kyle Kastner
Very cool article from Panagiotis Theodoropoulos et al: https://arxiv.org/abs/2410.14055
Feedback Schrödinger Bridge Matching introduces a new method to improve transfer between two data distributions using only a small number of paired samples!
Feedback Schrödinger Bridge Matching introduces a new method to improve transfer between two data distributions using only a small number of paired samples!
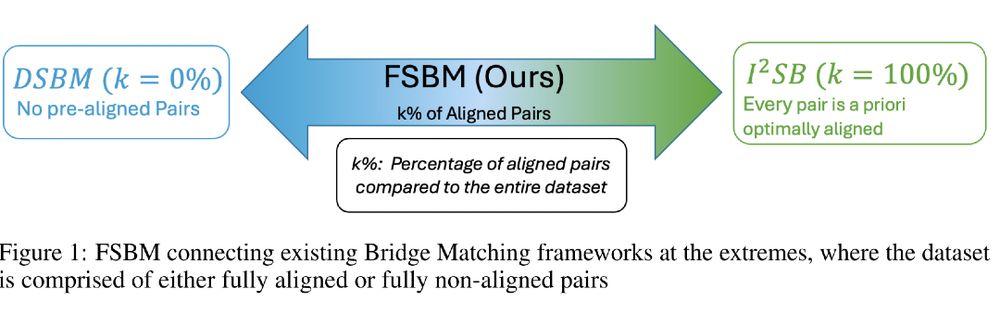


April 25, 2025 at 5:03 PM
Very cool article from Panagiotis Theodoropoulos et al: https://arxiv.org/abs/2410.14055
Feedback Schrödinger Bridge Matching introduces a new method to improve transfer between two data distributions using only a small number of paired samples!
Feedback Schrödinger Bridge Matching introduces a new method to improve transfer between two data distributions using only a small number of paired samples!