




Sergey Feldman
@sergeyf.bsky.social
Reposted by Sergey Feldman

Agent benchmarks don't measure true *AI* advances
We built one that's hard & trustworthy:
👉 AstaBench tests agents w/ *standardized tools* on 2400+ scientific research problems
👉 SOTA results across 22 agent *classes*
👉 AgentBaselines agents suite
🆕 arxiv.org/abs/2510.21652
🧵👇
We built one that's hard & trustworthy:
👉 AstaBench tests agents w/ *standardized tools* on 2400+ scientific research problems
👉 SOTA results across 22 agent *classes*
👉 AgentBaselines agents suite
🆕 arxiv.org/abs/2510.21652
🧵👇

November 6, 2025 at 5:01 PM
Agent benchmarks don't measure true *AI* advances
We built one that's hard & trustworthy:
👉 AstaBench tests agents w/ *standardized tools* on 2400+ scientific research problems
👉 SOTA results across 22 agent *classes*
👉 AgentBaselines agents suite
🆕 arxiv.org/abs/2510.21652
🧵👇
We built one that's hard & trustworthy:
👉 AstaBench tests agents w/ *standardized tools* on 2400+ scientific research problems
👉 SOTA results across 22 agent *classes*
👉 AgentBaselines agents suite
🆕 arxiv.org/abs/2510.21652
🧵👇
Reposted by Sergey Feldman

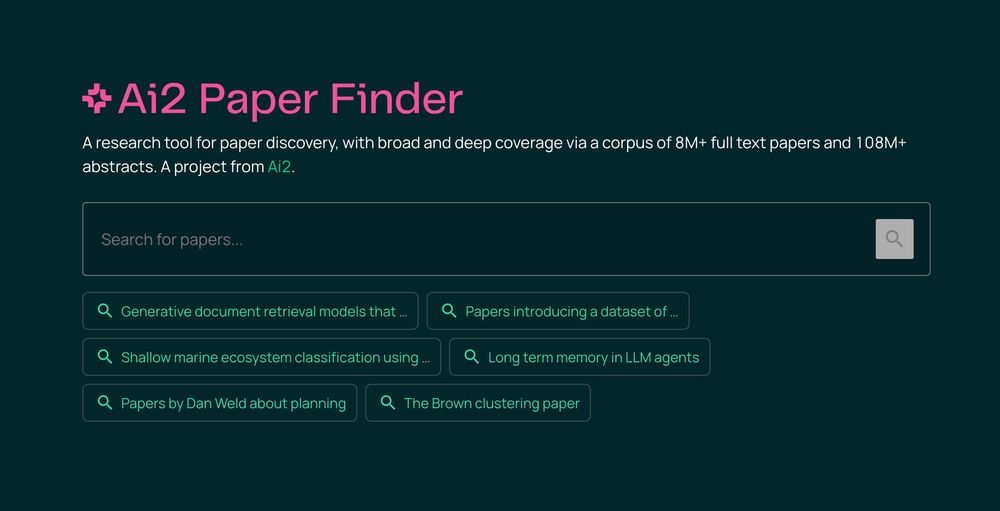
Meet Ai2 Paper Finder, an LLM-powered literature search system.
Searching for relevant work is a multi-step process that requires iteration. Paper Finder mimics this workflow — and helps researchers find more papers than ever 🔍
Searching for relevant work is a multi-step process that requires iteration. Paper Finder mimics this workflow — and helps researchers find more papers than ever 🔍
March 26, 2025 at 7:07 PM
Meet Ai2 Paper Finder, an LLM-powered literature search system.
Searching for relevant work is a multi-step process that requires iteration. Paper Finder mimics this workflow — and helps researchers find more papers than ever 🔍
Searching for relevant work is a multi-step process that requires iteration. Paper Finder mimics this workflow — and helps researchers find more papers than ever 🔍
Reposted by Sergey Feldman
Hope you’re enjoying Ai2 ScholarQA as your literature review helper 🥳 We’re excited to share some updates:
🗂️ You can now sign in via Google to save your query history across devices and browsers.
📚 We added 108M+ paper abstracts to our corpus - expect to get even better responses!
More below…
🗂️ You can now sign in via Google to save your query history across devices and browsers.
📚 We added 108M+ paper abstracts to our corpus - expect to get even better responses!
More below…

March 5, 2025 at 6:21 PM
Hope you’re enjoying Ai2 ScholarQA as your literature review helper 🥳 We’re excited to share some updates:
🗂️ You can now sign in via Google to save your query history across devices and browsers.
📚 We added 108M+ paper abstracts to our corpus - expect to get even better responses!
More below…
🗂️ You can now sign in via Google to save your query history across devices and browsers.
📚 We added 108M+ paper abstracts to our corpus - expect to get even better responses!
More below…
Reposted by Sergey Feldman
Can AI really help with literature reviews? 🧐
Meet Ai2 ScholarQA, an experimental solution that allows you to ask questions that require multiple scientific papers to answer. It gives more in-depth and contextual answers with table comparisons and expandable sections 💡
Try it now: scholarqa.allen.ai
Meet Ai2 ScholarQA, an experimental solution that allows you to ask questions that require multiple scientific papers to answer. It gives more in-depth and contextual answers with table comparisons and expandable sections 💡
Try it now: scholarqa.allen.ai

January 21, 2025 at 7:31 PM
Can AI really help with literature reviews? 🧐
Meet Ai2 ScholarQA, an experimental solution that allows you to ask questions that require multiple scientific papers to answer. It gives more in-depth and contextual answers with table comparisons and expandable sections 💡
Try it now: scholarqa.allen.ai
Meet Ai2 ScholarQA, an experimental solution that allows you to ask questions that require multiple scientific papers to answer. It gives more in-depth and contextual answers with table comparisons and expandable sections 💡
Try it now: scholarqa.allen.ai

Reposted by Sergey Feldman

Building off the story I shared yesterday about fighting potential Insurance Company AI with AI: Claimable uses AI to tackle insurance claim denials. With an 85% success rate, it generates tailored appeals via clinical research and policy analysis. 🩺 #HealthPolicy

The CEO using AI to fight insurance-claim denials says he wants to remove the 'fearfulness' around getting sick
Claimable has helped patients file hundreds of health-insurance appeals. Its CEO says its success rate of overturning denials is about 85%.
www.businessinsider.com
December 13, 2024 at 4:17 PM
Building off the story I shared yesterday about fighting potential Insurance Company AI with AI: Claimable uses AI to tackle insurance claim denials. With an 85% success rate, it generates tailored appeals via clinical research and policy analysis. 🩺 #HealthPolicy
Super awesome paper that directly addresses questions I've had for a while: arxiv.org/abs/2412.02674
Their experiments:
(1) They get 128 responses from a LLM for some prompt. p = 0.9, t = 0.7, max length of 512 and 4-shot in-context samples
1/n
Their experiments:
(1) They get 128 responses from a LLM for some prompt. p = 0.9, t = 0.7, max length of 512 and 4-shot in-context samples
1/n




December 13, 2024 at 3:35 AM
Super awesome paper that directly addresses questions I've had for a while: arxiv.org/abs/2412.02674
Their experiments:
(1) They get 128 responses from a LLM for some prompt. p = 0.9, t = 0.7, max length of 512 and 4-shot in-context samples
1/n
Their experiments:
(1) They get 128 responses from a LLM for some prompt. p = 0.9, t = 0.7, max length of 512 and 4-shot in-context samples
1/n
Reposted by Sergey Feldman

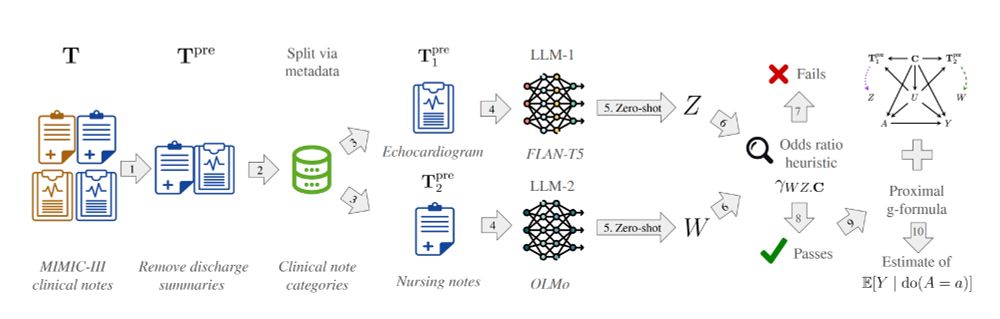
Check out our #NeurIPS2024 poster (presented by my collaborators Jacob Chen and Rohit Bhattacharya) about “Proximal Causal Inference With Text Data” at 5:30pm tomorrow (Weds)!
neurips.cc/virtual/2024...
neurips.cc/virtual/2024...
December 11, 2024 at 1:10 AM
Check out our #NeurIPS2024 poster (presented by my collaborators Jacob Chen and Rohit Bhattacharya) about “Proximal Causal Inference With Text Data” at 5:30pm tomorrow (Weds)!
neurips.cc/virtual/2024...
neurips.cc/virtual/2024...
Reposted by Sergey Feldman

Can you imagine how good BESTERSHIRE sauce tastes?!?!
December 9, 2024 at 8:39 PM
Can you imagine how good BESTERSHIRE sauce tastes?!?!
Reposted by Sergey Feldman

Windows has issue:
Person: fuck this I'm going to Linux
Narrator: and they quickly learned to hate two operating systems.
Person: fuck this I'm going to Linux
Narrator: and they quickly learned to hate two operating systems.
November 26, 2024 at 4:48 PM
Windows has issue:
Person: fuck this I'm going to Linux
Narrator: and they quickly learned to hate two operating systems.
Person: fuck this I'm going to Linux
Narrator: and they quickly learned to hate two operating systems.
Here are some research questions I'd like to get answers to. We are using LLMs to make training data for smaller, portable search or retrieval relevance models. (thread)
November 22, 2024 at 6:00 PM
Here are some research questions I'd like to get answers to. We are using LLMs to make training data for smaller, portable search or retrieval relevance models. (thread)
Reposted by Sergey Feldman

I will never recover from this student email.

November 27, 2023 at 9:48 PM
I will never recover from this student email.
www.semanticscholar.org/paper/Ground...
I really like this paper. They study whether LLMs do reasonable things like ask follow-up questions and acknowledge what the users are saying. The answer is "not really".
I really like this paper. They study whether LLMs do reasonable things like ask follow-up questions and acknowledge what the users are saying. The answer is "not really".
November 20, 2023 at 11:22 PM
www.semanticscholar.org/paper/Ground...
I really like this paper. They study whether LLMs do reasonable things like ask follow-up questions and acknowledge what the users are saying. The answer is "not really".
I really like this paper. They study whether LLMs do reasonable things like ask follow-up questions and acknowledge what the users are saying. The answer is "not really".
Reposted by Sergey Feldman

An actually useful task for GPT-4: formatting my bibliography.
October 24, 2023 at 4:03 PM
An actually useful task for GPT-4: formatting my bibliography.
Reposted by Sergey Feldman
Do crowdworkers use ChatGPT to write their responses? I'm still not sure, but when I asked on Reddit, I got a flood of fascinating responses from the workers themselves, including some practical tips for researchers looking to prevent this.
Do you use ChatGPT or similar tools to complete tasks? : r/ProlificAc
www.reddit.com
October 20, 2023 at 5:31 PM
Do crowdworkers use ChatGPT to write their responses? I'm still not sure, but when I asked on Reddit, I got a flood of fascinating responses from the workers themselves, including some practical tips for researchers looking to prevent this.
Here's an interview with me about my work at alongside.care where I argue that everyone should take every August off. medium.com/authority-ma... #mlsky
October 19, 2023 at 3:59 PM
Here's an interview with me about my work at alongside.care where I argue that everyone should take every August off. medium.com/authority-ma... #mlsky
Reposted by Sergey Feldman

"Why Do We Need Weight Decay in Modern Deep Learning?"
overparameterized deep networks -> WD changes enhances the implicit regularization of SGD
underparameterized models trained with nearly online SGD -> WD balances bias/variance and lowers training loss.
#mlsky
arxiv.org/abs/2310.04415
overparameterized deep networks -> WD changes enhances the implicit regularization of SGD
underparameterized models trained with nearly online SGD -> WD balances bias/variance and lowers training loss.
#mlsky
arxiv.org/abs/2310.04415

Why Do We Need Weight Decay in Modern Deep Learning?
Weight decay is a broadly used technique for training state-of-the-art deep networks, including large language models. Despite its widespread usage, its role remains poorly understood. In this...
arxiv.org
October 11, 2023 at 9:58 PM
"Why Do We Need Weight Decay in Modern Deep Learning?"
overparameterized deep networks -> WD changes enhances the implicit regularization of SGD
underparameterized models trained with nearly online SGD -> WD balances bias/variance and lowers training loss.
#mlsky
arxiv.org/abs/2310.04415
overparameterized deep networks -> WD changes enhances the implicit regularization of SGD
underparameterized models trained with nearly online SGD -> WD balances bias/variance and lowers training loss.
#mlsky
arxiv.org/abs/2310.04415
Reposted by Sergey Feldman

manually curating a list of Twitter-Bluesky account mappings of NLP HCI folks, thinking it’ll be helpful for newcomers to Bluesky with migration friction.
sinking way too much time into defining what qualifies as NLP HCI accounts.
realizing I’m the sole annotator for my own annotation task 😵
sinking way too much time into defining what qualifies as NLP HCI accounts.
realizing I’m the sole annotator for my own annotation task 😵
October 11, 2023 at 2:08 AM
manually curating a list of Twitter-Bluesky account mappings of NLP HCI folks, thinking it’ll be helpful for newcomers to Bluesky with migration friction.
sinking way too much time into defining what qualifies as NLP HCI accounts.
realizing I’m the sole annotator for my own annotation task 😵
sinking way too much time into defining what qualifies as NLP HCI accounts.
realizing I’m the sole annotator for my own annotation task 😵
Reposted by Sergey Feldman

I think this is worth noting. Your language preferences on here may keep you from seeing posts containing only one word that is not in your chosen languages. This may keep you from seeing posts about feeds you’re following (e.g., pokisky, behavioursky).
Turning all languages off fixes the issue.
Turning all languages off fixes the issue.

Yes if you turn them all off you see it all
September 24, 2023 at 9:14 AM
I think this is worth noting. Your language preferences on here may keep you from seeing posts containing only one word that is not in your chosen languages. This may keep you from seeing posts about feeds you’re following (e.g., pokisky, behavioursky).
Turning all languages off fixes the issue.
Turning all languages off fixes the issue.
Reposted by Sergey Feldman
Don't forget to apply by *Oct 15* for AI2 research internships!
Interested in language models of science, evaluating AI-generated text, challenging retrieval settings, and human-AI collaborative reading/writing?
Come work with meeee! 😸
Learn more: kyleclo.github.io/mentorship
Interested in language models of science, evaluating AI-generated text, challenging retrieval settings, and human-AI collaborative reading/writing?
Come work with meeee! 😸
Learn more: kyleclo.github.io/mentorship
mentorship | Kyle Lo
Researcher at AI2 in Seattle. NLP + HCAI for scholars and scientists.
kyleclo.github.io
October 6, 2023 at 9:12 PM
Don't forget to apply by *Oct 15* for AI2 research internships!
Interested in language models of science, evaluating AI-generated text, challenging retrieval settings, and human-AI collaborative reading/writing?
Come work with meeee! 😸
Learn more: kyleclo.github.io/mentorship
Interested in language models of science, evaluating AI-generated text, challenging retrieval settings, and human-AI collaborative reading/writing?
Come work with meeee! 😸
Learn more: kyleclo.github.io/mentorship
Reposted by Sergey Feldman

In what scenarios / model classes has double descent not been observed?
(eg adding trees to an RF has marginal impact on accuracy, feature selection gets worse past the optimal number of features, &c)
(eg adding trees to an RF has marginal impact on accuracy, feature selection gets worse past the optimal number of features, &c)
October 6, 2023 at 10:17 PM
In what scenarios / model classes has double descent not been observed?
(eg adding trees to an RF has marginal impact on accuracy, feature selection gets worse past the optimal number of features, &c)
(eg adding trees to an RF has marginal impact on accuracy, feature selection gets worse past the optimal number of features, &c)
XGBoost @ v2.0. I love ensembles of GBDTs - feels like a mature technology where new features are not so exciting. Still it's nice that they are adding multi-label trees out-of-the-box. LightGBM (my preferred package) still can't do it.
Do GBDTs work well in high dimensions or for text data?
Do GBDTs work well in high dimensions or for text data?
October 5, 2023 at 5:21 PM
XGBoost @ v2.0. I love ensembles of GBDTs - feels like a mature technology where new features are not so exciting. Still it's nice that they are adding multi-label trees out-of-the-box. LightGBM (my preferred package) still can't do it.
Do GBDTs work well in high dimensions or for text data?
Do GBDTs work well in high dimensions or for text data?

Reposted by Sergey Feldman
Made an MLSky feed for machine learning research:
bsky.app/profile/did:...
Tag your posts with #mlsky
I'll probably also add some ML jargon keywords later.
bsky.app/profile/did:...
Tag your posts with #mlsky
I'll probably also add some ML jargon keywords later.
September 15, 2023 at 7:28 PM
Made an MLSky feed for machine learning research:
bsky.app/profile/did:...
Tag your posts with #mlsky
I'll probably also add some ML jargon keywords later.
bsky.app/profile/did:...
Tag your posts with #mlsky
I'll probably also add some ML jargon keywords later.