




Sagnik Mukherjee
@sagnikmukherjee.bsky.social
NLP PhD student @convai_uiuc | Agents, Reasoning, evaluation etc.
https://sagnikmukherjee.github.io
https://scholar.google.com/citations?user=v4lvWXoAAAAJ&hl=en
https://sagnikmukherjee.github.io
https://scholar.google.com/citations?user=v4lvWXoAAAAJ&hl=en
Reposted by Sagnik Mukherjee

Reinforcement Learning Finetunes Small Subnetworks in Large Language Models by @sagnikmukherjee.bsky.social, Lifan Yuan, @dilekh.bsky.social, Hao Peng
Read more here: arxiv.org/abs/2505.11711
x.com/saagnikkk/st...
Read more here: arxiv.org/abs/2505.11711
x.com/saagnikkk/st...

Reinforcement Learning Finetunes Small Subnetworks in Large Language Models
Reinforcement learning (RL) yields substantial improvements in large language models (LLMs) downstream task performance and alignment with human values. Surprisingly, such large gains result from upda...
arxiv.org
September 20, 2025 at 3:17 PM
Reinforcement Learning Finetunes Small Subnetworks in Large Language Models by @sagnikmukherjee.bsky.social, Lifan Yuan, @dilekh.bsky.social, Hao Peng
Read more here: arxiv.org/abs/2505.11711
x.com/saagnikkk/st...
Read more here: arxiv.org/abs/2505.11711
x.com/saagnikkk/st...
Paper - arxiv.org/abs/2505.11711
Work done with amazing collaborator Lifan Yuan, and advised by our amazing advisors @dilekh.bsky.social and Hao Peng.
Work done with amazing collaborator Lifan Yuan, and advised by our amazing advisors @dilekh.bsky.social and Hao Peng.

Reinforcement Learning Finetunes Small Subnetworks in Large Language Models
Reinforcement learning (RL) yields substantial improvements in large language models (LLMs) downstream task performance and alignment with human values. Surprisingly, such large gains result from upda...
arxiv.org
May 21, 2025 at 3:50 AM
Paper - arxiv.org/abs/2505.11711
Work done with amazing collaborator Lifan Yuan, and advised by our amazing advisors @dilekh.bsky.social and Hao Peng.
Work done with amazing collaborator Lifan Yuan, and advised by our amazing advisors @dilekh.bsky.social and Hao Peng.
🧵[8/n] To the best of our knowledge this is the first mechanistic evidence that shows contrast between learning from in distribution (or on-policy) data vs Off Distribution (off-policy) data.
May 21, 2025 at 3:50 AM
🧵[8/n] To the best of our knowledge this is the first mechanistic evidence that shows contrast between learning from in distribution (or on-policy) data vs Off Distribution (off-policy) data.
🧵[7/n]
🔍 Potential Reasons
💡 We hypothesize that the in-distribution nature of training data is a key driver behind this sparsity
🧠 The model already "knows" a lot — RL just fine-tunes a small, relevant subnetwork rather than overhauling everything
🔍 Potential Reasons
💡 We hypothesize that the in-distribution nature of training data is a key driver behind this sparsity
🧠 The model already "knows" a lot — RL just fine-tunes a small, relevant subnetwork rather than overhauling everything

May 21, 2025 at 3:50 AM
🧵[7/n]
🔍 Potential Reasons
💡 We hypothesize that the in-distribution nature of training data is a key driver behind this sparsity
🧠 The model already "knows" a lot — RL just fine-tunes a small, relevant subnetwork rather than overhauling everything
🔍 Potential Reasons
💡 We hypothesize that the in-distribution nature of training data is a key driver behind this sparsity
🧠 The model already "knows" a lot — RL just fine-tunes a small, relevant subnetwork rather than overhauling everything
🧵[6/n]
🌐 The Subnetwork Is General
🔁 Subnetworks trained with different seed, datasets, or even algorithms show nontrivial overlap
🧩 Suggests the subnetwork is a generalizable structure tied to the base model
🧠 A shared backbone seems to emerge, no matter how you train it
🌐 The Subnetwork Is General
🔁 Subnetworks trained with different seed, datasets, or even algorithms show nontrivial overlap
🧩 Suggests the subnetwork is a generalizable structure tied to the base model
🧠 A shared backbone seems to emerge, no matter how you train it

May 21, 2025 at 3:50 AM
🧵[6/n]
🌐 The Subnetwork Is General
🔁 Subnetworks trained with different seed, datasets, or even algorithms show nontrivial overlap
🧩 Suggests the subnetwork is a generalizable structure tied to the base model
🧠 A shared backbone seems to emerge, no matter how you train it
🌐 The Subnetwork Is General
🔁 Subnetworks trained with different seed, datasets, or even algorithms show nontrivial overlap
🧩 Suggests the subnetwork is a generalizable structure tied to the base model
🧠 A shared backbone seems to emerge, no matter how you train it
🧵[5/n]📊
🧪 Training the Subnetwork Reproduces Full Model
1️⃣ When trained in isolation, the sparse subnetwork recovers almost the exact same weights as the full model
2️⃣ achieves comparable (or better) end-task performance
3️⃣ 🧮 Even the training loss converges more smoothly
🧪 Training the Subnetwork Reproduces Full Model
1️⃣ When trained in isolation, the sparse subnetwork recovers almost the exact same weights as the full model
2️⃣ achieves comparable (or better) end-task performance
3️⃣ 🧮 Even the training loss converges more smoothly


May 21, 2025 at 3:50 AM
🧵[5/n]📊
🧪 Training the Subnetwork Reproduces Full Model
1️⃣ When trained in isolation, the sparse subnetwork recovers almost the exact same weights as the full model
2️⃣ achieves comparable (or better) end-task performance
3️⃣ 🧮 Even the training loss converges more smoothly
🧪 Training the Subnetwork Reproduces Full Model
1️⃣ When trained in isolation, the sparse subnetwork recovers almost the exact same weights as the full model
2️⃣ achieves comparable (or better) end-task performance
3️⃣ 🧮 Even the training loss converges more smoothly
🧵[4/n]
📚 Each Layer Is Equally Sparse (or Dense)
📏 No specific layer or sublayer gets special treatment — all layers are updated equally sparsely.
🎯Despite the sparsity, the updates are still full-rank
📚 Each Layer Is Equally Sparse (or Dense)
📏 No specific layer or sublayer gets special treatment — all layers are updated equally sparsely.
🎯Despite the sparsity, the updates are still full-rank

May 21, 2025 at 3:50 AM
🧵[4/n]
📚 Each Layer Is Equally Sparse (or Dense)
📏 No specific layer or sublayer gets special treatment — all layers are updated equally sparsely.
🎯Despite the sparsity, the updates are still full-rank
📚 Each Layer Is Equally Sparse (or Dense)
📏 No specific layer or sublayer gets special treatment — all layers are updated equally sparsely.
🎯Despite the sparsity, the updates are still full-rank
🧵[3/n]
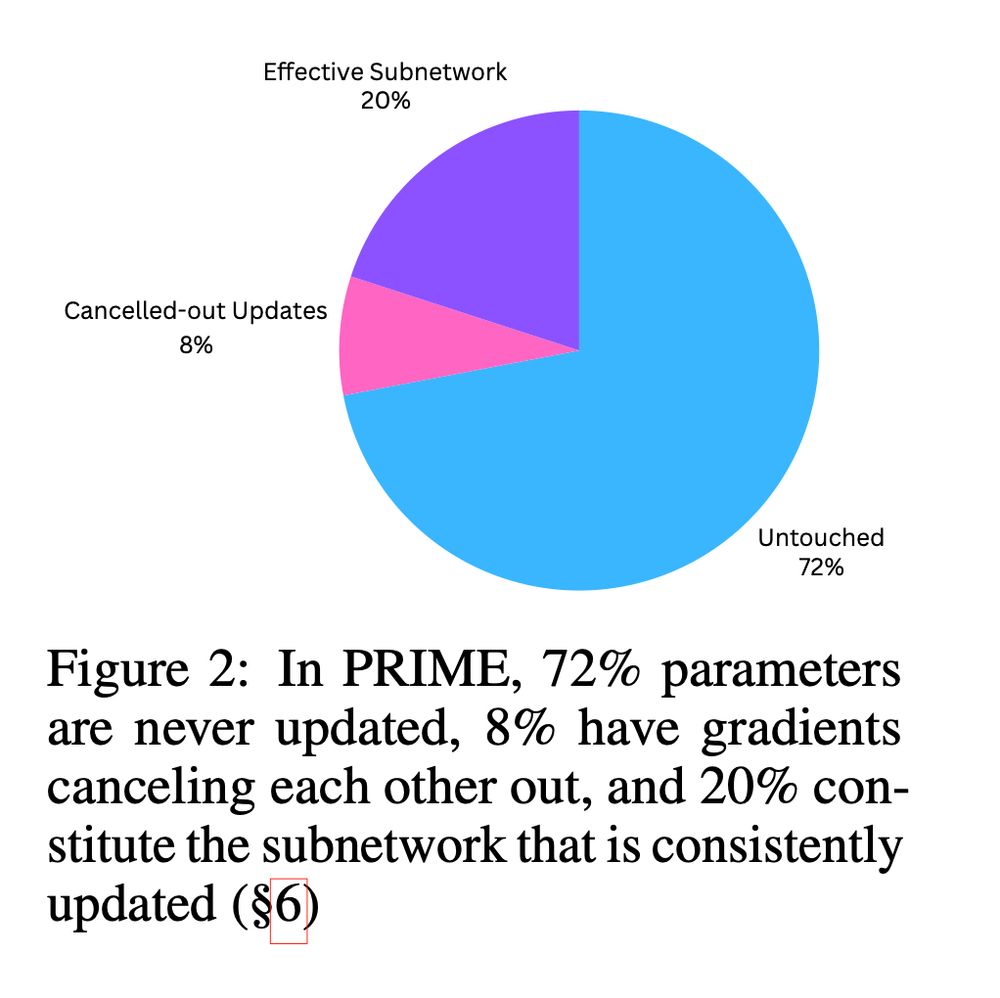
📉 Even Gradients Are Sparse in RL 📉
🧠 In PRIME, 72% of parameters never receive any gradient — ever!
↔️ Some do, but their gradients cancel out over time.
🎯 It’s not just sparse updates, even the gradients are sparse
📉 Even Gradients Are Sparse in RL 📉
🧠 In PRIME, 72% of parameters never receive any gradient — ever!
↔️ Some do, but their gradients cancel out over time.
🎯 It’s not just sparse updates, even the gradients are sparse
May 21, 2025 at 3:50 AM
🧵[3/n]
📉 Even Gradients Are Sparse in RL 📉
🧠 In PRIME, 72% of parameters never receive any gradient — ever!
↔️ Some do, but their gradients cancel out over time.
🎯 It’s not just sparse updates, even the gradients are sparse
📉 Even Gradients Are Sparse in RL 📉
🧠 In PRIME, 72% of parameters never receive any gradient — ever!
↔️ Some do, but their gradients cancel out over time.
🎯 It’s not just sparse updates, even the gradients are sparse
🧵[2/n]
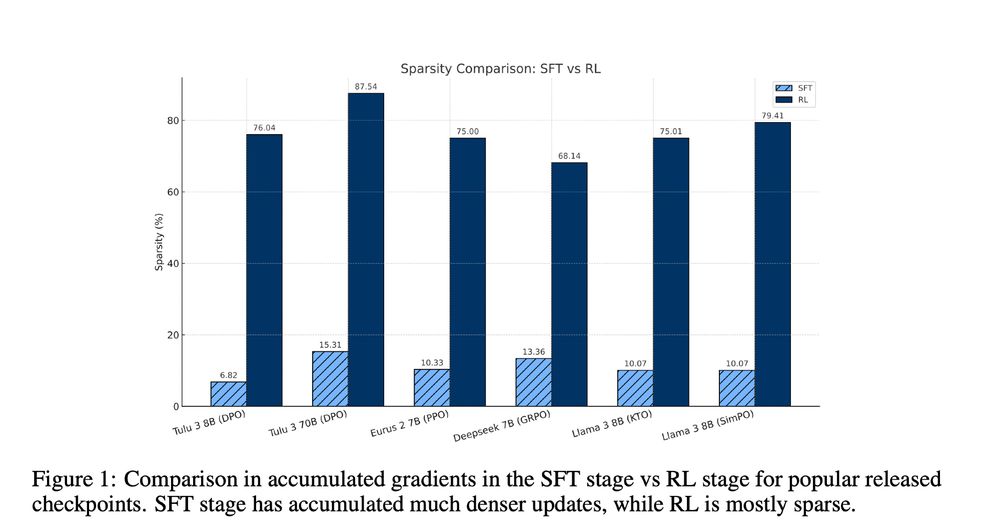
💡 SFT Updates Are Dense 💡
Unlike RL, Supervised Fine-Tuning (SFT) updates are much denser 🧠
📊 Sparsity is low — at most only 15.31% of parameters remain untouched.
💡 SFT Updates Are Dense 💡
Unlike RL, Supervised Fine-Tuning (SFT) updates are much denser 🧠
📊 Sparsity is low — at most only 15.31% of parameters remain untouched.
May 21, 2025 at 3:50 AM
🧵[2/n]
💡 SFT Updates Are Dense 💡
Unlike RL, Supervised Fine-Tuning (SFT) updates are much denser 🧠
📊 Sparsity is low — at most only 15.31% of parameters remain untouched.
💡 SFT Updates Are Dense 💡
Unlike RL, Supervised Fine-Tuning (SFT) updates are much denser 🧠
📊 Sparsity is low — at most only 15.31% of parameters remain untouched.

📂 Code and data coming soon! Read our paper here: arxiv.org/abs/2502.02362
This would not have been possible without the contributions of @abhinav-chinta.bsky.social @takyoung.bsky.social Tarun and our amazing advisor @dilekh.bsky.social Special thanks to the members of @convai-uiuc.bsky.social
This would not have been possible without the contributions of @abhinav-chinta.bsky.social @takyoung.bsky.social Tarun and our amazing advisor @dilekh.bsky.social Special thanks to the members of @convai-uiuc.bsky.social
May 7, 2025 at 6:52 PM
📂 Code and data coming soon! Read our paper here: arxiv.org/abs/2502.02362
This would not have been possible without the contributions of @abhinav-chinta.bsky.social @takyoung.bsky.social Tarun and our amazing advisor @dilekh.bsky.social Special thanks to the members of @convai-uiuc.bsky.social
This would not have been possible without the contributions of @abhinav-chinta.bsky.social @takyoung.bsky.social Tarun and our amazing advisor @dilekh.bsky.social Special thanks to the members of @convai-uiuc.bsky.social
🧠 Additional insights:
1️⃣ Spotting errors in synthetic negative samples is WAY easier than catching real-world mistakes
2️⃣ False positives are inflating math benchmark scores - time for more honest evaluation methods!
🧵[6/n]
1️⃣ Spotting errors in synthetic negative samples is WAY easier than catching real-world mistakes
2️⃣ False positives are inflating math benchmark scores - time for more honest evaluation methods!
🧵[6/n]
May 7, 2025 at 6:52 PM
🧠 Additional insights:
1️⃣ Spotting errors in synthetic negative samples is WAY easier than catching real-world mistakes
2️⃣ False positives are inflating math benchmark scores - time for more honest evaluation methods!
🧵[6/n]
1️⃣ Spotting errors in synthetic negative samples is WAY easier than catching real-world mistakes
2️⃣ False positives are inflating math benchmark scores - time for more honest evaluation methods!
🧵[6/n]
📈 Our results:
PARC improves error detection accuracy by 6-16%, enabling more reliable step-level verification in mathematical reasoning chains.
🧵[5/n]
PARC improves error detection accuracy by 6-16%, enabling more reliable step-level verification in mathematical reasoning chains.
🧵[5/n]

May 7, 2025 at 6:52 PM
📈 Our results:
PARC improves error detection accuracy by 6-16%, enabling more reliable step-level verification in mathematical reasoning chains.
🧵[5/n]
PARC improves error detection accuracy by 6-16%, enabling more reliable step-level verification in mathematical reasoning chains.
🧵[5/n]
📊 The exciting part?
LLMs can reliably identify these critical premises - the specific prior statements that directly support each reasoning step. This creates a transparent structure showing exactly which information is necessary for each conclusion.
🧵[4/n]
LLMs can reliably identify these critical premises - the specific prior statements that directly support each reasoning step. This creates a transparent structure showing exactly which information is necessary for each conclusion.
🧵[4/n]

May 7, 2025 at 6:52 PM
📊 The exciting part?
LLMs can reliably identify these critical premises - the specific prior statements that directly support each reasoning step. This creates a transparent structure showing exactly which information is necessary for each conclusion.
🧵[4/n]
LLMs can reliably identify these critical premises - the specific prior statements that directly support each reasoning step. This creates a transparent structure showing exactly which information is necessary for each conclusion.
🧵[4/n]
💡 Our solution:
We propose Premise-Augmented Reasoning Chains (PARC): converting linear reasoning into directed graphs by explicitly linking each reasoning step to its necessary premises.
We also propose accumulation errors, an error type ignored in prior work.
🧵[3/n]
We propose Premise-Augmented Reasoning Chains (PARC): converting linear reasoning into directed graphs by explicitly linking each reasoning step to its necessary premises.
We also propose accumulation errors, an error type ignored in prior work.
🧵[3/n]
May 7, 2025 at 6:52 PM
💡 Our solution:
We propose Premise-Augmented Reasoning Chains (PARC): converting linear reasoning into directed graphs by explicitly linking each reasoning step to its necessary premises.
We also propose accumulation errors, an error type ignored in prior work.
🧵[3/n]
We propose Premise-Augmented Reasoning Chains (PARC): converting linear reasoning into directed graphs by explicitly linking each reasoning step to its necessary premises.
We also propose accumulation errors, an error type ignored in prior work.
🧵[3/n]
📌 Issue: Verifying lengthy reasoning chains is tough due to hidden step dependencies. The current step doesn’t depend on all previous steps, making the context full of distractors.
🧵[2/n]
🧵[2/n]
May 7, 2025 at 6:52 PM
📌 Issue: Verifying lengthy reasoning chains is tough due to hidden step dependencies. The current step doesn’t depend on all previous steps, making the context full of distractors.
🧵[2/n]
🧵[2/n]
Work done with an amazing team (most of them are not here yet, other than @faridlazuarda.bsky.social )
November 21, 2024 at 10:03 PM
Work done with an amazing team (most of them are not here yet, other than @faridlazuarda.bsky.social )
We call out that most studies of culture has focused on a "thin" description.
"Digitally under-represented cultures are more likely to get represented by their “thin descriptions" created by “outsiders" on the digital space, which can further aggravate the biases and stereotypes."
"Digitally under-represented cultures are more likely to get represented by their “thin descriptions" created by “outsiders" on the digital space, which can further aggravate the biases and stereotypes."
November 21, 2024 at 10:03 PM
We call out that most studies of culture has focused on a "thin" description.
"Digitally under-represented cultures are more likely to get represented by their “thin descriptions" created by “outsiders" on the digital space, which can further aggravate the biases and stereotypes."
"Digitally under-represented cultures are more likely to get represented by their “thin descriptions" created by “outsiders" on the digital space, which can further aggravate the biases and stereotypes."
🚩 We discovered some key gaps: Incomplete cultural coverage, issues with methodological robustness, and a lack of situated studies for real-world applicability. These gaps limit our understanding of cultural biases in LLMs. [5/7]

November 21, 2024 at 10:03 PM
🚩 We discovered some key gaps: Incomplete cultural coverage, issues with methodological robustness, and a lack of situated studies for real-world applicability. These gaps limit our understanding of cultural biases in LLMs. [5/7]
📚 Most studies use black-box probing methods to examine LLMs' cultural biases. However, these methods can be sensitive to prompt wording, raising concerns about robustness and generalizability. [4/7]

November 21, 2024 at 10:03 PM
📚 Most studies use black-box probing methods to examine LLMs' cultural biases. However, these methods can be sensitive to prompt wording, raising concerns about robustness and generalizability. [4/7]