




Ruben C. Arslan
@ruben.the100.ci
Bayescurious evidence enthusiast at the100.ci
Topics: evolution, ovulation, mutation, intelligence, personality, sexuality, R, open science & source tools. https://rubenarslan.github.io/
Topics: evolution, ovulation, mutation, intelligence, personality, sexuality, R, open science & source tools. https://rubenarslan.github.io/
arxiv.org/pdf/2508.01390
have you seen this?
have you seen this?

November 18, 2025 at 9:47 PM
arxiv.org/pdf/2508.01390
have you seen this?
have you seen this?
18s gemini 3 pro. Also, maybe you could do better when you were an eight year old child, not sure this is generally true ;-)

November 18, 2025 at 9:01 PM
18s gemini 3 pro. Also, maybe you could do better when you were an eight year old child, not sure this is generally true ;-)
maybe we're talking past each other. with this minimal sim, the pgi-top-ranked is worse than a random pick 30% of the time. is this what you mean? I don't disagree with that. But you have to choose somehow, and random picking clearly does worse more often.

November 13, 2025 at 9:27 PM
maybe we're talking past each other. with this minimal sim, the pgi-top-ranked is worse than a random pick 30% of the time. is this what you mean? I don't disagree with that. But you have to choose somehow, and random picking clearly does worse more often.
how is this not putting the decision problem on the family level?


November 13, 2025 at 9:10 PM
how is this not putting the decision problem on the family level?
Great that you show the raw data, but it makes me wonder. Did you try modelling this as an ordinal outcome? Because the interaction effect looks like it could be fully explained by the item floor in ideation limiting variation at high levels of functioning. journals.sagepub.com/doi/10.1177/...

November 6, 2025 at 9:24 AM
Great that you show the raw data, but it makes me wonder. Did you try modelling this as an ordinal outcome? Because the interaction effect looks like it could be fully explained by the item floor in ideation limiting variation at high levels of functioning. journals.sagepub.com/doi/10.1177/...
I built a DAG diagram with garden hoses for teaching.
Pictured: a collider bias diagram, inspired by a blocked pipe situation I experienced (which I credit with giving me the intuition though it also ruined my belongings in the flooded cellar).
Pictured: a collider bias diagram, inspired by a blocked pipe situation I experienced (which I credit with giving me the intuition though it also ruined my belongings in the flooded cellar).

October 28, 2025 at 5:50 PM
I built a DAG diagram with garden hoses for teaching.
Pictured: a collider bias diagram, inspired by a blocked pipe situation I experienced (which I credit with giving me the intuition though it also ruined my belongings in the flooded cellar).
Pictured: a collider bias diagram, inspired by a blocked pipe situation I experienced (which I credit with giving me the intuition though it also ruined my belongings in the flooded cellar).
Ok, I gave it my best shot, though of course it depends on the pictures. Chocolates in a bowl wrapped or unwrapped etc.
![> library(tidyverse)
>
> squish <- function(x) {
+ x <- round(x)
+ x[x>7] <- 7
+ x[x<1] <- 1
+ x
+ }
> nonserious <- 0.1
> N <- 500
> dt <- tibble(
+ serious = sample(c(F, T), N, prob = c(nonserious, 1-nonserious), replace = T),
+ poop = if_else(serious, 1, sample(1:7, N, T)),
+ chocolate = if_else(serious, squish(rnorm(N, 6.5, sd = 0.5)), sample(1:7, N, T)),
+ )
>
> table(dt$serious)
FALSE TRUE
44 456
> hist(dt$poop)
> hist(dt$chocolate)
>
> effsize::cohen.d(dt$poop, dt$chocolate, paired = T)
Cohen's d
d estimate: -4.866682 (large)
95 percent confidence interval:
lower upper
-5.409463 -4.323901](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:rbamsrq5xdc25fdrmiicvi3f/bafkreicrqqglq4ezojlrdhg6ddzg4q4ho7xmyxfmjy3huadzmwhr2t6xnm@jpeg)
October 13, 2025 at 4:06 PM
Ok, I gave it my best shot, though of course it depends on the pictures. Chocolates in a bowl wrapped or unwrapped etc.
Our fragmentation paper is now finally out! I put some of the dumb quips that didn't make the cut in the alt texts.
journals.sagepub.com/doi/10.1177/...
journals.sagepub.com/doi/10.1177/...



September 29, 2025 at 10:37 AM
Our fragmentation paper is now finally out! I put some of the dumb quips that didn't make the cut in the alt texts.
journals.sagepub.com/doi/10.1177/...
journals.sagepub.com/doi/10.1177/...

I made a "bubble" quiz for my class. They got the frequency of veganism and smoking quite wrong, but were fairly good on frequency of "migration background" and "never travelled abroad" even though they were selected on those traits too.

July 11, 2025 at 6:56 AM
I made a "bubble" quiz for my class. They got the frequency of veganism and smoking quite wrong, but were fairly good on frequency of "migration background" and "never travelled abroad" even though they were selected on those traits too.
analysing judgments from this app whoknows.uni-muenster.de cross-classified by item, target and judge

July 10, 2025 at 1:25 PM
analysing judgments from this app whoknows.uni-muenster.de cross-classified by item, target and judge
New results from one of the few preregistered, placebo-controlled combined oral contraceptive RCTs. No pill effects found on preferences for masculine or symmetric faces, no menstrual cycle effects.
N=340, so small effects may have gone undetected.
www.sciencedirect.com/science/arti...
N=340, so small effects may have gone undetected.
www.sciencedirect.com/science/arti...

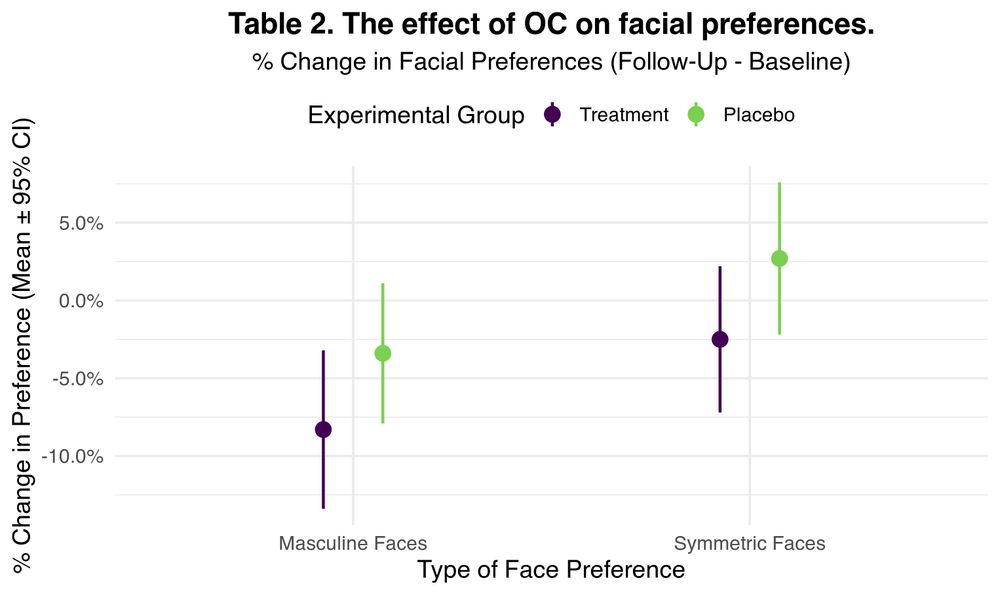
June 23, 2025 at 6:08 AM
New results from one of the few preregistered, placebo-controlled combined oral contraceptive RCTs. No pill effects found on preferences for masculine or symmetric faces, no menstrual cycle effects.
N=340, so small effects may have gone undetected.
www.sciencedirect.com/science/arti...
N=340, so small effects may have gone undetected.
www.sciencedirect.com/science/arti...
Interestingly, self report estimates are higher than more solidly grounded estimates according to the paper. Now, I don't trust this MDPI paper very much, it certainly has some dodgy plots (negative prevalences? I knew women's issues suffer from low visibility, but that's a bit much).

June 16, 2025 at 9:08 AM
Interestingly, self report estimates are higher than more solidly grounded estimates according to the paper. Now, I don't trust this MDPI paper very much, it certainly has some dodgy plots (negative prevalences? I knew women's issues suffer from low visibility, but that's a bit much).
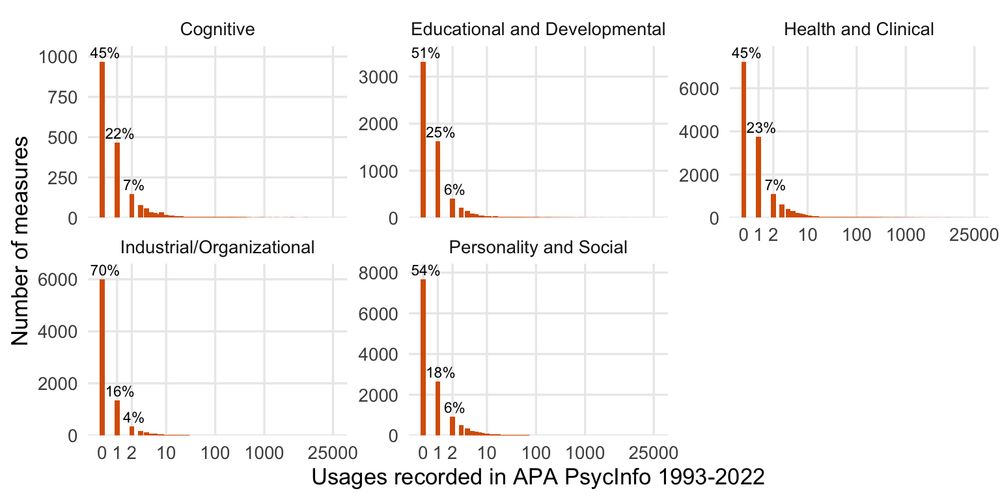
The absolute numbers go down when we lump revised and translated scales with the original. Abbreviations & changes are only split if some effort went into the abbreviation (i.e. a validated short form). All the ad hoc changes (especially for tasks like CRTT, IAT, IGT) are not catalogued/undercounted

June 13, 2025 at 11:53 AM
The absolute numbers go down when we lump revised and translated scales with the original. Abbreviations & changes are only split if some effort went into the abbreviation (i.e. a validated short form). All the ad hoc changes (especially for tasks like CRTT, IAT, IGT) are not catalogued/undercounted
There's a little interactive supplementary website for this paper. You can compare subdisciplines, e.g. I/O psych is more fragmented than educational, perhaps because IQ tests are harder to create ad hoc.
rubenarslan.github.io/construct_pr...
rubenarslan.github.io/construct_pr...
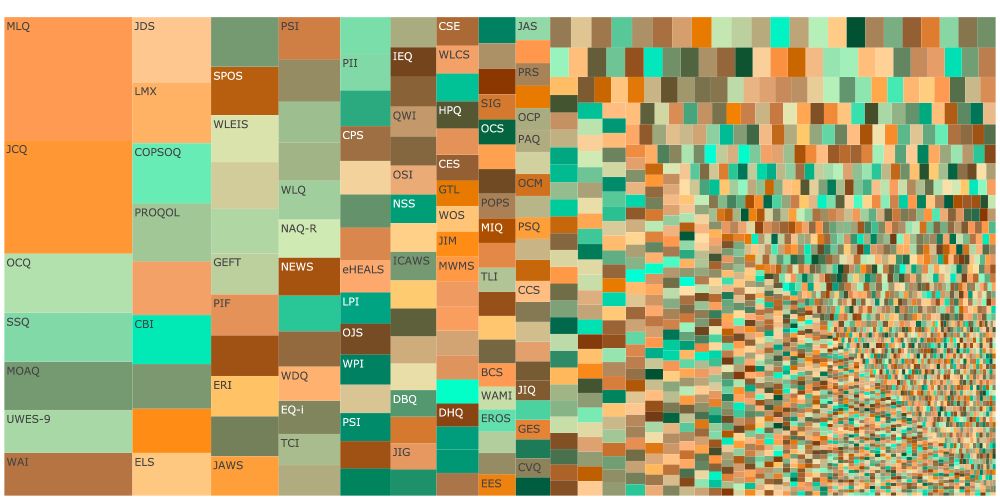

June 13, 2025 at 10:50 AM
There's a little interactive supplementary website for this paper. You can compare subdisciplines, e.g. I/O psych is more fragmented than educational, perhaps because IQ tests are harder to create ad hoc.
rubenarslan.github.io/construct_pr...
rubenarslan.github.io/construct_pr...
Now, 'funnily', using number of coded tests to normalize instead of number of distinct tests was exactly what I did in our first brief comment on the matter — which I then corrected because a) we had incorrectly described it and b) I thought it was more correct.
rubenarslan.github.io/mistakes.htm...
rubenarslan.github.io/mistakes.htm...

June 13, 2025 at 10:50 AM
Now, 'funnily', using number of coded tests to normalize instead of number of distinct tests was exactly what I did in our first brief comment on the matter — which I then corrected because a) we had incorrectly described it and b) I thought it was more correct.
rubenarslan.github.io/mistakes.htm...
rubenarslan.github.io/mistakes.htm...
We also ran a rarefaction simulation where we included a 25% of off-by-one errors because or hand recodings of the PsycInfo database showed quite a few such errors. But this doesn't seem to matter much.

June 13, 2025 at 10:50 AM
We also ran a rarefaction simulation where we included a 25% of off-by-one errors because or hand recodings of the PsycInfo database showed quite a few such errors. But this doesn't seem to matter much.
There are different efforts to equalize these numbers, but both focus on the number of individuals sampled rather than the number of distinct species (richness, which is biased by effort). We used rarefaction (downsampling) and equalization by asymptotic sample coverage.
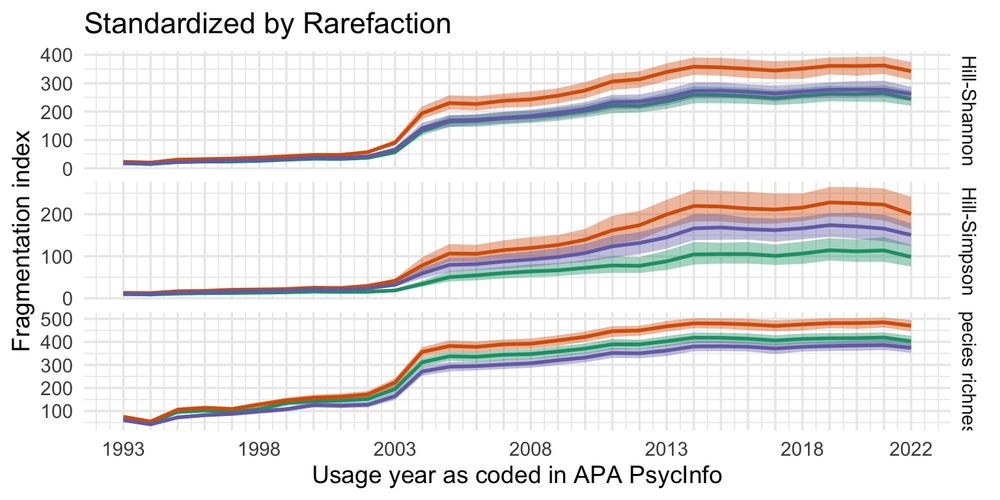

June 13, 2025 at 10:50 AM
There are different efforts to equalize these numbers, but both focus on the number of individuals sampled rather than the number of distinct species (richness, which is biased by effort). We used rarefaction (downsampling) and equalization by asymptotic sample coverage.
Ecologists now usually use Hill numbers, which are in the metric of number of species. Changes in Hill numbers are also more interpretable, though I wouldn't use the word 'intuitive'.

June 13, 2025 at 10:50 AM
Ecologists now usually use Hill numbers, which are in the metric of number of species. Changes in Hill numbers are also more interpretable, though I wouldn't use the word 'intuitive'.
Previously, we had focused on the number of distinct measures/constructs (a measure ecologists call "richness") and used Shannon entropy to quantify fragmentation. But richness is easily biased by differential effort (any rare species you don't find decreases the number) and entropy is not intuitive


June 13, 2025 at 10:50 AM
Previously, we had focused on the number of distinct measures/constructs (a measure ecologists call "richness") and used Shannon entropy to quantify fragmentation. But richness is easily biased by differential effort (any rare species you don't find decreases the number) and entropy is not intuitive
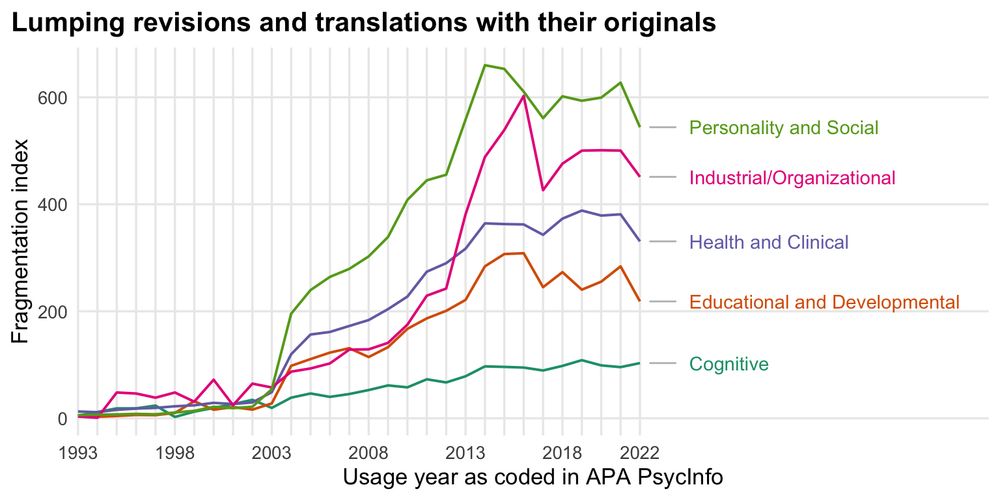
We could see this in the data, in 2016 the ~exponential growth stops. Screening out low effort contributions made sense to APA, but can we still infer how fragmentation changed when the database inclusion criteria changed so much?

June 13, 2025 at 10:50 AM
We could see this in the data, in 2016 the ~exponential growth stops. Screening out low effort contributions made sense to APA, but can we still infer how fragmentation changed when the database inclusion criteria changed so much?
We worked with an existing database based on codings by APA staff. We know little about the internal process, but they did, for example, let us know, that around 2016 they were overwhelmed by new measures (interesting itself!), so they increased standards for what would make it into the database.


June 13, 2025 at 10:50 AM
We worked with an existing database based on codings by APA staff. We know little about the internal process, but they did, for example, let us know, that around 2016 they were overwhelmed by new measures (interesting itself!), so they increased standards for what would make it into the database.
Our paper "A fragmented field" has just been accepted at AMPPS. We find it's not just you, psychology is really getting more confusing (construct and measure fragmentation is rising).
We updated the preprint with the (substantial) revision, please check it out.
osf.io/preprints/ps...
We updated the preprint with the (substantial) revision, please check it out.
osf.io/preprints/ps...
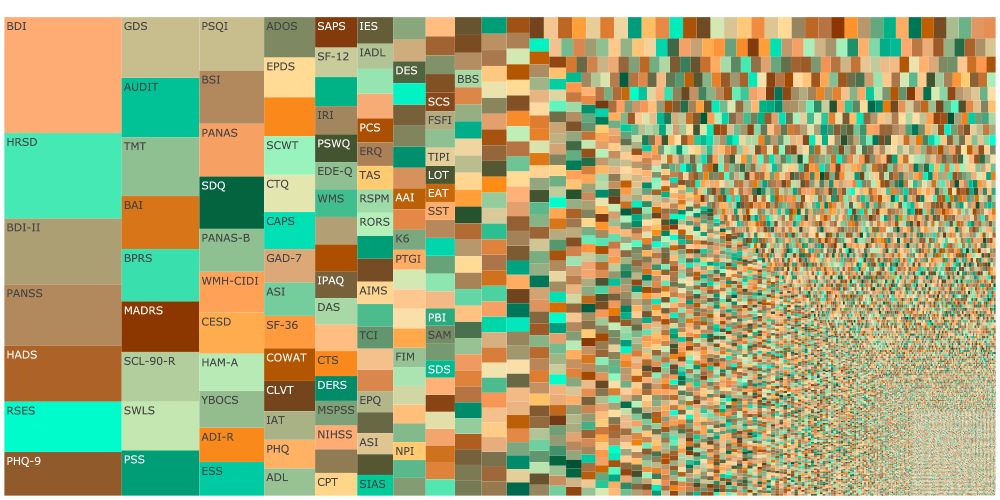
June 13, 2025 at 10:50 AM
Our paper "A fragmented field" has just been accepted at AMPPS. We find it's not just you, psychology is really getting more confusing (construct and measure fragmentation is rising).
We updated the preprint with the (substantial) revision, please check it out.
osf.io/preprints/ps...
We updated the preprint with the (substantial) revision, please check it out.
osf.io/preprints/ps...
Hadn't read this before and damn it goes hard.


May 26, 2025 at 6:42 AM
Hadn't read this before and damn it goes hard.
Compare this to the much weaker statements that they actually found evidence to back up and got consensus around. I don't find this actionable except in the classic way: more and especially better research is needed.

May 22, 2025 at 7:01 PM
Compare this to the much weaker statements that they actually found evidence to back up and got consensus around. I don't find this actionable except in the classic way: more and especially better research is needed.