




Robin Ranjit Singh Chauhan
@robinchauhan.bsky.social
Host TalkRL Podcast, Aspiring RL researcher
AgFunder VC Head of Eng, Ex-MSFT, Waterloo computer engineering
Sunshine Coast BC Canada
AgFunder VC Head of Eng, Ex-MSFT, Waterloo computer engineering
Sunshine Coast BC Canada
E71: Jake Beck, Alex Goldie, & Cornelius Braun on Sutton's OaK, Metalearning, LLMs, Squirrels at @rl-conference.bsky.social
A few thoughts with @jakeabeck.bsky.social, @alexgoldie.bsky.social and @corneliusbraun.bsky.social
after Rich Sutton's fascinating lecture on his OaK architecture at UofA
A few thoughts with @jakeabeck.bsky.social, @alexgoldie.bsky.social and @corneliusbraun.bsky.social
after Rich Sutton's fascinating lecture on his OaK architecture at UofA

August 26, 2025 at 5:42 AM
E71: Jake Beck, Alex Goldie, & Cornelius Braun on Sutton's OaK, Metalearning, LLMs, Squirrels at @rl-conference.bsky.social
A few thoughts with @jakeabeck.bsky.social, @alexgoldie.bsky.social and @corneliusbraun.bsky.social
after Rich Sutton's fascinating lecture on his OaK architecture at UofA
A few thoughts with @jakeabeck.bsky.social, @alexgoldie.bsky.social and @corneliusbraun.bsky.social
after Rich Sutton's fascinating lecture on his OaK architecture at UofA
E69: Thomas Akam on Model-based RL in the Brain
@ox.ac.uk neuroscientist Prof Akam on RL in brains vs machines, dopamine as TD-error (or not), hippocampal replay & Dyna, model-free vs model-based myths, and why ML experts should consider neuroscience careers.
@ox.ac.uk neuroscientist Prof Akam on RL in brains vs machines, dopamine as TD-error (or not), hippocampal replay & Dyna, model-free vs model-based myths, and why ML experts should consider neuroscience careers.

August 26, 2025 at 5:38 AM
E69: Thomas Akam on Model-based RL in the Brain
@ox.ac.uk neuroscientist Prof Akam on RL in brains vs machines, dopamine as TD-error (or not), hippocampal replay & Dyna, model-free vs model-based myths, and why ML experts should consider neuroscience careers.
@ox.ac.uk neuroscientist Prof Akam on RL in brains vs machines, dopamine as TD-error (or not), hippocampal replay & Dyna, model-free vs model-based myths, and why ML experts should consider neuroscience careers.
E67: Stefano Albrecht on Multi-Agent RL @ RLDM 2025
Stefano Albrecht shares the story behind his multi-agent RL textbook, and how DeepFlow AI turns these ideas into action with LLM-powered agents for business automation.
Recorded at
@rldmdublin2025.bsky.social
Stefano Albrecht shares the story behind his multi-agent RL textbook, and how DeepFlow AI turns these ideas into action with LLM-powered agents for business automation.
Recorded at
@rldmdublin2025.bsky.social

August 26, 2025 at 5:35 AM
E67: Stefano Albrecht on Multi-Agent RL @ RLDM 2025
Stefano Albrecht shares the story behind his multi-agent RL textbook, and how DeepFlow AI turns these ideas into action with LLM-powered agents for business automation.
Recorded at
@rldmdublin2025.bsky.social
Stefano Albrecht shares the story behind his multi-agent RL textbook, and how DeepFlow AI turns these ideas into action with LLM-powered agents for business automation.
Recorded at
@rldmdublin2025.bsky.social
Rich Sutton presenting his OaK architecture at @rl-conference.bsky.social


August 9, 2025 at 8:05 PM
Rich Sutton presenting his OaK architecture at @rl-conference.bsky.social
Volunteers 👏 @rl-conference.bsky.social

August 9, 2025 at 8:04 PM
Volunteers 👏 @rl-conference.bsky.social




Excited to be at RLC 2025!

August 5, 2025 at 12:52 AM
Excited to be at RLC 2025!
E66: Satinder Singh: The Origin Story of RLDM @ RLDM 2025
Professor Satinder Singh of Google DeepMind and U of Michigan is co-founder of @rldmdublin2025.bsky.social
Here he narrates the origin story of the Reinforcement Learning and Decision Making meeting (not conference).
Professor Satinder Singh of Google DeepMind and U of Michigan is co-founder of @rldmdublin2025.bsky.social
Here he narrates the origin story of the Reinforcement Learning and Decision Making meeting (not conference).

June 25, 2025 at 4:33 PM
E66: Satinder Singh: The Origin Story of RLDM @ RLDM 2025
Professor Satinder Singh of Google DeepMind and U of Michigan is co-founder of @rldmdublin2025.bsky.social
Here he narrates the origin story of the Reinforcement Learning and Decision Making meeting (not conference).
Professor Satinder Singh of Google DeepMind and U of Michigan is co-founder of @rldmdublin2025.bsky.social
Here he narrates the origin story of the Reinforcement Learning and Decision Making meeting (not conference).
TalkRL Podcast at @rldmdublin2025.bsky.social in Dublin Ireland!




June 12, 2025 at 4:45 PM
TalkRL Podcast at @rldmdublin2025.bsky.social in Dublin Ireland!
Excited to attend my first RLDM! (fomo from missing the past 2). Would love to say hi -- and will be looking for Talk RL Podcast interviews 🌸🍒🌸

Register NOW and save €100 off your registration fee!
Fees will increase by €100 on April 1st.
Looking forward to seeing you all in June! #RLDM2025
Fees will increase by €100 on April 1st.
Looking forward to seeing you all in June! #RLDM2025

May 4, 2025 at 8:59 PM
Excited to attend my first RLDM! (fomo from missing the past 2). Would love to say hi -- and will be looking for Talk RL Podcast interviews 🌸🍒🌸
Reposted by Robin Ranjit Singh Chauhan

"I'm going to govern in econometrics" is a winning campaign slogan for the ages.

April 29, 2025 at 2:59 AM
"I'm going to govern in econometrics" is a winning campaign slogan for the ages.
E65: NeurIPS 2024 – Posters and Hallways 3
- Claire Bizon Monroc of Inria : WFCRL for Wind Farm Control
Andrew Wagenmaker of @ucberkeleyofficial.bsky.social : Leveraging Simulation to Bridge Sim-to-Real Gap
- @harwiltz.bsky.social of @mila-quebec.bsky.social : Multivariate Distributional RL
(cont)
- Claire Bizon Monroc of Inria : WFCRL for Wind Farm Control
Andrew Wagenmaker of @ucberkeleyofficial.bsky.social : Leveraging Simulation to Bridge Sim-to-Real Gap
- @harwiltz.bsky.social of @mila-quebec.bsky.social : Multivariate Distributional RL
(cont)

March 10, 2025 at 5:21 PM
E65: NeurIPS 2024 – Posters and Hallways 3
- Claire Bizon Monroc of Inria : WFCRL for Wind Farm Control
Andrew Wagenmaker of @ucberkeleyofficial.bsky.social : Leveraging Simulation to Bridge Sim-to-Real Gap
- @harwiltz.bsky.social of @mila-quebec.bsky.social : Multivariate Distributional RL
(cont)
- Claire Bizon Monroc of Inria : WFCRL for Wind Farm Control
Andrew Wagenmaker of @ucberkeleyofficial.bsky.social : Leveraging Simulation to Bridge Sim-to-Real Gap
- @harwiltz.bsky.social of @mila-quebec.bsky.social : Multivariate Distributional RL
(cont)
BSKY
E64: NeurIPS 2024 – Posters and Hallways 2
- Jonathan Cook of Oxford: Cultural Accumulation in Reinforcement Learning
- Yifei Zhou of Berkeley AI Research: DigiRL for In-The-Wild Device-Control Agents
- Rory Young of U Glasgow: A Lyapunov Exponent Approach to RL Robustness
(cont'd)
E64: NeurIPS 2024 – Posters and Hallways 2
- Jonathan Cook of Oxford: Cultural Accumulation in Reinforcement Learning
- Yifei Zhou of Berkeley AI Research: DigiRL for In-The-Wild Device-Control Agents
- Rory Young of U Glasgow: A Lyapunov Exponent Approach to RL Robustness
(cont'd)

March 6, 2025 at 5:09 AM
BSKY
E64: NeurIPS 2024 – Posters and Hallways 2
- Jonathan Cook of Oxford: Cultural Accumulation in Reinforcement Learning
- Yifei Zhou of Berkeley AI Research: DigiRL for In-The-Wild Device-Control Agents
- Rory Young of U Glasgow: A Lyapunov Exponent Approach to RL Robustness
(cont'd)
E64: NeurIPS 2024 – Posters and Hallways 2
- Jonathan Cook of Oxford: Cultural Accumulation in Reinforcement Learning
- Yifei Zhou of Berkeley AI Research: DigiRL for In-The-Wild Device-Control Agents
- Rory Young of U Glasgow: A Lyapunov Exponent Approach to RL Robustness
(cont'd)
E63: NeurIPS 2024 - Posters and Hallways 1
Jiaheng Hu of UTexas on Unsupervised Skill Discovery for HRL
@skandermoalla.bsky.social of EPFL: Representation and Trust in PPO
Adil Zouitine of IRT Saint Exupery/Hugging Face : Time-Constrained Robust MDPs
Jiaheng Hu of UTexas on Unsupervised Skill Discovery for HRL
@skandermoalla.bsky.social of EPFL: Representation and Trust in PPO
Adil Zouitine of IRT Saint Exupery/Hugging Face : Time-Constrained Robust MDPs
March 3, 2025 at 2:06 PM
E63: NeurIPS 2024 - Posters and Hallways 1
Jiaheng Hu of UTexas on Unsupervised Skill Discovery for HRL
@skandermoalla.bsky.social of EPFL: Representation and Trust in PPO
Adil Zouitine of IRT Saint Exupery/Hugging Face : Time-Constrained Robust MDPs
Jiaheng Hu of UTexas on Unsupervised Skill Discovery for HRL
@skandermoalla.bsky.social of EPFL: Representation and Trust in PPO
Adil Zouitine of IRT Saint Exupery/Hugging Face : Time-Constrained Robust MDPs
The Posters and Hallways interviews from Neurips 2024 got delayed, bigly - mea culpa! Promising to publish faster from now on. (Each calendar week being like a year in AI and all).
More cool guests incoming...
More cool guests incoming...
March 3, 2025 at 1:59 PM
The Posters and Hallways interviews from Neurips 2024 got delayed, bigly - mea culpa! Promising to publish faster from now on. (Each calendar week being like a year in AI and all).
More cool guests incoming...
More cool guests incoming...
E62: Abhishek Naik on Continuing RL & Average Reward
How should RL handle non-episodic tasks, like Mars rovers or HPC scheduling? @abhisheknaik96.bsky.social shares insights from his PhD with Rich Sutton, plus how almost every discounted-reward algorithm can be improved by reward centering.
How should RL handle non-episodic tasks, like Mars rovers or HPC scheduling? @abhisheknaik96.bsky.social shares insights from his PhD with Rich Sutton, plus how almost every discounted-reward algorithm can be improved by reward centering.

February 10, 2025 at 4:35 PM
E62: Abhishek Naik on Continuing RL & Average Reward
How should RL handle non-episodic tasks, like Mars rovers or HPC scheduling? @abhisheknaik96.bsky.social shares insights from his PhD with Rich Sutton, plus how almost every discounted-reward algorithm can be improved by reward centering.
How should RL handle non-episodic tasks, like Mars rovers or HPC scheduling? @abhisheknaik96.bsky.social shares insights from his PhD with Rich Sutton, plus how almost every discounted-reward algorithm can be improved by reward centering.
Reposted by Robin Ranjit Singh Chauhan

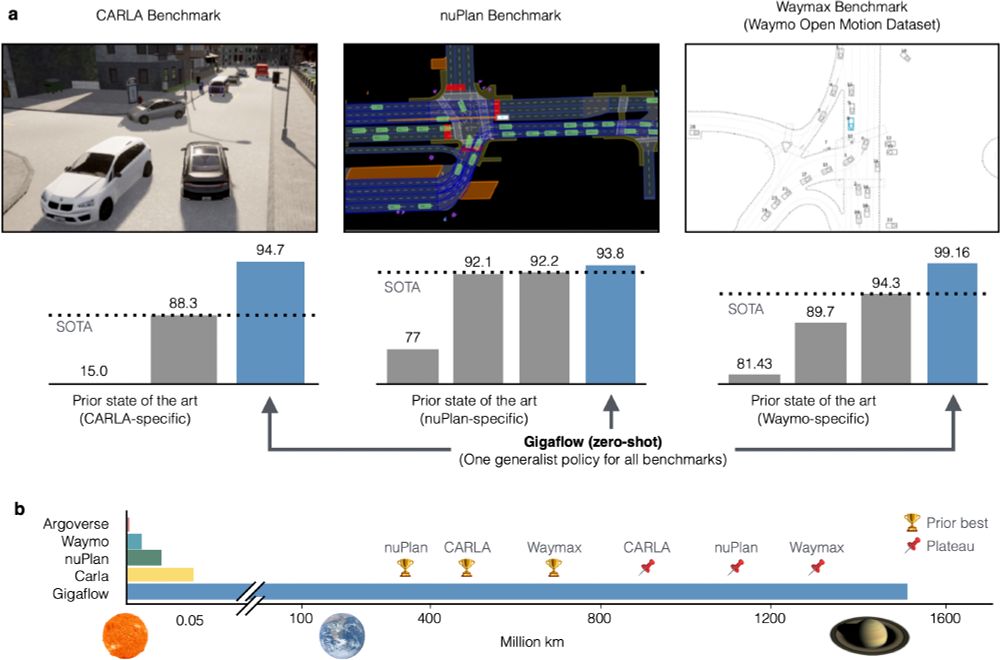
We've built a simulated driving agent that we trained on 1.6 billion km of driving with no human data.
It is SOTA on every planning benchmark we tried.
In self-play, it goes 20 years between collisions.
It is SOTA on every planning benchmark we tried.
In self-play, it goes 20 years between collisions.
February 6, 2025 at 6:34 PM
We've built a simulated driving agent that we trained on 1.6 billion km of driving with no human data.
It is SOTA on every planning benchmark we tried.
In self-play, it goes 20 years between collisions.
It is SOTA on every planning benchmark we tried.
In self-play, it goes 20 years between collisions.
Want a paid speaking gig at our AGM?
30 min talks on a deeptech topic incl:
- Mat Sci
- LLMs, RL, Agents, AI h/w
- Robotics
- Nanotech
- Energy
- Space
Seeking engaging speakers, ideally from Cali or nearby.
San Jose Convention Center Mon May 5 morning.
Please DM!
30 min talks on a deeptech topic incl:
- Mat Sci
- LLMs, RL, Agents, AI h/w
- Robotics
- Nanotech
- Energy
- Space
Seeking engaging speakers, ideally from Cali or nearby.
San Jose Convention Center Mon May 5 morning.
Please DM!
January 21, 2025 at 9:48 PM
Want a paid speaking gig at our AGM?
30 min talks on a deeptech topic incl:
- Mat Sci
- LLMs, RL, Agents, AI h/w
- Robotics
- Nanotech
- Energy
- Space
Seeking engaging speakers, ideally from Cali or nearby.
San Jose Convention Center Mon May 5 morning.
Please DM!
30 min talks on a deeptech topic incl:
- Mat Sci
- LLMs, RL, Agents, AI h/w
- Robotics
- Nanotech
- Energy
- Space
Seeking engaging speakers, ideally from Cali or nearby.
San Jose Convention Center Mon May 5 morning.
Please DM!
Reposted by Robin Ranjit Singh Chauhan

It’s scathing critique season, this time for reinforcement learning. We need this, the science cannot get better without it.
Usual suspects: training brittleness (over reliance on hyperparameter tuning), bad & slow sims, overemphasis on generality, LLMs dominating discourse, tabula rasa RL is hard
Usual suspects: training brittleness (over reliance on hyperparameter tuning), bad & slow sims, overemphasis on generality, LLMs dominating discourse, tabula rasa RL is hard
E61: Neurips 2024 RL meetup Hot takes: "What sucks about RL?"
What do RL researchers complain about after hours at the bar? In this "Hot takes" episode, we find out!
Recorded at The Pearl in downtown Vancouver, during the RL meetup after a day of Neurips 2024.
What do RL researchers complain about after hours at the bar? In this "Hot takes" episode, we find out!
Recorded at The Pearl in downtown Vancouver, during the RL meetup after a day of Neurips 2024.

December 25, 2024 at 11:21 PM
It’s scathing critique season, this time for reinforcement learning. We need this, the science cannot get better without it.
Usual suspects: training brittleness (over reliance on hyperparameter tuning), bad & slow sims, overemphasis on generality, LLMs dominating discourse, tabula rasa RL is hard
Usual suspects: training brittleness (over reliance on hyperparameter tuning), bad & slow sims, overemphasis on generality, LLMs dominating discourse, tabula rasa RL is hard
E61: Neurips 2024 RL meetup Hot takes: "What sucks about RL?"
What do RL researchers complain about after hours at the bar? In this "Hot takes" episode, we find out!
Recorded at The Pearl in downtown Vancouver, during the RL meetup after a day of Neurips 2024.
What do RL researchers complain about after hours at the bar? In this "Hot takes" episode, we find out!
Recorded at The Pearl in downtown Vancouver, during the RL meetup after a day of Neurips 2024.
December 25, 2024 at 4:50 PM
E61: Neurips 2024 RL meetup Hot takes: "What sucks about RL?"
What do RL researchers complain about after hours at the bar? In this "Hot takes" episode, we find out!
Recorded at The Pearl in downtown Vancouver, during the RL meetup after a day of Neurips 2024.
What do RL researchers complain about after hours at the bar? In this "Hot takes" episode, we find out!
Recorded at The Pearl in downtown Vancouver, during the RL meetup after a day of Neurips 2024.
Reposted by Robin Ranjit Singh Chauhan

If you're at NeurIPS, RLC is hosting an RL event from 8 till late at The Pearl on Dec. 11th. Join us, meet all the RL researchers, and spread the word!
December 10, 2024 at 9:55 PM
If you're at NeurIPS, RLC is hosting an RL event from 8 till late at The Pearl on Dec. 11th. Join us, meet all the RL researchers, and spread the word!
Reposted by Robin Ranjit Singh Chauhan
Trying to slowly populate the RL list here, help me out: go.bsky.app/3WPHcHg
September 14, 2024 at 8:53 PM
Trying to slowly populate the RL list here, help me out: go.bsky.app/3WPHcHg
Latest episode includes 7 short conversations with poster presenters at RLC
podcasts.apple.com/ca/podcast/r...
podcasts.apple.com/ca/podcast/r...

RLC 2024 - Posters and Hallways 2
Posters and Hallway episodes are short interviews and poster summaries. Recorded at RLC 2024 in Amherst MA.
Featuring:
0:01 Hector Kohler from Centre Inria
podcasts.apple.com
September 17, 2024 at 12:45 AM
Latest episode includes 7 short conversations with poster presenters at RLC
podcasts.apple.com/ca/podcast/r...
podcasts.apple.com/ca/podcast/r...