



Prasann Singhal
@prasannsinghal.bsky.social
Undergrad NLP researcher at UT Austin, working with Greg Durrett
Reposted by Prasann Singhal

News🗞️
I will return to UT Austin as an Assistant Professor of Linguistics this fall, and join its vibrant community of Computational Linguists, NLPers, and Cognitive Scientists!🤘
Excited to develop ideas about linguistic and conceptual generalization (recruitment details soon!)
I will return to UT Austin as an Assistant Professor of Linguistics this fall, and join its vibrant community of Computational Linguists, NLPers, and Cognitive Scientists!🤘
Excited to develop ideas about linguistic and conceptual generalization (recruitment details soon!)

June 2, 2025 at 1:18 PM
News🗞️
I will return to UT Austin as an Assistant Professor of Linguistics this fall, and join its vibrant community of Computational Linguists, NLPers, and Cognitive Scientists!🤘
Excited to develop ideas about linguistic and conceptual generalization (recruitment details soon!)
I will return to UT Austin as an Assistant Professor of Linguistics this fall, and join its vibrant community of Computational Linguists, NLPers, and Cognitive Scientists!🤘
Excited to develop ideas about linguistic and conceptual generalization (recruitment details soon!)
Reposted by Prasann Singhal

Check out @juand-r.bsky.social and @wenxuand.bsky.social 's work on improving generator-validator gaps in LLMs! I really like the formulation of the G-V gap we present, and I was pleasantly surprised by how well the ranking-based training closed the gap. Looking forward to following up in this area!

One of the ways that LLMs can be inconsistent is the "generator-validator gap," where LLMs deem their own answers incorrect.
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇


April 16, 2025 at 6:18 PM
Check out @juand-r.bsky.social and @wenxuand.bsky.social 's work on improving generator-validator gaps in LLMs! I really like the formulation of the G-V gap we present, and I was pleasantly surprised by how well the ranking-based training closed the gap. Looking forward to following up in this area!
Reposted by Prasann Singhal
Check out Ramya et al.'s work on understanding discourse similarities in LLM-generated text! We see this as an important step in quantifying the "sameyness" of LLM text, which we think will be a step towards fixing it!

Have that eerie feeling of déjà vu when reading model-generated text 👀, but can’t pinpoint the specific words or phrases 👀?
✨We introduce QUDsim, to quantify discourse similarities beyond lexical, syntactic, and content overlap.
✨We introduce QUDsim, to quantify discourse similarities beyond lexical, syntactic, and content overlap.


April 21, 2025 at 10:10 PM
Check out Ramya et al.'s work on understanding discourse similarities in LLM-generated text! We see this as an important step in quantifying the "sameyness" of LLM text, which we think will be a step towards fixing it!
Reposted by Prasann Singhal
Check out Manya's work on evaluation for open-ended tasks! The criteria from EvalAgent can be plugged into LLM-as-a-judge or used for refinement. Great tool with a ton of potential, and there's LOTS to do here for making LLMs better at writing!

Evaluating language model responses on open-ended tasks is hard! 🤔
We introduce EvalAgent, a framework that identifies nuanced and diverse criteria 📋✍️.
EvalAgent identifies 👩🏫🎓 expert advice on the web that implicitly address the user’s prompt 🧵👇
We introduce EvalAgent, a framework that identifies nuanced and diverse criteria 📋✍️.
EvalAgent identifies 👩🏫🎓 expert advice on the web that implicitly address the user’s prompt 🧵👇

April 22, 2025 at 4:30 PM
Check out Manya's work on evaluation for open-ended tasks! The criteria from EvalAgent can be plugged into LLM-as-a-judge or used for refinement. Great tool with a ton of potential, and there's LOTS to do here for making LLMs better at writing!
Reposted by Prasann Singhal

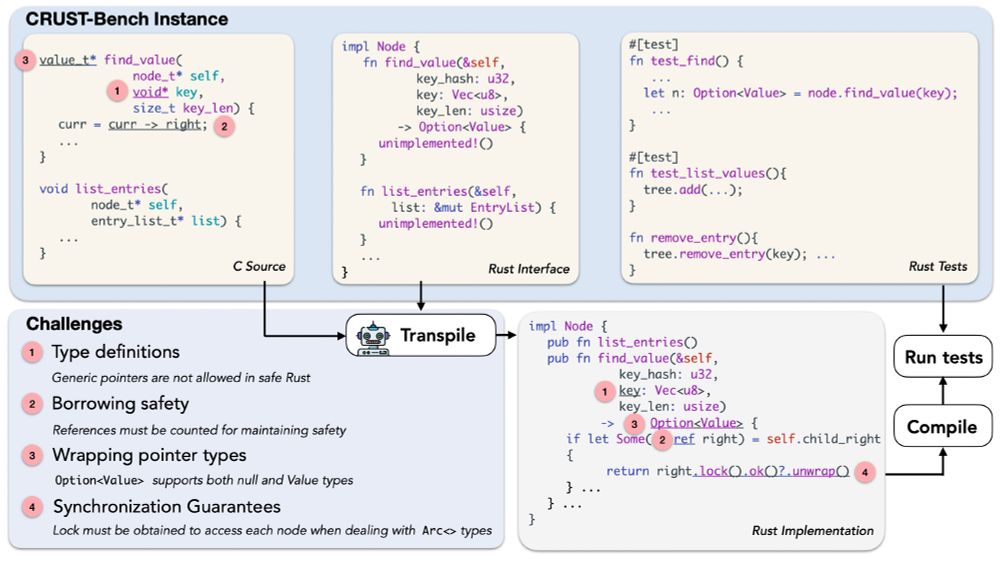
🚀Meet CRUST-Bench, a dataset for C-to-Rust transpilation for full codebases 🛠️
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6]
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6]

April 23, 2025 at 5:00 PM
🚀Meet CRUST-Bench, a dataset for C-to-Rust transpilation for full codebases 🛠️
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6]
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6]
Reposted by Prasann Singhal
Check out Anirudh's work on a new benchmark for C-to-Rust transpilation! 100 realistic-scale C projects, plus target Rust interfaces + Rust tests that let us validate the transpiled code beyond what prior benchmarks allow.
🚀Meet CRUST-Bench, a dataset for C-to-Rust transpilation for full codebases 🛠️
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6]
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6]
April 23, 2025 at 6:37 PM
Check out Anirudh's work on a new benchmark for C-to-Rust transpilation! 100 realistic-scale C projects, plus target Rust interfaces + Rust tests that let us validate the transpiled code beyond what prior benchmarks allow.
Reposted by Prasann Singhal

We got an 🥂 Outstanding Paper Award!! Cannot be more grateful 🥹 This is super validating for our long pursuit of computational work on QUD.
Congrats to the amazing @yatingwu.bsky.social, Ritika Mangla, Alex Dimakis, @gregdnlp.bsky.social
Congrats to the amazing @yatingwu.bsky.social, Ritika Mangla, Alex Dimakis, @gregdnlp.bsky.social
Wednesday at #EMNLP: @yatingwu.bsky.social will present our work connecting curiosity and questions in discourse. We built strong models to predict salience, outperforming large LLMs.
👉[Oral] Discourse+Phonology+Syntax2 10:30-12:00 @ Flagler
also w/ Ritika Mangla @gregdnlp.bsky.social Alex Dimakis
👉[Oral] Discourse+Phonology+Syntax2 10:30-12:00 @ Flagler
also w/ Ritika Mangla @gregdnlp.bsky.social Alex Dimakis

November 15, 2024 at 1:12 PM
We got an 🥂 Outstanding Paper Award!! Cannot be more grateful 🥹 This is super validating for our long pursuit of computational work on QUD.
Congrats to the amazing @yatingwu.bsky.social, Ritika Mangla, Alex Dimakis, @gregdnlp.bsky.social
Congrats to the amazing @yatingwu.bsky.social, Ritika Mangla, Alex Dimakis, @gregdnlp.bsky.social