



Greg Durrett
@gregdnlp.bsky.social
CS professor at NYU. Large language models and NLP. he/him
Still accepting applications for this postdoc position in my lab at NYU! Applications due Feb 1. Please see the posting below for more information and apply on Interfolio:
cims.nyu.edu/taur/postdoc...
apply.interfolio.com/178940
cims.nyu.edu/taur/postdoc...
apply.interfolio.com/178940
January 12, 2026 at 3:14 PM
Still accepting applications for this postdoc position in my lab at NYU! Applications due Feb 1. Please see the posting below for more information and apply on Interfolio:
cims.nyu.edu/taur/postdoc...
apply.interfolio.com/178940
cims.nyu.edu/taur/postdoc...
apply.interfolio.com/178940
Submit to COLM! Deadline of March 31. This llama gets to enjoy his holidays and isn't stressed out just yet...

COLM 2026 is just around the corner! Mark your calendars for:
💡 Abstract deadline: Thursday, March 26, 2026
📄 Full paper submission deadline: Tuesday, March 31, 2026
Call for papers (website coming soon):
docs.google.com/document/d/1...
💡 Abstract deadline: Thursday, March 26, 2026
📄 Full paper submission deadline: Tuesday, March 31, 2026
Call for papers (website coming soon):
docs.google.com/document/d/1...

December 16, 2025 at 3:36 PM
Submit to COLM! Deadline of March 31. This llama gets to enjoy his holidays and isn't stressed out just yet...
Reposted by Greg Durrett

Hiring researchers & engineers to work on
–building reliable software on top of unreliable LLM primitives
–statistical evaluation of real-world deployments of LLM-based systems
I’m speaking about this on two NeurIPS workshop panels:
🗓️Saturday – Reliable ML Workshop
🗓️Sunday – LLM Evaluation Workshop
–building reliable software on top of unreliable LLM primitives
–statistical evaluation of real-world deployments of LLM-based systems
I’m speaking about this on two NeurIPS workshop panels:
🗓️Saturday – Reliable ML Workshop
🗓️Sunday – LLM Evaluation Workshop
December 2, 2025 at 2:55 PM
Hiring researchers & engineers to work on
–building reliable software on top of unreliable LLM primitives
–statistical evaluation of real-world deployments of LLM-based systems
I’m speaking about this on two NeurIPS workshop panels:
🗓️Saturday – Reliable ML Workshop
🗓️Sunday – LLM Evaluation Workshop
–building reliable software on top of unreliable LLM primitives
–statistical evaluation of real-world deployments of LLM-based systems
I’m speaking about this on two NeurIPS workshop panels:
🗓️Saturday – Reliable ML Workshop
🗓️Sunday – LLM Evaluation Workshop
📢 Postdoc position 📢
I’m recruiting a postdoc for my lab at NYU! Topics include LM reasoning, creativity, limitations of scaling, AI for science, & more! Apply by Feb 1.
(Different from NYU Faculty Fellows, which are also great but less connected to my lab.)
Link in 🧵
I’m recruiting a postdoc for my lab at NYU! Topics include LM reasoning, creativity, limitations of scaling, AI for science, & more! Apply by Feb 1.
(Different from NYU Faculty Fellows, which are also great but less connected to my lab.)
Link in 🧵

December 2, 2025 at 4:04 PM
📢 Postdoc position 📢
I’m recruiting a postdoc for my lab at NYU! Topics include LM reasoning, creativity, limitations of scaling, AI for science, & more! Apply by Feb 1.
(Different from NYU Faculty Fellows, which are also great but less connected to my lab.)
Link in 🧵
I’m recruiting a postdoc for my lab at NYU! Topics include LM reasoning, creativity, limitations of scaling, AI for science, & more! Apply by Feb 1.
(Different from NYU Faculty Fellows, which are also great but less connected to my lab.)
Link in 🧵
Reposted by Greg Durrett

Two brief advertisements!
TTIC is recruiting both tenure-track and research assistant professors: ttic.edu/faculty-hiri...
NYU is recruiting faculty fellows: apply.interfolio.com/174686
Happy to chat with anyone considering either of these options
TTIC is recruiting both tenure-track and research assistant professors: ttic.edu/faculty-hiri...
NYU is recruiting faculty fellows: apply.interfolio.com/174686
Happy to chat with anyone considering either of these options
TTIC Faculty Opportunities at TTIC
ttic.edu
October 23, 2025 at 1:57 PM
Two brief advertisements!
TTIC is recruiting both tenure-track and research assistant professors: ttic.edu/faculty-hiri...
NYU is recruiting faculty fellows: apply.interfolio.com/174686
Happy to chat with anyone considering either of these options
TTIC is recruiting both tenure-track and research assistant professors: ttic.edu/faculty-hiri...
NYU is recruiting faculty fellows: apply.interfolio.com/174686
Happy to chat with anyone considering either of these options
Reposted by Greg Durrett

Unfortunately I won't be at #COLM2025 this week, but please check out our work being presented by my collaborators/advisors!
If you are interested in evals of open-ended tasks/creativity please reach out and we can schedule a chat! :)
If you are interested in evals of open-ended tasks/creativity please reach out and we can schedule a chat! :)
Find my students and collaborators at COLM this week!
Tuesday morning: @juand-r.bsky.social and @ramyanamuduri.bsky.social 's papers (find them if you missed it!)
Wednesday pm: @manyawadhwa.bsky.social 's EvalAgent
Thursday am: @anirudhkhatry.bsky.social 's CRUST-Bench oral spotlight + poster
Tuesday morning: @juand-r.bsky.social and @ramyanamuduri.bsky.social 's papers (find them if you missed it!)
Wednesday pm: @manyawadhwa.bsky.social 's EvalAgent
Thursday am: @anirudhkhatry.bsky.social 's CRUST-Bench oral spotlight + poster

October 8, 2025 at 12:19 AM
Unfortunately I won't be at #COLM2025 this week, but please check out our work being presented by my collaborators/advisors!
If you are interested in evals of open-ended tasks/creativity please reach out and we can schedule a chat! :)
If you are interested in evals of open-ended tasks/creativity please reach out and we can schedule a chat! :)
Find my students and collaborators at COLM this week!
Tuesday morning: @juand-r.bsky.social and @ramyanamuduri.bsky.social 's papers (find them if you missed it!)
Wednesday pm: @manyawadhwa.bsky.social 's EvalAgent
Thursday am: @anirudhkhatry.bsky.social 's CRUST-Bench oral spotlight + poster
Tuesday morning: @juand-r.bsky.social and @ramyanamuduri.bsky.social 's papers (find them if you missed it!)
Wednesday pm: @manyawadhwa.bsky.social 's EvalAgent
Thursday am: @anirudhkhatry.bsky.social 's CRUST-Bench oral spotlight + poster
October 7, 2025 at 6:03 PM
Find my students and collaborators at COLM this week!
Tuesday morning: @juand-r.bsky.social and @ramyanamuduri.bsky.social 's papers (find them if you missed it!)
Wednesday pm: @manyawadhwa.bsky.social 's EvalAgent
Thursday am: @anirudhkhatry.bsky.social 's CRUST-Bench oral spotlight + poster
Tuesday morning: @juand-r.bsky.social and @ramyanamuduri.bsky.social 's papers (find them if you missed it!)
Wednesday pm: @manyawadhwa.bsky.social 's EvalAgent
Thursday am: @anirudhkhatry.bsky.social 's CRUST-Bench oral spotlight + poster
Reposted by Greg Durrett

Excited to present this at #COLM2025 tomorrow! (Tuesday, 11:00 AM poster session)
One of the ways that LLMs can be inconsistent is the "generator-validator gap," where LLMs deem their own answers incorrect.
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇


October 6, 2025 at 8:40 PM
Excited to present this at #COLM2025 tomorrow! (Tuesday, 11:00 AM poster session)
Check out this feature about AstroVisBench, our upcoming NeurIPS D&B paper about code workflows and visualization in the astronomy domain! Great testbed for the interaction of code + VLM reasoning models.

Exciting news! Introducing AstroVisBench: A Code Benchmark for Scientific Computing and Visualization in Astronomy!
A new benchmark developed by researchers at the NSF-Simons AI Institute for Cosmic Origins is testing how well LLMs implement scientific workflows in astronomy and visualize results.
A new benchmark developed by researchers at the NSF-Simons AI Institute for Cosmic Origins is testing how well LLMs implement scientific workflows in astronomy and visualize results.
September 25, 2025 at 8:43 PM
Check out this feature about AstroVisBench, our upcoming NeurIPS D&B paper about code workflows and visualization in the astronomy domain! Great testbed for the interaction of code + VLM reasoning models.
Reposted by Greg Durrett

News🗞️
I will return to UT Austin as an Assistant Professor of Linguistics this fall, and join its vibrant community of Computational Linguists, NLPers, and Cognitive Scientists!🤘
Excited to develop ideas about linguistic and conceptual generalization (recruitment details soon!)
I will return to UT Austin as an Assistant Professor of Linguistics this fall, and join its vibrant community of Computational Linguists, NLPers, and Cognitive Scientists!🤘
Excited to develop ideas about linguistic and conceptual generalization (recruitment details soon!)

June 2, 2025 at 1:18 PM
News🗞️
I will return to UT Austin as an Assistant Professor of Linguistics this fall, and join its vibrant community of Computational Linguists, NLPers, and Cognitive Scientists!🤘
Excited to develop ideas about linguistic and conceptual generalization (recruitment details soon!)
I will return to UT Austin as an Assistant Professor of Linguistics this fall, and join its vibrant community of Computational Linguists, NLPers, and Cognitive Scientists!🤘
Excited to develop ideas about linguistic and conceptual generalization (recruitment details soon!)
Great to work on this benchmark with astronomers in our NSF-Simons CosmicAI institute! What I like about it:
(1) focus on data processing & visualization, a "bite-sized" AI4Sci task (not automating all of research)
(2) eval with VLM-as-a-judge (possible with strong, modern VLMs)
(1) focus on data processing & visualization, a "bite-sized" AI4Sci task (not automating all of research)
(2) eval with VLM-as-a-judge (possible with strong, modern VLMs)

How good are LLMs at 🔭 scientific computing and visualization 🔭?
AstroVisBench tests how well LLMs implement scientific workflows in astronomy and visualize results.
SOTA models like Gemini 2.5 Pro & Claude 4 Opus only match ground truth scientific utility 16% of the time. 🧵
AstroVisBench tests how well LLMs implement scientific workflows in astronomy and visualize results.
SOTA models like Gemini 2.5 Pro & Claude 4 Opus only match ground truth scientific utility 16% of the time. 🧵


June 2, 2025 at 3:49 PM
Great to work on this benchmark with astronomers in our NSF-Simons CosmicAI institute! What I like about it:
(1) focus on data processing & visualization, a "bite-sized" AI4Sci task (not automating all of research)
(2) eval with VLM-as-a-judge (possible with strong, modern VLMs)
(1) focus on data processing & visualization, a "bite-sized" AI4Sci task (not automating all of research)
(2) eval with VLM-as-a-judge (possible with strong, modern VLMs)
Reposted by Greg Durrett

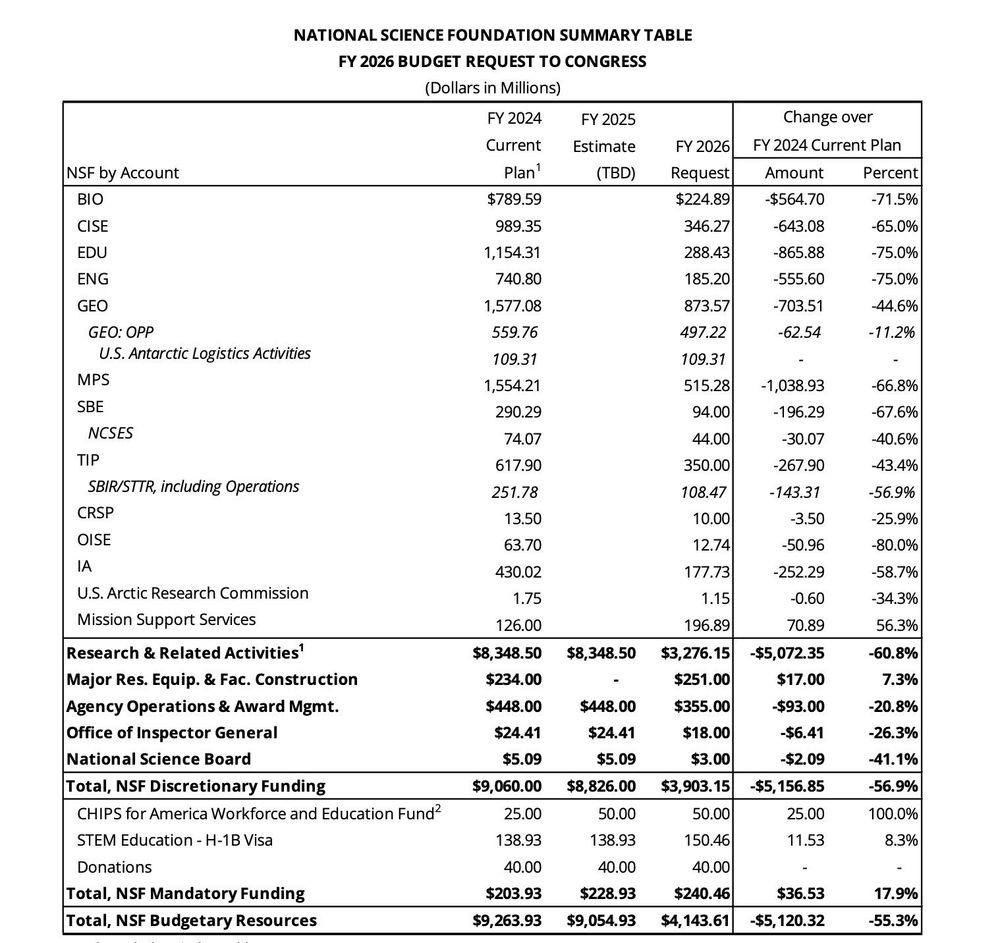
The end of US leadership in science, technology, and innovation.
All in one little table.
A tremendous gift to China, courtesy of the GOP.
nsf-gov-resources.nsf.gov/files/00-NSF...
All in one little table.
A tremendous gift to China, courtesy of the GOP.
nsf-gov-resources.nsf.gov/files/00-NSF...
May 30, 2025 at 9:26 PM
The end of US leadership in science, technology, and innovation.
All in one little table.
A tremendous gift to China, courtesy of the GOP.
nsf-gov-resources.nsf.gov/files/00-NSF...
All in one little table.
A tremendous gift to China, courtesy of the GOP.
nsf-gov-resources.nsf.gov/files/00-NSF...
Reposted by Greg Durrett

Super excited Marin is finally out! Come see what we've been building! Code/platform for training fully reproducible models end-to-end, from data to evals. Plus a new high quality 8B base model. Percy did a good job explaining it on the other place. marin.community
x.com/percyliang/s...
x.com/percyliang/s...

Percy Liang on X: "What would truly open-source AI look like? Not just open weights, open code/data, but *open development*, where the entire research and development process is public *and* anyone can contribute. We built Marin, an open lab, to fulfill this vision: https://t.co/racsvmhyA3" / X
What would truly open-source AI look like? Not just open weights, open code/data, but *open development*, where the entire research and development process is public *and* anyone can contribute. We built Marin, an open lab, to fulfill this vision: https://t.co/racsvmhyA3
x.com
May 19, 2025 at 7:35 PM
Super excited Marin is finally out! Come see what we've been building! Code/platform for training fully reproducible models end-to-end, from data to evals. Plus a new high quality 8B base model. Percy did a good job explaining it on the other place. marin.community
x.com/percyliang/s...
x.com/percyliang/s...
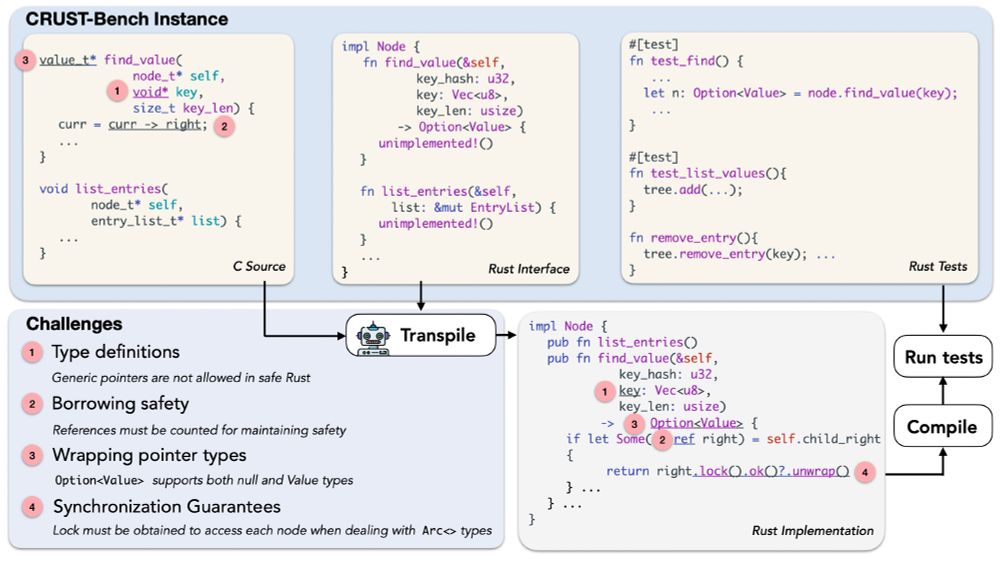
Check out Anirudh's work on a new benchmark for C-to-Rust transpilation! 100 realistic-scale C projects, plus target Rust interfaces + Rust tests that let us validate the transpiled code beyond what prior benchmarks allow.
🚀Meet CRUST-Bench, a dataset for C-to-Rust transpilation for full codebases 🛠️
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6]
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6]

April 23, 2025 at 6:37 PM
Check out Anirudh's work on a new benchmark for C-to-Rust transpilation! 100 realistic-scale C projects, plus target Rust interfaces + Rust tests that let us validate the transpiled code beyond what prior benchmarks allow.
Reposted by Greg Durrett

🚀Meet CRUST-Bench, a dataset for C-to-Rust transpilation for full codebases 🛠️
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6]
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6]
April 23, 2025 at 5:00 PM
🚀Meet CRUST-Bench, a dataset for C-to-Rust transpilation for full codebases 🛠️
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6]
A dataset of 100 real-world C repositories across various domains, each paired with:
🦀 Handwritten safe Rust interfaces.
🧪 Rust test cases to validate correctness.
🧵[1/6]
Check out Manya's work on evaluation for open-ended tasks! The criteria from EvalAgent can be plugged into LLM-as-a-judge or used for refinement. Great tool with a ton of potential, and there's LOTS to do here for making LLMs better at writing!
Evaluating language model responses on open-ended tasks is hard! 🤔
We introduce EvalAgent, a framework that identifies nuanced and diverse criteria 📋✍️.
EvalAgent identifies 👩🏫🎓 expert advice on the web that implicitly address the user’s prompt 🧵👇
We introduce EvalAgent, a framework that identifies nuanced and diverse criteria 📋✍️.
EvalAgent identifies 👩🏫🎓 expert advice on the web that implicitly address the user’s prompt 🧵👇

April 22, 2025 at 4:30 PM
Check out Manya's work on evaluation for open-ended tasks! The criteria from EvalAgent can be plugged into LLM-as-a-judge or used for refinement. Great tool with a ton of potential, and there's LOTS to do here for making LLMs better at writing!
Check out Ramya et al.'s work on understanding discourse similarities in LLM-generated text! We see this as an important step in quantifying the "sameyness" of LLM text, which we think will be a step towards fixing it!

Have that eerie feeling of déjà vu when reading model-generated text 👀, but can’t pinpoint the specific words or phrases 👀?
✨We introduce QUDsim, to quantify discourse similarities beyond lexical, syntactic, and content overlap.
✨We introduce QUDsim, to quantify discourse similarities beyond lexical, syntactic, and content overlap.


April 21, 2025 at 10:10 PM
Check out Ramya et al.'s work on understanding discourse similarities in LLM-generated text! We see this as an important step in quantifying the "sameyness" of LLM text, which we think will be a step towards fixing it!
Reposted by Greg Durrett
Our final South by Semantics lecture at UT Austin is happening on Wednesday April 23!

April 21, 2025 at 1:39 PM
Our final South by Semantics lecture at UT Austin is happening on Wednesday April 23!
Check out @juand-r.bsky.social and @wenxuand.bsky.social 's work on improving generator-validator gaps in LLMs! I really like the formulation of the G-V gap we present, and I was pleasantly surprised by how well the ranking-based training closed the gap. Looking forward to following up in this area!
One of the ways that LLMs can be inconsistent is the "generator-validator gap," where LLMs deem their own answers incorrect.
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇
🎯 We demonstrate that ranking-based discriminator training can significantly reduce this gap, and improvements on one task often generalize to others!
🧵👇
April 16, 2025 at 6:18 PM
Check out @juand-r.bsky.social and @wenxuand.bsky.social 's work on improving generator-validator gaps in LLMs! I really like the formulation of the G-V gap we present, and I was pleasantly surprised by how well the ranking-based training closed the gap. Looking forward to following up in this area!
Reposted by Greg Durrett

If you're scooping up students off the street for writing op-eds, you're secret police, and should be treated accordingly.
March 26, 2025 at 8:00 PM
If you're scooping up students off the street for writing op-eds, you're secret police, and should be treated accordingly.
Reposted by Greg Durrett
I'm excited to announce two papers of ours which will be presented this summer at @naaclmeeting.bsky.social eting.bsky.social and @iclr-conf.bsky.social !
🧵
🧵
March 11, 2025 at 10:03 PM
I'm excited to announce two papers of ours which will be presented this summer at @naaclmeeting.bsky.social eting.bsky.social and @iclr-conf.bsky.social !
🧵
🧵
Reposted by Greg Durrett

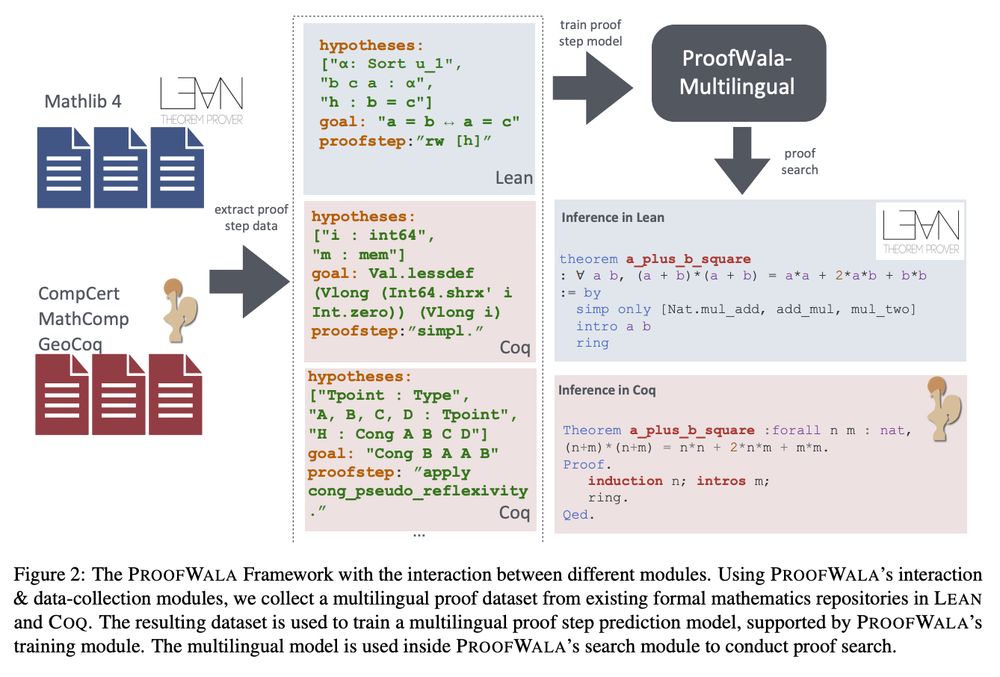
Excited about Proofwala, @amitayush.bsky.social's new framework for ML-aided theorem-proving.
* Paper: arxiv.org/abs/2502.04671
* Code: github.com/trishullab/p...
Proofwala allows the collection of proof-step data from multiple proof assistants (Coq and Lean) and multilingual training. (1/3)
* Paper: arxiv.org/abs/2502.04671
* Code: github.com/trishullab/p...
Proofwala allows the collection of proof-step data from multiple proof assistants (Coq and Lean) and multilingual training. (1/3)
February 22, 2025 at 9:32 PM
Excited about Proofwala, @amitayush.bsky.social's new framework for ML-aided theorem-proving.
* Paper: arxiv.org/abs/2502.04671
* Code: github.com/trishullab/p...
Proofwala allows the collection of proof-step data from multiple proof assistants (Coq and Lean) and multilingual training. (1/3)
* Paper: arxiv.org/abs/2502.04671
* Code: github.com/trishullab/p...
Proofwala allows the collection of proof-step data from multiple proof assistants (Coq and Lean) and multilingual training. (1/3)
Reposted by Greg Durrett

Popular or not Dems cannot bend on the need for trans people to be treated with basic humanity and respect. If we give up that because the right made trans people unpopular, we give up everything. They’ll dice us group by group like a salami. We die on this hill or we die alone in a ditch
February 5, 2025 at 9:19 PM
Popular or not Dems cannot bend on the need for trans people to be treated with basic humanity and respect. If we give up that because the right made trans people unpopular, we give up everything. They’ll dice us group by group like a salami. We die on this hill or we die alone in a ditch
Reposted by Greg Durrett

Here are just a few of the NSF review panels that were shut down today, Chuck.
This is research that would have made us competitive in computer science that will now be delayed by many months if not lost forever.
AI is fine but right now the top priority is keeping the lights on at NSF and NIH.
This is research that would have made us competitive in computer science that will now be delayed by many months if not lost forever.
AI is fine but right now the top priority is keeping the lights on at NSF and NIH.

January 28, 2025 at 3:06 AM
Here are just a few of the NSF review panels that were shut down today, Chuck.
This is research that would have made us competitive in computer science that will now be delayed by many months if not lost forever.
AI is fine but right now the top priority is keeping the lights on at NSF and NIH.
This is research that would have made us competitive in computer science that will now be delayed by many months if not lost forever.
AI is fine but right now the top priority is keeping the lights on at NSF and NIH.
Reposted by Greg Durrett

kicking off 2025 with our OLMo 2 tech report while payin homage to the sequelest of sequels 🫡
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵

January 3, 2025 at 4:02 PM
kicking off 2025 with our OLMo 2 tech report while payin homage to the sequelest of sequels 🫡
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵