



Pingchuan Ma
@pima-hyphen.bsky.social
PhD Student at Ommer Lab, Munich (Stable Diffusion)
🎯 Working on getting my first 3M.
🎯 Working on getting my first 3M.
Thanks, my dear investor!
October 18, 2025 at 8:42 AM
Thanks, my dear investor!
Huge thanks to all my great collaborators, @mgui7.bsky.social, @joh-schb.bsky.social , Xiaopei Yang, Yusong Li, Felix Krause, Olga Grebenkova, @vtaohu.bsky.social, and Björn Ommer at @compvis.bsky.social.
October 18, 2025 at 3:01 AM
Huge thanks to all my great collaborators, @mgui7.bsky.social, @joh-schb.bsky.social , Xiaopei Yang, Yusong Li, Felix Krause, Olga Grebenkova, @vtaohu.bsky.social, and Björn Ommer at @compvis.bsky.social.
I am excited to connect or catch up in person at #ICCV2025. I am also seeking full-time or internship opportunities 🧑🏻💻 starting June 2026.
October 18, 2025 at 3:01 AM
I am excited to connect or catch up in person at #ICCV2025. I am also seeking full-time or internship opportunities 🧑🏻💻 starting June 2026.
2️⃣ ArtFM: Stochastic Interpolants for Revealing Stylistic Flows across the History of Art 🎨
TL;DR: Modeling how artistic style evolves over 500 years without relying on ground-truth pairs.
📍 Poster Session 2
🗓️ Tue, Oct 21 — 3:00 PM
🧾 Poster #80
🔗 compvis.github.io/Art-fm/
TL;DR: Modeling how artistic style evolves over 500 years without relying on ground-truth pairs.
📍 Poster Session 2
🗓️ Tue, Oct 21 — 3:00 PM
🧾 Poster #80
🔗 compvis.github.io/Art-fm/

October 18, 2025 at 3:01 AM
2️⃣ ArtFM: Stochastic Interpolants for Revealing Stylistic Flows across the History of Art 🎨
TL;DR: Modeling how artistic style evolves over 500 years without relying on ground-truth pairs.
📍 Poster Session 2
🗓️ Tue, Oct 21 — 3:00 PM
🧾 Poster #80
🔗 compvis.github.io/Art-fm/
TL;DR: Modeling how artistic style evolves over 500 years without relying on ground-truth pairs.
📍 Poster Session 2
🗓️ Tue, Oct 21 — 3:00 PM
🧾 Poster #80
🔗 compvis.github.io/Art-fm/
1️⃣ SCFlow: Implicitly Learning Style and Content Disentanglement with Flow Models 🔄
TL;DR: We learn disentangled representations implicitly by training only on merging them.
📍 Poster Session 4
🗓️ Wed, Oct 22 — 2:30 PM
🧾 Poster #3
🔗 compvis.github.io/SCFlow/
TL;DR: We learn disentangled representations implicitly by training only on merging them.
📍 Poster Session 4
🗓️ Wed, Oct 22 — 2:30 PM
🧾 Poster #3
🔗 compvis.github.io/SCFlow/

October 18, 2025 at 3:01 AM
1️⃣ SCFlow: Implicitly Learning Style and Content Disentanglement with Flow Models 🔄
TL;DR: We learn disentangled representations implicitly by training only on merging them.
📍 Poster Session 4
🗓️ Wed, Oct 22 — 2:30 PM
🧾 Poster #3
🔗 compvis.github.io/SCFlow/
TL;DR: We learn disentangled representations implicitly by training only on merging them.
📍 Poster Session 4
🗓️ Wed, Oct 22 — 2:30 PM
🧾 Poster #3
🔗 compvis.github.io/SCFlow/
Jokes aside, I understand the submission load is massive, but shifting the burden of filtering invalid or duplicate entries onto reviewers isn’t a good incentive. It is 2025, and simple automated checks should be easy to employ, help the process, and respect reviewers’ time.
August 4, 2025 at 2:51 PM
Jokes aside, I understand the submission load is massive, but shifting the burden of filtering invalid or duplicate entries onto reviewers isn’t a good incentive. It is 2025, and simple automated checks should be easy to employ, help the process, and respect reviewers’ time.
this sounded way to intimate
August 4, 2025 at 2:45 PM
this sounded way to intimate
(reference source in the Alt text of the figures due to character limit)
January 8, 2025 at 4:07 PM
(reference source in the Alt text of the figures due to character limit)
🚀 We introduced a training-free approach to select small yet meaningful neighborhoods of discriminative descriptions that improve classification accuracy. We validated our findings across seven datasets, showing consistent gains without distorting the underlying VLM embedding space.


January 8, 2025 at 3:54 PM
🚀 We introduced a training-free approach to select small yet meaningful neighborhoods of discriminative descriptions that improve classification accuracy. We validated our findings across seven datasets, showing consistent gains without distorting the underlying VLM embedding space.
🤔 To check out what happened, we proposed a new evaluation scenario to isolate the semantic impact by eliminating noise augmentation, ensuring only meaningful descriptions are useful. Random strings and unrelated texts degrade performance, while our assigned descriptions show clear advantages.

January 8, 2025 at 3:54 PM
🤔 To check out what happened, we proposed a new evaluation scenario to isolate the semantic impact by eliminating noise augmentation, ensuring only meaningful descriptions are useful. Random strings and unrelated texts degrade performance, while our assigned descriptions show clear advantages.
🤯 However, another recent study showed that descriptions augmented by unrelated text or noise could achieve similar performances. This raises the question: Does genuine semantics drive this gain, or is it an ensembling effect (similar to Multi-Crop test-time augmentation in the vision case)?

January 8, 2025 at 3:54 PM
🤯 However, another recent study showed that descriptions augmented by unrelated text or noise could achieve similar performances. This raises the question: Does genuine semantics drive this gain, or is it an ensembling effect (similar to Multi-Crop test-time augmentation in the vision case)?
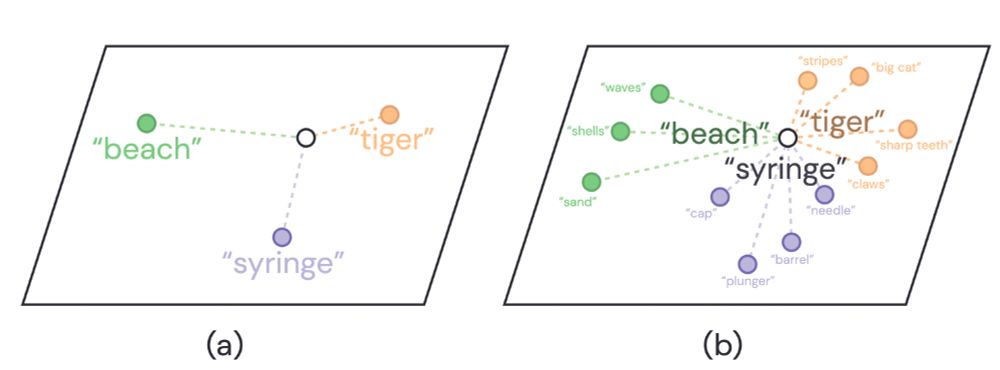
Studies have shown that VLMs performance can be boosted by prompting LLMs for more detailed descriptions. Then use these descriptions to augment the original classname during inference, such as “tiger, a big cat; with sharp teeth” instead of simply “tiger”.
January 8, 2025 at 3:54 PM
Studies have shown that VLMs performance can be boosted by prompting LLMs for more detailed descriptions. Then use these descriptions to augment the original classname during inference, such as “tiger, a big cat; with sharp teeth” instead of simply “tiger”.
This work was co-led by x.com/LennartRietdorf, and collaborated with Dmytro Kotovenko, @vtaohu.bsky.social, and Björn Ommer.
January 8, 2025 at 3:54 PM
This work was co-led by x.com/LennartRietdorf, and collaborated with Dmytro Kotovenko, @vtaohu.bsky.social, and Björn Ommer.