



Pingchuan Ma
@pima-hyphen.bsky.social
PhD Student at Ommer Lab, Munich (Stable Diffusion)
🎯 Working on getting my first 3M.
🎯 Working on getting my first 3M.
2️⃣ ArtFM: Stochastic Interpolants for Revealing Stylistic Flows across the History of Art 🎨
TL;DR: Modeling how artistic style evolves over 500 years without relying on ground-truth pairs.
📍 Poster Session 2
🗓️ Tue, Oct 21 — 3:00 PM
🧾 Poster #80
🔗 compvis.github.io/Art-fm/
TL;DR: Modeling how artistic style evolves over 500 years without relying on ground-truth pairs.
📍 Poster Session 2
🗓️ Tue, Oct 21 — 3:00 PM
🧾 Poster #80
🔗 compvis.github.io/Art-fm/

October 18, 2025 at 3:01 AM
2️⃣ ArtFM: Stochastic Interpolants for Revealing Stylistic Flows across the History of Art 🎨
TL;DR: Modeling how artistic style evolves over 500 years without relying on ground-truth pairs.
📍 Poster Session 2
🗓️ Tue, Oct 21 — 3:00 PM
🧾 Poster #80
🔗 compvis.github.io/Art-fm/
TL;DR: Modeling how artistic style evolves over 500 years without relying on ground-truth pairs.
📍 Poster Session 2
🗓️ Tue, Oct 21 — 3:00 PM
🧾 Poster #80
🔗 compvis.github.io/Art-fm/
1️⃣ SCFlow: Implicitly Learning Style and Content Disentanglement with Flow Models 🔄
TL;DR: We learn disentangled representations implicitly by training only on merging them.
📍 Poster Session 4
🗓️ Wed, Oct 22 — 2:30 PM
🧾 Poster #3
🔗 compvis.github.io/SCFlow/
TL;DR: We learn disentangled representations implicitly by training only on merging them.
📍 Poster Session 4
🗓️ Wed, Oct 22 — 2:30 PM
🧾 Poster #3
🔗 compvis.github.io/SCFlow/

October 18, 2025 at 3:01 AM
1️⃣ SCFlow: Implicitly Learning Style and Content Disentanglement with Flow Models 🔄
TL;DR: We learn disentangled representations implicitly by training only on merging them.
📍 Poster Session 4
🗓️ Wed, Oct 22 — 2:30 PM
🧾 Poster #3
🔗 compvis.github.io/SCFlow/
TL;DR: We learn disentangled representations implicitly by training only on merging them.
📍 Poster Session 4
🗓️ Wed, Oct 22 — 2:30 PM
🧾 Poster #3
🔗 compvis.github.io/SCFlow/
Our work received an invited talk at the Imageomics-AAAI-25 workshop of #AAAI25. @vtaohu.bsky.social will be representing us there. Without me being there, I still would like to share our poster with you :D
We also have another oral presentation for DepthFM on March 1, 2:30 pm-3:45 pm.
We also have another oral presentation for DepthFM on March 1, 2:30 pm-3:45 pm.

February 28, 2025 at 5:03 PM
Our work received an invited talk at the Imageomics-AAAI-25 workshop of #AAAI25. @vtaohu.bsky.social will be representing us there. Without me being there, I still would like to share our poster with you :D
We also have another oral presentation for DepthFM on March 1, 2:30 pm-3:45 pm.
We also have another oral presentation for DepthFM on March 1, 2:30 pm-3:45 pm.
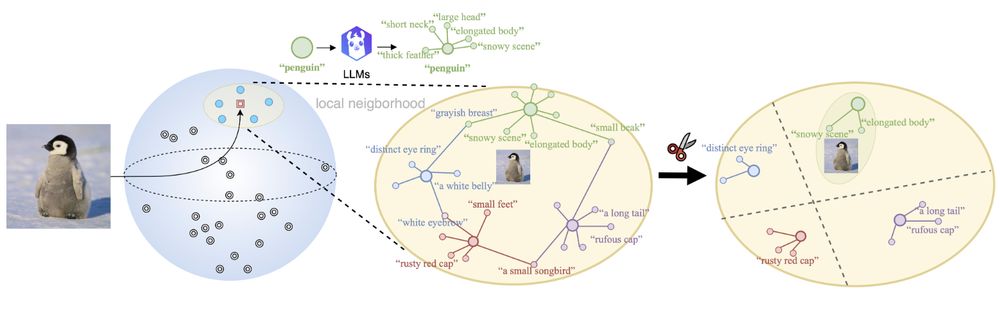
🚀 We introduced a training-free approach to select small yet meaningful neighborhoods of discriminative descriptions that improve classification accuracy. We validated our findings across seven datasets, showing consistent gains without distorting the underlying VLM embedding space.


January 8, 2025 at 3:54 PM
🚀 We introduced a training-free approach to select small yet meaningful neighborhoods of discriminative descriptions that improve classification accuracy. We validated our findings across seven datasets, showing consistent gains without distorting the underlying VLM embedding space.
🤔 To check out what happened, we proposed a new evaluation scenario to isolate the semantic impact by eliminating noise augmentation, ensuring only meaningful descriptions are useful. Random strings and unrelated texts degrade performance, while our assigned descriptions show clear advantages.

January 8, 2025 at 3:54 PM
🤔 To check out what happened, we proposed a new evaluation scenario to isolate the semantic impact by eliminating noise augmentation, ensuring only meaningful descriptions are useful. Random strings and unrelated texts degrade performance, while our assigned descriptions show clear advantages.
🤯 However, another recent study showed that descriptions augmented by unrelated text or noise could achieve similar performances. This raises the question: Does genuine semantics drive this gain, or is it an ensembling effect (similar to Multi-Crop test-time augmentation in the vision case)?

January 8, 2025 at 3:54 PM
🤯 However, another recent study showed that descriptions augmented by unrelated text or noise could achieve similar performances. This raises the question: Does genuine semantics drive this gain, or is it an ensembling effect (similar to Multi-Crop test-time augmentation in the vision case)?
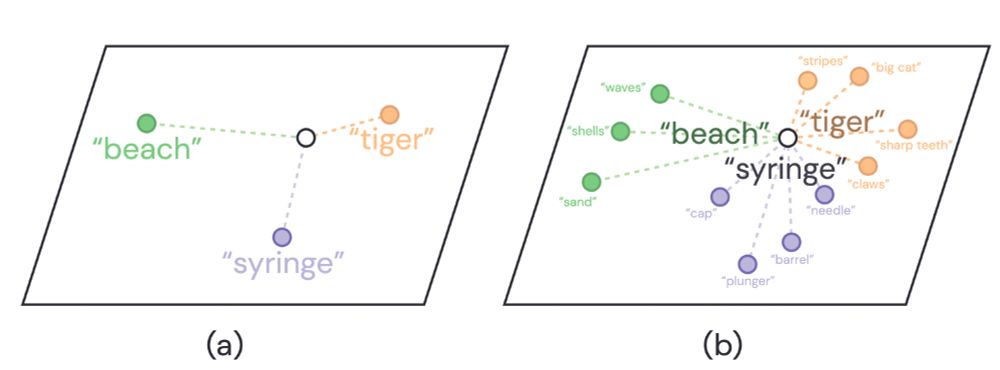
Studies have shown that VLMs performance can be boosted by prompting LLMs for more detailed descriptions. Then use these descriptions to augment the original classname during inference, such as “tiger, a big cat; with sharp teeth” instead of simply “tiger”.
January 8, 2025 at 3:54 PM
Studies have shown that VLMs performance can be boosted by prompting LLMs for more detailed descriptions. Then use these descriptions to augment the original classname during inference, such as “tiger, a big cat; with sharp teeth” instead of simply “tiger”.
🤔When combining Vision-language models (VLMs) with Large language models (LLMs), do VLMs benefit from additional genuine semantics or artificial augmentations of the text for downstream tasks?
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
January 8, 2025 at 3:54 PM
🤔When combining Vision-language models (VLMs) with Large language models (LLMs), do VLMs benefit from additional genuine semantics or artificial augmentations of the text for downstream tasks?
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇