



Pingchuan Ma
@pima-hyphen.bsky.social
PhD Student at Ommer Lab, Munich (Stable Diffusion)
🎯 Working on getting my first 3M.
🎯 Working on getting my first 3M.
I’m thrilled to share that I’ll present two first-authored papers at #ICCV2025 🌺 in Honolulu together with @mgui7.bsky.social ! 🏝️
(Thread 🧵👇)
(Thread 🧵👇)
October 18, 2025 at 3:01 AM
I’m thrilled to share that I’ll present two first-authored papers at #ICCV2025 🌺 in Honolulu together with @mgui7.bsky.social ! 🏝️
(Thread 🧵👇)
(Thread 🧵👇)
Reposted by Pingchuan Ma

🤔 What happens when you poke a scene — and your model has to predict how the world moves in response?
We built the Flow Poke Transformer (FPT) to model multi-modal scene dynamics from sparse interactions.
It learns to predict the 𝘥𝘪𝘴𝘵𝘳𝘪𝘣𝘶𝘵𝘪𝘰𝘯 of motion itself 🧵👇
We built the Flow Poke Transformer (FPT) to model multi-modal scene dynamics from sparse interactions.
It learns to predict the 𝘥𝘪𝘴𝘵𝘳𝘪𝘣𝘶𝘵𝘪𝘰𝘯 of motion itself 🧵👇

October 15, 2025 at 1:56 AM
🤔 What happens when you poke a scene — and your model has to predict how the world moves in response?
We built the Flow Poke Transformer (FPT) to model multi-modal scene dynamics from sparse interactions.
It learns to predict the 𝘥𝘪𝘴𝘵𝘳𝘪𝘣𝘶𝘵𝘪𝘰𝘯 of motion itself 🧵👇
We built the Flow Poke Transformer (FPT) to model multi-modal scene dynamics from sparse interactions.
It learns to predict the 𝘥𝘪𝘴𝘵𝘳𝘪𝘣𝘶𝘵𝘪𝘰𝘯 of motion itself 🧵👇
I just wrapped up my bidding process for AAAI 26, which is always an enjoyable experience. This year, I came across submissions titled things like “000ASD”, “testy”, “123321241”, and even cases with identical titles and abstracts but different submission numbers.
August 4, 2025 at 2:51 PM
I just wrapped up my bidding process for AAAI 26, which is always an enjoyable experience. This year, I came across submissions titled things like “000ASD”, “testy”, “123321241”, and even cases with identical titles and abstracts but different submission numbers.
Our work received an invited talk at the Imageomics-AAAI-25 workshop of #AAAI25. @vtaohu.bsky.social will be representing us there. Without me being there, I still would like to share our poster with you :D
We also have another oral presentation for DepthFM on March 1, 2:30 pm-3:45 pm.
We also have another oral presentation for DepthFM on March 1, 2:30 pm-3:45 pm.

February 28, 2025 at 5:03 PM
Our work received an invited talk at the Imageomics-AAAI-25 workshop of #AAAI25. @vtaohu.bsky.social will be representing us there. Without me being there, I still would like to share our poster with you :D
We also have another oral presentation for DepthFM on March 1, 2:30 pm-3:45 pm.
We also have another oral presentation for DepthFM on March 1, 2:30 pm-3:45 pm.
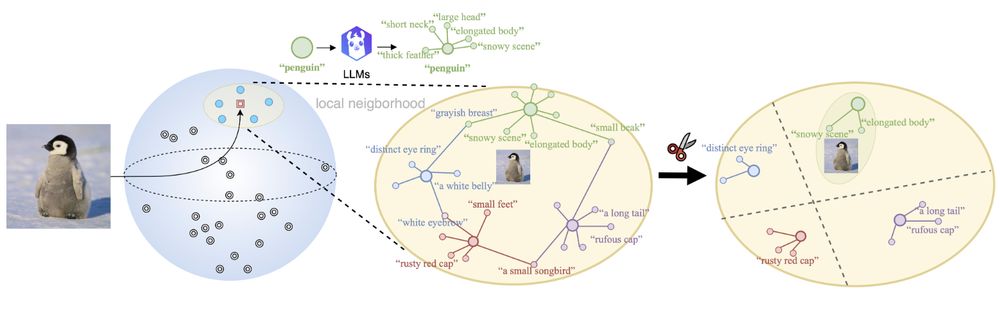
🤔When combining Vision-language models (VLMs) with Large language models (LLMs), do VLMs benefit from additional genuine semantics or artificial augmentations of the text for downstream tasks?
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
January 8, 2025 at 3:54 PM
🤔When combining Vision-language models (VLMs) with Large language models (LLMs), do VLMs benefit from additional genuine semantics or artificial augmentations of the text for downstream tasks?
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
Reposted by Pingchuan Ma

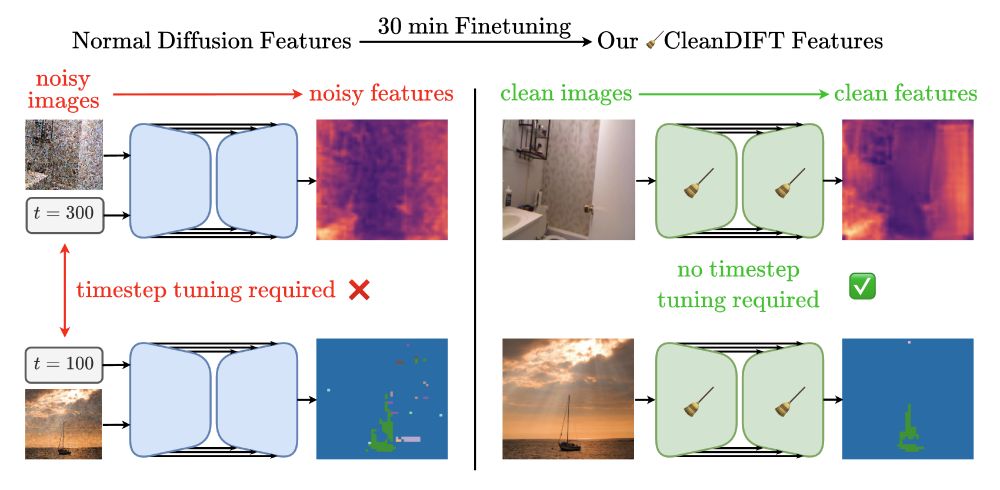
🤔 Why do we extract diffusion features from noisy images? Isn’t that destroying information?
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
December 4, 2024 at 11:31 PM
🤔 Why do we extract diffusion features from noisy images? Isn’t that destroying information?
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇