



Paul Röttger @ EMNLP
@paul-rottger.bsky.social
Postdoc @milanlp.bsky.social working on LLM safety and societal impacts. Previously PhD @oii.ox.ac.uk and CTO / co-founder of Rewire (acquired '23)
https://paulrottger.com/
https://paulrottger.com/
Pinned
Are LLMs biased when they write about political issues?
We just released IssueBench – the largest, most realistic benchmark of its kind – to answer this question more robustly than ever before.
Long 🧵with spicy results 👇
We just released IssueBench – the largest, most realistic benchmark of its kind – to answer this question more robustly than ever before.
Long 🧵with spicy results 👇

There’s plenty of evidence for political bias in LLMs, but very few evals reflect realistic LLM use cases — which is where bias actually matters.
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
There’s plenty of evidence for political bias in LLMs, but very few evals reflect realistic LLM use cases — which is where bias actually matters.
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
Are LLMs biased when they write about political issues?
We just released IssueBench – the largest, most realistic benchmark of its kind – to answer this question more robustly than ever before.
Long 🧵with spicy results 👇
We just released IssueBench – the largest, most realistic benchmark of its kind – to answer this question more robustly than ever before.
Long 🧵with spicy results 👇
October 29, 2025 at 4:12 PM
There’s plenty of evidence for political bias in LLMs, but very few evals reflect realistic LLM use cases — which is where bias actually matters.
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
LLMs are good at simulating human behaviours, but they are not going to be great unless we train them to.
We hope SimBench can be the foundation for more specialised development of LLM simulators.
I really enjoyed working on this with @tiancheng.bsky.social et al. Many fun results 👇
We hope SimBench can be the foundation for more specialised development of LLM simulators.
I really enjoyed working on this with @tiancheng.bsky.social et al. Many fun results 👇

Can AI simulate human behavior? 🧠
The promise is revolutionary for science & policy. But there’s a huge "IF": Do these simulations actually reflect reality?
To find out, we introduce SimBench: The first large-scale benchmark for group-level social simulation. (1/9)
The promise is revolutionary for science & policy. But there’s a huge "IF": Do these simulations actually reflect reality?
To find out, we introduce SimBench: The first large-scale benchmark for group-level social simulation. (1/9)
October 28, 2025 at 5:58 PM
LLMs are good at simulating human behaviours, but they are not going to be great unless we train them to.
We hope SimBench can be the foundation for more specialised development of LLM simulators.
I really enjoyed working on this with @tiancheng.bsky.social et al. Many fun results 👇
We hope SimBench can be the foundation for more specialised development of LLM simulators.
I really enjoyed working on this with @tiancheng.bsky.social et al. Many fun results 👇
Reposted by Paul Röttger @ EMNLP

🏆 Thrilled to share that our HateDay paper has received an Outstanding Paper Award at #ACL2025
Big thanks to my wonderful co-authors: @deeliu97.bsky.social, Niyati, @computermacgyver.bsky.social, Sam, Victor, and @paul-rottger.bsky.social!
Thread 👇and data avail at huggingface.co/datasets/man...
Big thanks to my wonderful co-authors: @deeliu97.bsky.social, Niyati, @computermacgyver.bsky.social, Sam, Victor, and @paul-rottger.bsky.social!
Thread 👇and data avail at huggingface.co/datasets/man...

July 31, 2025 at 8:05 AM
🏆 Thrilled to share that our HateDay paper has received an Outstanding Paper Award at #ACL2025
Big thanks to my wonderful co-authors: @deeliu97.bsky.social, Niyati, @computermacgyver.bsky.social, Sam, Victor, and @paul-rottger.bsky.social!
Thread 👇and data avail at huggingface.co/datasets/man...
Big thanks to my wonderful co-authors: @deeliu97.bsky.social, Niyati, @computermacgyver.bsky.social, Sam, Victor, and @paul-rottger.bsky.social!
Thread 👇and data avail at huggingface.co/datasets/man...
Very excited about all these papers on sociotechnical alignment & the societal impacts of AI at #ACL2025.
As is now tradition, I made some timetables to help me find my way around. Sharing here in case others find them useful too :) 🧵
As is now tradition, I made some timetables to help me find my way around. Sharing here in case others find them useful too :) 🧵
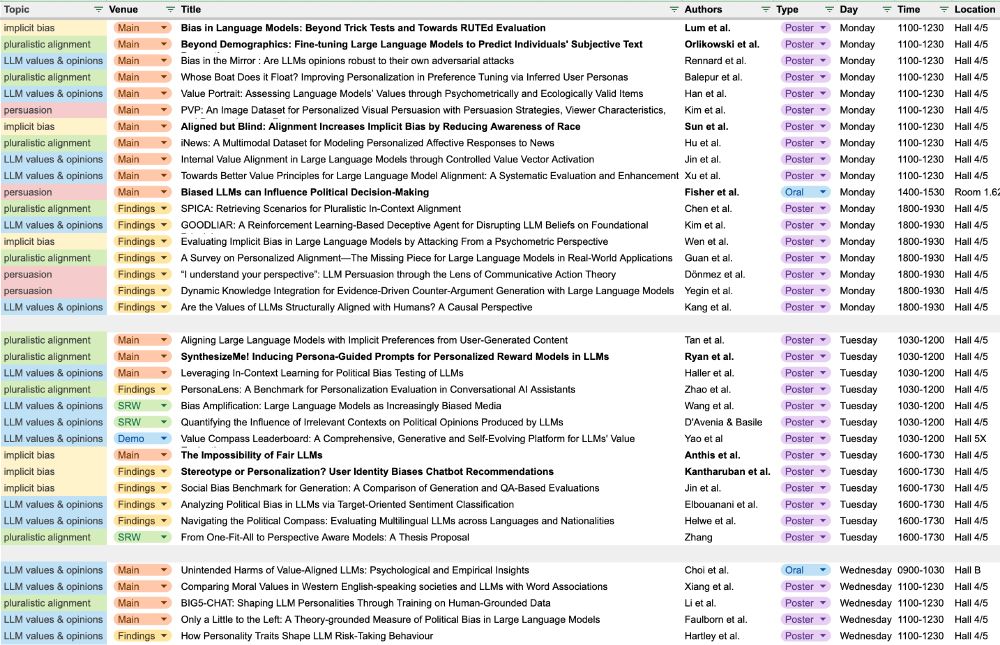
July 28, 2025 at 6:13 AM
Very excited about all these papers on sociotechnical alignment & the societal impacts of AI at #ACL2025.
As is now tradition, I made some timetables to help me find my way around. Sharing here in case others find them useful too :) 🧵
As is now tradition, I made some timetables to help me find my way around. Sharing here in case others find them useful too :) 🧵
Reposted by Paul Röttger @ EMNLP

Can LLMs learn to simulate individuals' judgments based on their demographics?
Not quite! In our new paper, we found that LLMs do not learn information about demographics, but instead learn individual annotators' patterns based on unique combinations of attributes!
🧵
Not quite! In our new paper, we found that LLMs do not learn information about demographics, but instead learn individual annotators' patterns based on unique combinations of attributes!
🧵

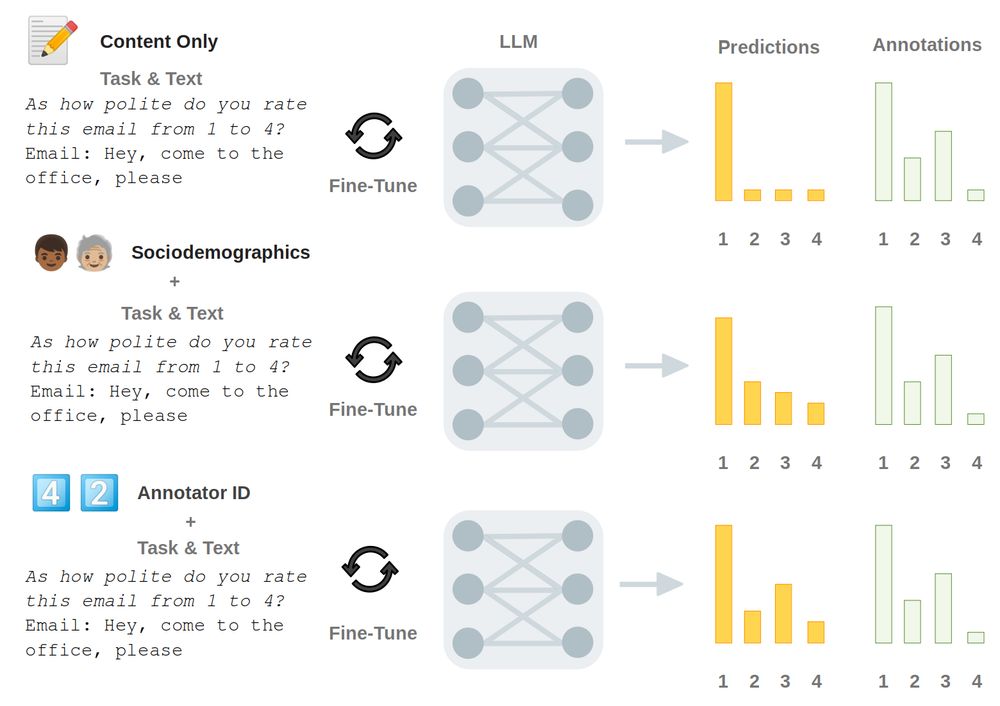

April 14, 2025 at 1:18 PM
Can LLMs learn to simulate individuals' judgments based on their demographics?
Not quite! In our new paper, we found that LLMs do not learn information about demographics, but instead learn individual annotators' patterns based on unique combinations of attributes!
🧵
Not quite! In our new paper, we found that LLMs do not learn information about demographics, but instead learn individual annotators' patterns based on unique combinations of attributes!
🧵
Reposted by Paul Röttger @ EMNLP

📈Out today in @PNASNews!📈
In a large pre-registered experiment (n=25,982), we find evidence that scaling the size of LLMs yields sharply diminishing persuasive returns for static political messages.
🧵:
In a large pre-registered experiment (n=25,982), we find evidence that scaling the size of LLMs yields sharply diminishing persuasive returns for static political messages.
🧵:

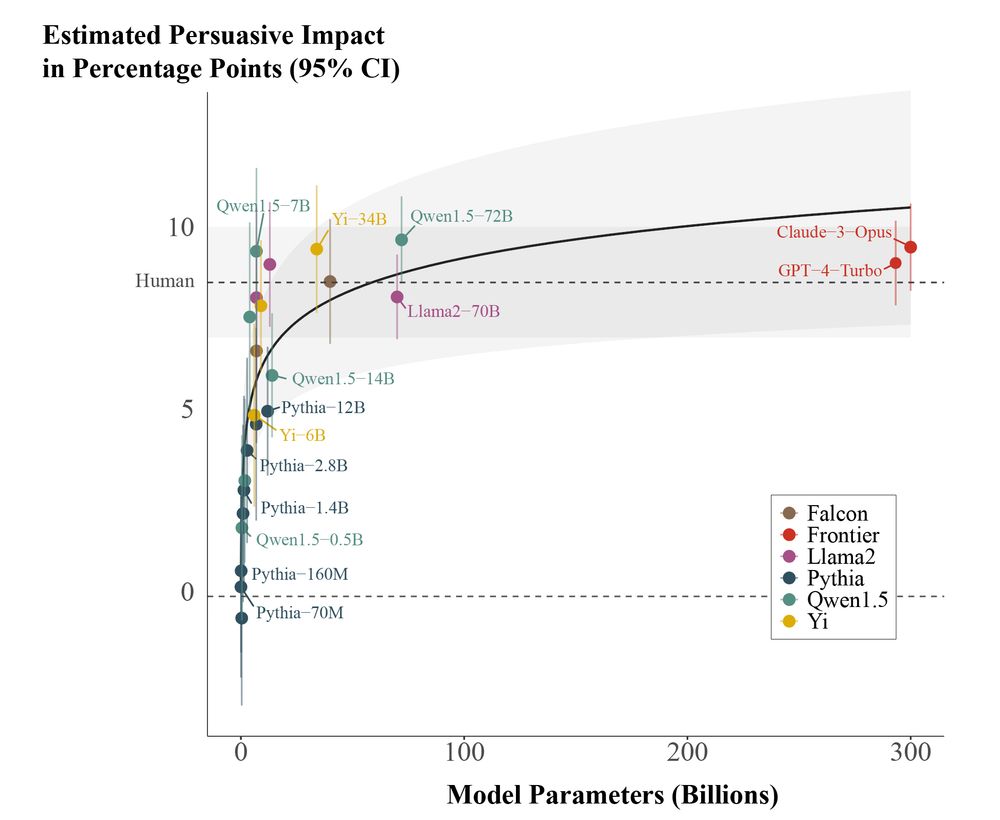
March 7, 2025 at 6:28 PM
📈Out today in @PNASNews!📈
In a large pre-registered experiment (n=25,982), we find evidence that scaling the size of LLMs yields sharply diminishing persuasive returns for static political messages.
🧵:
In a large pre-registered experiment (n=25,982), we find evidence that scaling the size of LLMs yields sharply diminishing persuasive returns for static political messages.
🧵:
Are LLMs biased when they write about political issues?
We just released IssueBench – the largest, most realistic benchmark of its kind – to answer this question more robustly than ever before.
Long 🧵with spicy results 👇
We just released IssueBench – the largest, most realistic benchmark of its kind – to answer this question more robustly than ever before.
Long 🧵with spicy results 👇
February 13, 2025 at 2:08 PM
Are LLMs biased when they write about political issues?
We just released IssueBench – the largest, most realistic benchmark of its kind – to answer this question more robustly than ever before.
Long 🧵with spicy results 👇
We just released IssueBench – the largest, most realistic benchmark of its kind – to answer this question more robustly than ever before.
Long 🧵with spicy results 👇
Reposted by Paul Röttger @ EMNLP

I’m thrilled to share that our paper on mitigating false refusal in language models has been accepted to ICLR 2025 @iclr-conf.bsky.social!
arxiv.org/abs/2410.03415
Joint work with chengzhi, @paul-rottger.bsky.social, @barbaraplank.bsky.social.
arxiv.org/abs/2410.03415
Joint work with chengzhi, @paul-rottger.bsky.social, @barbaraplank.bsky.social.

January 23, 2025 at 9:34 PM
I’m thrilled to share that our paper on mitigating false refusal in language models has been accepted to ICLR 2025 @iclr-conf.bsky.social!
arxiv.org/abs/2410.03415
Joint work with chengzhi, @paul-rottger.bsky.social, @barbaraplank.bsky.social.
arxiv.org/abs/2410.03415
Joint work with chengzhi, @paul-rottger.bsky.social, @barbaraplank.bsky.social.
Today, we are releasing MSTS, a new Multimodal Safety Test Suite for vision-language models!
MSTS is exciting because it tests for safety risks *created by multimodality*. Each prompt consists of a text + image that *only in combination* reveal their full unsafe meaning.
🧵
MSTS is exciting because it tests for safety risks *created by multimodality*. Each prompt consists of a text + image that *only in combination* reveal their full unsafe meaning.
🧵

January 21, 2025 at 11:36 AM
Today, we are releasing MSTS, a new Multimodal Safety Test Suite for vision-language models!
MSTS is exciting because it tests for safety risks *created by multimodality*. Each prompt consists of a text + image that *only in combination* reveal their full unsafe meaning.
🧵
MSTS is exciting because it tests for safety risks *created by multimodality*. Each prompt consists of a text + image that *only in combination* reveal their full unsafe meaning.
🧵