




Paolo Papotti
@papotti.bsky.social
Associate Prof at EURECOM and 3IA Côte d'Azur Chair of Artificial Intelligence. ELLIS member.
Data management and NLP/LLMs for information quality.
https://www.eurecom.fr/~papotti/
Data management and NLP/LLMs for information quality.
https://www.eurecom.fr/~papotti/
Reposted by Paolo Papotti

Vol:18 No:12 → Accelerating Tabular Inference: Training Data Generation with TENET
👥 Authors: Enzo Veltri, Donatello Santoro, Jean-Flavien Bussotti, Paolo Papotti
📄 PDF: https://www.vldb.org/pvldb/vol18/p5303-veltri.pdf
👥 Authors: Enzo Veltri, Donatello Santoro, Jean-Flavien Bussotti, Paolo Papotti
📄 PDF: https://www.vldb.org/pvldb/vol18/p5303-veltri.pdf

September 4, 2025 at 4:00 AM
Vol:18 No:12 → Accelerating Tabular Inference: Training Data Generation with TENET
👥 Authors: Enzo Veltri, Donatello Santoro, Jean-Flavien Bussotti, Paolo Papotti
📄 PDF: https://www.vldb.org/pvldb/vol18/p5303-veltri.pdf
👥 Authors: Enzo Veltri, Donatello Santoro, Jean-Flavien Bussotti, Paolo Papotti
📄 PDF: https://www.vldb.org/pvldb/vol18/p5303-veltri.pdf
Reposted by Paolo Papotti

Can We Trust the Judges? This is the question we asked in validating factuality evaluation methods via answer perturbation. Check out the results at the #EvalLLM2025 workshop at #TALN2025
Blog: giovannigatti.github.io/trutheval/
Watch: www.youtube.com/watch?v=f0XJ...
Play: github.com/GiovanniGatt...
Blog: giovannigatti.github.io/trutheval/
Watch: www.youtube.com/watch?v=f0XJ...
Play: github.com/GiovanniGatt...

June 30, 2025 at 12:55 PM
Can We Trust the Judges? This is the question we asked in validating factuality evaluation methods via answer perturbation. Check out the results at the #EvalLLM2025 workshop at #TALN2025
Blog: giovannigatti.github.io/trutheval/
Watch: www.youtube.com/watch?v=f0XJ...
Play: github.com/GiovanniGatt...
Blog: giovannigatti.github.io/trutheval/
Watch: www.youtube.com/watch?v=f0XJ...
Play: github.com/GiovanniGatt...
Ask any LLM for a single fact and it’s usually fine.
Ask it for a rich list and the same fact is suddenly missing or hallucinated because the output context got longer 😳
LLMs exceed 80% accuracy on single-value questions but accuracy drops linearly with the # of output facts
New paper, details 👇
Ask it for a rich list and the same fact is suddenly missing or hallucinated because the output context got longer 😳
LLMs exceed 80% accuracy on single-value questions but accuracy drops linearly with the # of output facts
New paper, details 👇

RelationalFactQA: A Benchmark for Evaluating Tabular Fact Retrieval from Large Language Models
Factuality in Large Language Models (LLMs) is a persistent challenge. Current benchmarks often assess short factual answers, overlooking the critical ability to generate structured, multi-record tabul...
arxiv.org
June 2, 2025 at 2:51 PM
Ask any LLM for a single fact and it’s usually fine.
Ask it for a rich list and the same fact is suddenly missing or hallucinated because the output context got longer 😳
LLMs exceed 80% accuracy on single-value questions but accuracy drops linearly with the # of output facts
New paper, details 👇
Ask it for a rich list and the same fact is suddenly missing or hallucinated because the output context got longer 😳
LLMs exceed 80% accuracy on single-value questions but accuracy drops linearly with the # of output facts
New paper, details 👇
🚨 𝐖𝐡𝐚𝐭 𝐡𝐚𝐩𝐩𝐞𝐧𝐬 𝐰𝐡𝐞𝐧 𝐭𝐡𝐞 𝐜𝐫𝐨𝐰𝐝 𝐛𝐞𝐜𝐨𝐦𝐞𝐬 𝐭𝐡𝐞 𝐟𝐚𝐜𝐭-𝐜𝐡𝐞𝐜𝐤𝐞𝐫?
new "Community Moderation and the New Epistemology of Fact Checking on Social Media"
with I Augenstein, M Bakker, T. Chakraborty, D. Corney, E
Ferrara, I Gurevych, S Hale, E Hovy, H Ji, I Larraz, F
Menczer, P Nakov, D Sahnan, G Warren, G Zagni
new "Community Moderation and the New Epistemology of Fact Checking on Social Media"
with I Augenstein, M Bakker, T. Chakraborty, D. Corney, E
Ferrara, I Gurevych, S Hale, E Hovy, H Ji, I Larraz, F
Menczer, P Nakov, D Sahnan, G Warren, G Zagni
arxiv.org
June 1, 2025 at 7:48 AM
🚨 𝐖𝐡𝐚𝐭 𝐡𝐚𝐩𝐩𝐞𝐧𝐬 𝐰𝐡𝐞𝐧 𝐭𝐡𝐞 𝐜𝐫𝐨𝐰𝐝 𝐛𝐞𝐜𝐨𝐦𝐞𝐬 𝐭𝐡𝐞 𝐟𝐚𝐜𝐭-𝐜𝐡𝐞𝐜𝐤𝐞𝐫?
new "Community Moderation and the New Epistemology of Fact Checking on Social Media"
with I Augenstein, M Bakker, T. Chakraborty, D. Corney, E
Ferrara, I Gurevych, S Hale, E Hovy, H Ji, I Larraz, F
Menczer, P Nakov, D Sahnan, G Warren, G Zagni
new "Community Moderation and the New Epistemology of Fact Checking on Social Media"
with I Augenstein, M Bakker, T. Chakraborty, D. Corney, E
Ferrara, I Gurevych, S Hale, E Hovy, H Ji, I Larraz, F
Menczer, P Nakov, D Sahnan, G Warren, G Zagni
Reposted by Paolo Papotti

🌟 New paper alert! 🌟
Our paper, "Retrieve, Merge, Predict: Augmenting Tables with Data Lakes", has been published in TMLR!
In this work, we created YADL (a semi-synthetic data lake), and we benchmarked methods for augmenting user-provided tables given information found in data lakes.
1/
Our paper, "Retrieve, Merge, Predict: Augmenting Tables with Data Lakes", has been published in TMLR!
In this work, we created YADL (a semi-synthetic data lake), and we benchmarked methods for augmenting user-provided tables given information found in data lakes.
1/

May 19, 2025 at 3:43 PM
🌟 New paper alert! 🌟
Our paper, "Retrieve, Merge, Predict: Augmenting Tables with Data Lakes", has been published in TMLR!
In this work, we created YADL (a semi-synthetic data lake), and we benchmarked methods for augmenting user-provided tables given information found in data lakes.
1/
Our paper, "Retrieve, Merge, Predict: Augmenting Tables with Data Lakes", has been published in TMLR!
In this work, we created YADL (a semi-synthetic data lake), and we benchmarked methods for augmenting user-provided tables given information found in data lakes.
1/
Our new @sigmod2025.bsky.social paper tackles a fundamental challenge for the next gen of data systems: "Logical and Physical Optimizations for SQL Query Execution over Large Language Models" 📄
As systems increasingly use declarative interfaces on LLMs, traditional optimization falls short
Details 👇
As systems increasingly use declarative interfaces on LLMs, traditional optimization falls short
Details 👇
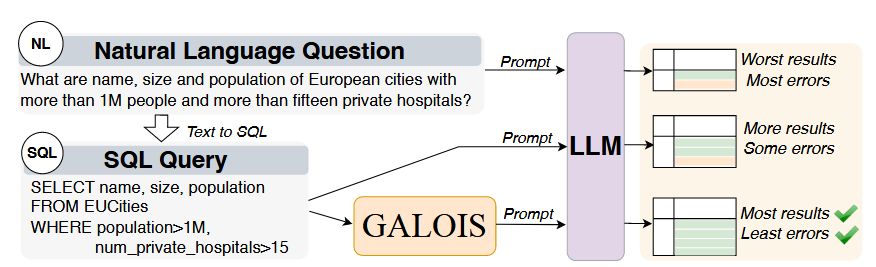
May 5, 2025 at 6:03 PM
Our new @sigmod2025.bsky.social paper tackles a fundamental challenge for the next gen of data systems: "Logical and Physical Optimizations for SQL Query Execution over Large Language Models" 📄
As systems increasingly use declarative interfaces on LLMs, traditional optimization falls short
Details 👇
As systems increasingly use declarative interfaces on LLMs, traditional optimization falls short
Details 👇
Presenting at #NAACL2025 today (April 30th) 🎤
⏰ 11:00 Session B
Our work, "An LLM-Based Approach for Insight Generation in Data Analysis," uses LLMs to automatically find insights in databases, outperforming baselines both in insightfulness and correctness
Paper: arxiv.org/abs/2503.11664
Details 👇
⏰ 11:00 Session B
Our work, "An LLM-Based Approach for Insight Generation in Data Analysis," uses LLMs to automatically find insights in databases, outperforming baselines both in insightfulness and correctness
Paper: arxiv.org/abs/2503.11664
Details 👇

April 30, 2025 at 9:35 AM
Presenting at #NAACL2025 today (April 30th) 🎤
⏰ 11:00 Session B
Our work, "An LLM-Based Approach for Insight Generation in Data Analysis," uses LLMs to automatically find insights in databases, outperforming baselines both in insightfulness and correctness
Paper: arxiv.org/abs/2503.11664
Details 👇
⏰ 11:00 Session B
Our work, "An LLM-Based Approach for Insight Generation in Data Analysis," uses LLMs to automatically find insights in databases, outperforming baselines both in insightfulness and correctness
Paper: arxiv.org/abs/2503.11664
Details 👇
Think2SQL: Bridging the Reasoning Gap in Text-to-SQL for Small LLMs
Leveraging RL with our reward mechanism, we push Qwen-Coder-2.5 7B to performance on par with much larger LLMs (>400B) on the BIRD dataset! 🤯
Model: huggingface.co/simone-papic...
Paper: huggingface.co/papers/2504....
Details 👇
Leveraging RL with our reward mechanism, we push Qwen-Coder-2.5 7B to performance on par with much larger LLMs (>400B) on the BIRD dataset! 🤯
Model: huggingface.co/simone-papic...
Paper: huggingface.co/papers/2504....
Details 👇

April 29, 2025 at 12:24 PM
Think2SQL: Bridging the Reasoning Gap in Text-to-SQL for Small LLMs
Leveraging RL with our reward mechanism, we push Qwen-Coder-2.5 7B to performance on par with much larger LLMs (>400B) on the BIRD dataset! 🤯
Model: huggingface.co/simone-papic...
Paper: huggingface.co/papers/2504....
Details 👇
Leveraging RL with our reward mechanism, we push Qwen-Coder-2.5 7B to performance on par with much larger LLMs (>400B) on the BIRD dataset! 🤯
Model: huggingface.co/simone-papic...
Paper: huggingface.co/papers/2504....
Details 👇
🗜️New LLM compression paper "Beyond RAG: Task-Aware KV Cache Compression for Comprehensive Knowledge Reasoning"
RAG struggles with broad, multi-hop questions.
We surpass RAG by up to 20 absolute points in QA performance, even with extreme cache compression (64x smaller)!
Details 👇
RAG struggles with broad, multi-hop questions.
We surpass RAG by up to 20 absolute points in QA performance, even with extreme cache compression (64x smaller)!
Details 👇

March 11, 2025 at 5:17 PM
🗜️New LLM compression paper "Beyond RAG: Task-Aware KV Cache Compression for Comprehensive Knowledge Reasoning"
RAG struggles with broad, multi-hop questions.
We surpass RAG by up to 20 absolute points in QA performance, even with extreme cache compression (64x smaller)!
Details 👇
RAG struggles with broad, multi-hop questions.
We surpass RAG by up to 20 absolute points in QA performance, even with extreme cache compression (64x smaller)!
Details 👇
NOVAS is a new venue for your paper bridging the gap between data management and generative AI research!
It will be in Berlin, June 22th, together with @sigmod2025.bsky.social
Submission deadline: 28 March 2025
It will be in Berlin, June 22th, together with @sigmod2025.bsky.social
Submission deadline: 28 March 2025
NOVAS - The Novel Optimizations for Visionary AI Systems is co-located with SIGMOD/PODS 2025. Submission deadline is 28th of March. Find more information on the workshop and submission instructions on the website.
www.novasworkshop.org
www.novasworkshop.org

NOVAS Workshop
NOVAS stands for Novel Optimizations for Visionary AI Systems.
We want to bridge the gap between "data management'' and "generative AI'' research.
www.novasworkshop.org
January 29, 2025 at 9:20 AM
NOVAS is a new venue for your paper bridging the gap between data management and generative AI research!
It will be in Berlin, June 22th, together with @sigmod2025.bsky.social
Submission deadline: 28 March 2025
It will be in Berlin, June 22th, together with @sigmod2025.bsky.social
Submission deadline: 28 March 2025
Tropes, such as "Hidden Motives", are recurring narrative elements used to evoke familiar patterns in communication
Our #COLING paper uncovers that tropes are used in 37% of the social posts debating immigration and vaccination
📄 coling-2025-proceedings.s3.us-east-1.amazonaws.com/main/pdf/202...
👇
Our #COLING paper uncovers that tropes are used in 37% of the social posts debating immigration and vaccination
📄 coling-2025-proceedings.s3.us-east-1.amazonaws.com/main/pdf/202...
👇

January 23, 2025 at 8:24 AM
Tropes, such as "Hidden Motives", are recurring narrative elements used to evoke familiar patterns in communication
Our #COLING paper uncovers that tropes are used in 37% of the social posts debating immigration and vaccination
📄 coling-2025-proceedings.s3.us-east-1.amazonaws.com/main/pdf/202...
👇
Our #COLING paper uncovers that tropes are used in 37% of the social posts debating immigration and vaccination
📄 coling-2025-proceedings.s3.us-east-1.amazonaws.com/main/pdf/202...
👇
Meta is also embracing Community Notes (as now branded on X), the crowdsourcing approach to fact-checking on social networks.
We have audited the program when it was called Birdwatch and found both promising results and concerning manipulation risks. More details below.👇
We have audited the program when it was called Birdwatch and found both promising results and concerning manipulation risks. More details below.👇
Crowdsourced Fact-Checking at Twitter: How Does the Crowd Compare With Experts?
Fact-checking is one of the effective solutions in fighting online misinformation. However, traditional fact-checking is a process requiring scarce expert human resources, and thus does not scale well...
arxiv.org
January 7, 2025 at 4:55 PM
Meta is also embracing Community Notes (as now branded on X), the crowdsourcing approach to fact-checking on social networks.
We have audited the program when it was called Birdwatch and found both promising results and concerning manipulation risks. More details below.👇
We have audited the program when it was called Birdwatch and found both promising results and concerning manipulation risks. More details below.👇
🚀 Up to 93x input compression for LLMs!
By compressing the data in the KV cache, we squeeze more info in the context.
Presented at @emnlpmeeting.bsky.social, now on MIT Press:
FINCH: Prompt-guided Key-Value Cache Compression for LLMs (TACL 2024)
direct.mit.edu/tacl/article...
More details 👇
By compressing the data in the KV cache, we squeeze more info in the context.
Presented at @emnlpmeeting.bsky.social, now on MIT Press:
FINCH: Prompt-guided Key-Value Cache Compression for LLMs (TACL 2024)
direct.mit.edu/tacl/article...
More details 👇

FINCH: Prompt-guided Key-Value Cache Compression for Large Language Models
Abstract. Recent large language model applications, such as Retrieval-Augmented Generation and chatbots, have led to an increased need to process longer input contexts. However, this requirement is ha...
direct.mit.edu
November 24, 2024 at 4:44 PM
🚀 Up to 93x input compression for LLMs!
By compressing the data in the KV cache, we squeeze more info in the context.
Presented at @emnlpmeeting.bsky.social, now on MIT Press:
FINCH: Prompt-guided Key-Value Cache Compression for LLMs (TACL 2024)
direct.mit.edu/tacl/article...
More details 👇
By compressing the data in the KV cache, we squeeze more info in the context.
Presented at @emnlpmeeting.bsky.social, now on MIT Press:
FINCH: Prompt-guided Key-Value Cache Compression for LLMs (TACL 2024)
direct.mit.edu/tacl/article...
More details 👇
Reposted by Paolo Papotti

WIP starterpack w researchers on Table Representation Learning (TRL): all things related to representation learning and generative models for e.g. tables, DBs, spreadsheets!
I'll curate but DM/reply w handle+some info welcome! Also follow @trl-research.bsky.social for updates 🤗
go.bsky.app/4SNSMRj
I'll curate but DM/reply w handle+some info welcome! Also follow @trl-research.bsky.social for updates 🤗
go.bsky.app/4SNSMRj

Table Representation Learning researchers
Join the conversation
go.bsky.app
November 18, 2024 at 10:48 AM
WIP starterpack w researchers on Table Representation Learning (TRL): all things related to representation learning and generative models for e.g. tables, DBs, spreadsheets!
I'll curate but DM/reply w handle+some info welcome! Also follow @trl-research.bsky.social for updates 🤗
go.bsky.app/4SNSMRj
I'll curate but DM/reply w handle+some info welcome! Also follow @trl-research.bsky.social for updates 🤗
go.bsky.app/4SNSMRj
CimpleKG is a continuously updated resource for researchers developing AI solutions to fight misinformation.
The graph links data from 77 fact-checking orgs across 36 countries.
🔗 SPARQL Endpoint: purl.org/net/cimplekg...
🔗 KG Explorer: purl.org/net/cimplekg...
🔗 Paper: hal.science/hal-04760374...
The graph links data from 77 fact-checking orgs across 36 countries.
🔗 SPARQL Endpoint: purl.org/net/cimplekg...
🔗 KG Explorer: purl.org/net/cimplekg...
🔗 Paper: hal.science/hal-04760374...
"CimpleKG: A Continuously Updated Knowledge Graph on Misinformation, Factors and Fact-Checks", won the Best Resource Paper award at #iswc2024. Check out github.com/CIMPLE-proje... for the resource


November 18, 2024 at 7:50 AM
CimpleKG is a continuously updated resource for researchers developing AI solutions to fight misinformation.
The graph links data from 77 fact-checking orgs across 36 countries.
🔗 SPARQL Endpoint: purl.org/net/cimplekg...
🔗 KG Explorer: purl.org/net/cimplekg...
🔗 Paper: hal.science/hal-04760374...
The graph links data from 77 fact-checking orgs across 36 countries.
🔗 SPARQL Endpoint: purl.org/net/cimplekg...
🔗 KG Explorer: purl.org/net/cimplekg...
🔗 Paper: hal.science/hal-04760374...
𝗘𝘃𝗲𝗿 𝗰𝗼𝗻𝘀𝗶𝗱𝗲𝗿𝗲𝗱 𝘄𝗼𝗿𝗸𝗶𝗻𝗴 𝗶𝗻 𝘁𝗵𝗲 𝗙𝗿𝗲𝗻𝗰𝗵 𝗥𝗶𝘃𝗶𝗲𝗿𝗮? ☀
I'm seeking PhD and Post-doc candidates to join my research group in 2025 at EURECOM in the south of France.
- 3 new projects on LLMs
- Full-time positions with competitive salaries and benefits
- English-speaking environment
Interested? Ping me!
I'm seeking PhD and Post-doc candidates to join my research group in 2025 at EURECOM in the south of France.
- 3 new projects on LLMs
- Full-time positions with competitive salaries and benefits
- English-speaking environment
Interested? Ping me!

November 16, 2024 at 9:51 AM
𝗘𝘃𝗲𝗿 𝗰𝗼𝗻𝘀𝗶𝗱𝗲𝗿𝗲𝗱 𝘄𝗼𝗿𝗸𝗶𝗻𝗴 𝗶𝗻 𝘁𝗵𝗲 𝗙𝗿𝗲𝗻𝗰𝗵 𝗥𝗶𝘃𝗶𝗲𝗿𝗮? ☀
I'm seeking PhD and Post-doc candidates to join my research group in 2025 at EURECOM in the south of France.
- 3 new projects on LLMs
- Full-time positions with competitive salaries and benefits
- English-speaking environment
Interested? Ping me!
I'm seeking PhD and Post-doc candidates to join my research group in 2025 at EURECOM in the south of France.
- 3 new projects on LLMs
- Full-time positions with competitive salaries and benefits
- English-speaking environment
Interested? Ping me!
Our paper, "Data Void Exploits: Tracking & Mitigation Strategies," has received the Best Paper Award at
ACM #CIKM 2024! 🏆
Data voids are gaps in online information, which are often exploit to spread disinformation.
More details 👇
#CIKM2024 #DataVoids #Disinformation #KGs
ACM #CIKM 2024! 🏆
Data voids are gaps in online information, which are often exploit to spread disinformation.
More details 👇
#CIKM2024 #DataVoids #Disinformation #KGs

November 16, 2024 at 9:46 AM
Our paper, "Data Void Exploits: Tracking & Mitigation Strategies," has received the Best Paper Award at
ACM #CIKM 2024! 🏆
Data voids are gaps in online information, which are often exploit to spread disinformation.
More details 👇
#CIKM2024 #DataVoids #Disinformation #KGs
ACM #CIKM 2024! 🏆
Data voids are gaps in online information, which are often exploit to spread disinformation.
More details 👇
#CIKM2024 #DataVoids #Disinformation #KGs
Hi everyone!
I'm a professor in the Data Science department at EURECOM, France. 🎓
My research focuses on data management and LLMs to enhance information quality, including data cleaning and misinformation detection.
I'm here mostly for the research, but I occasionally comment on sports and arts.
I'm a professor in the Data Science department at EURECOM, France. 🎓
My research focuses on data management and LLMs to enhance information quality, including data cleaning and misinformation detection.
I'm here mostly for the research, but I occasionally comment on sports and arts.
November 16, 2024 at 9:21 AM
Hi everyone!
I'm a professor in the Data Science department at EURECOM, France. 🎓
My research focuses on data management and LLMs to enhance information quality, including data cleaning and misinformation detection.
I'm here mostly for the research, but I occasionally comment on sports and arts.
I'm a professor in the Data Science department at EURECOM, France. 🎓
My research focuses on data management and LLMs to enhance information quality, including data cleaning and misinformation detection.
I'm here mostly for the research, but I occasionally comment on sports and arts.