




Paolo Papotti
@papotti.bsky.social
Associate Prof at EURECOM and 3IA Côte d'Azur Chair of Artificial Intelligence. ELLIS member.
Data management and NLP/LLMs for information quality.
https://www.eurecom.fr/~papotti/
Data management and NLP/LLMs for information quality.
https://www.eurecom.fr/~papotti/
Our new paper, "RelationalFactQA: A Benchmark for Evaluating Tabular Fact Retrieval from Large Language Models", measures exactly this gap.
Wider or longer output tables = tougher for all LLMs! 🧨
From Llama 3 and Qwen to GPT-4, no LLM goes above 25% accuracy on our stricter measure.
Wider or longer output tables = tougher for all LLMs! 🧨
From Llama 3 and Qwen to GPT-4, no LLM goes above 25% accuracy on our stricter measure.

June 2, 2025 at 2:51 PM
Our new paper, "RelationalFactQA: A Benchmark for Evaluating Tabular Fact Retrieval from Large Language Models", measures exactly this gap.
Wider or longer output tables = tougher for all LLMs! 🧨
From Llama 3 and Qwen to GPT-4, no LLM goes above 25% accuracy on our stricter measure.
Wider or longer output tables = tougher for all LLMs! 🧨
From Llama 3 and Qwen to GPT-4, no LLM goes above 25% accuracy on our stricter measure.
Platforms like X are outsourcing fact-checking to users via tools like Community Notes. But what does this mean for truth online?
We argue this isn’t just a technical shift — it’s an epistemological transformation. Who gets to define what's true when everyone is the fact-checker?
We argue this isn’t just a technical shift — it’s an epistemological transformation. Who gets to define what's true when everyone is the fact-checker?

June 1, 2025 at 7:48 AM
Platforms like X are outsourcing fact-checking to users via tools like Community Notes. But what does this mean for truth online?
We argue this isn’t just a technical shift — it’s an epistemological transformation. Who gets to define what's true when everyone is the fact-checker?
We argue this isn’t just a technical shift — it’s an epistemological transformation. Who gets to define what's true when everyone is the fact-checker?
This cost/quality trade-off is guided by dynamically estimated metadata instead of relying on traditional stats.
Result: Significant quality gains (+29%) without prohibitive costs. Works across LLMs & for internal knowledge + in-context data (RAG-like setup, reported results in the figure). ✅
Result: Significant quality gains (+29%) without prohibitive costs. Works across LLMs & for internal knowledge + in-context data (RAG-like setup, reported results in the figure). ✅

May 5, 2025 at 6:03 PM
This cost/quality trade-off is guided by dynamically estimated metadata instead of relying on traditional stats.
Result: Significant quality gains (+29%) without prohibitive costs. Works across LLMs & for internal knowledge + in-context data (RAG-like setup, reported results in the figure). ✅
Result: Significant quality gains (+29%) without prohibitive costs. Works across LLMs & for internal knowledge + in-context data (RAG-like setup, reported results in the figure). ✅
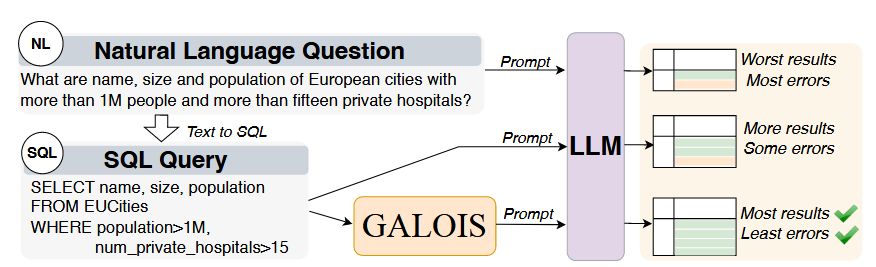
With our Galois system, we show one path to adapt database optimization for LLMs:
🔹 Designing physical operators tailored to LLM interaction nuances (e.g., Table-Scan vs Key-Scan in the figure).
🔹 Rethinking logical optimization (like pushdowns) for a cost/quality trade-off.
🔹 Designing physical operators tailored to LLM interaction nuances (e.g., Table-Scan vs Key-Scan in the figure).
🔹 Rethinking logical optimization (like pushdowns) for a cost/quality trade-off.

May 5, 2025 at 6:03 PM
With our Galois system, we show one path to adapt database optimization for LLMs:
🔹 Designing physical operators tailored to LLM interaction nuances (e.g., Table-Scan vs Key-Scan in the figure).
🔹 Rethinking logical optimization (like pushdowns) for a cost/quality trade-off.
🔹 Designing physical operators tailored to LLM interaction nuances (e.g., Table-Scan vs Key-Scan in the figure).
🔹 Rethinking logical optimization (like pushdowns) for a cost/quality trade-off.
Why do traditional methods fail? They prioritize execution cost & ignore crucial LLM response quality (factuality, completeness).
Our results show standard techniques like predicate pushdown can even reduce result quality by making LLM prompts more complex to process accurately. 🤔
Our results show standard techniques like predicate pushdown can even reduce result quality by making LLM prompts more complex to process accurately. 🤔

May 5, 2025 at 6:03 PM
Why do traditional methods fail? They prioritize execution cost & ignore crucial LLM response quality (factuality, completeness).
Our results show standard techniques like predicate pushdown can even reduce result quality by making LLM prompts more complex to process accurately. 🤔
Our results show standard techniques like predicate pushdown can even reduce result quality by making LLM prompts more complex to process accurately. 🤔
Our new @sigmod2025.bsky.social paper tackles a fundamental challenge for the next gen of data systems: "Logical and Physical Optimizations for SQL Query Execution over Large Language Models" 📄
As systems increasingly use declarative interfaces on LLMs, traditional optimization falls short
Details 👇
As systems increasingly use declarative interfaces on LLMs, traditional optimization falls short
Details 👇
May 5, 2025 at 6:03 PM
Our new @sigmod2025.bsky.social paper tackles a fundamental challenge for the next gen of data systems: "Logical and Physical Optimizations for SQL Query Execution over Large Language Models" 📄
As systems increasingly use declarative interfaces on LLMs, traditional optimization falls short
Details 👇
As systems increasingly use declarative interfaces on LLMs, traditional optimization falls short
Details 👇
Presenting at #NAACL2025 today (April 30th) 🎤
⏰ 11:00 Session B
Our work, "An LLM-Based Approach for Insight Generation in Data Analysis," uses LLMs to automatically find insights in databases, outperforming baselines both in insightfulness and correctness
Paper: arxiv.org/abs/2503.11664
Details 👇
⏰ 11:00 Session B
Our work, "An LLM-Based Approach for Insight Generation in Data Analysis," uses LLMs to automatically find insights in databases, outperforming baselines both in insightfulness and correctness
Paper: arxiv.org/abs/2503.11664
Details 👇

April 30, 2025 at 9:35 AM
Presenting at #NAACL2025 today (April 30th) 🎤
⏰ 11:00 Session B
Our work, "An LLM-Based Approach for Insight Generation in Data Analysis," uses LLMs to automatically find insights in databases, outperforming baselines both in insightfulness and correctness
Paper: arxiv.org/abs/2503.11664
Details 👇
⏰ 11:00 Session B
Our work, "An LLM-Based Approach for Insight Generation in Data Analysis," uses LLMs to automatically find insights in databases, outperforming baselines both in insightfulness and correctness
Paper: arxiv.org/abs/2503.11664
Details 👇
We evaluate 4 training strategies:
1️⃣ Zero-Shot Learning (ZSL) +/- general-purpose reasoning
2️⃣ Supervised Fine Tuning (SFT) +/- task-specific reasoning traces
3️⃣ Reinforcement Learning (RL) with EXecution accuracy (EX) vs. our fine-grained rewards
4️⃣ Combined SFT+RL approach
1️⃣ Zero-Shot Learning (ZSL) +/- general-purpose reasoning
2️⃣ Supervised Fine Tuning (SFT) +/- task-specific reasoning traces
3️⃣ Reinforcement Learning (RL) with EXecution accuracy (EX) vs. our fine-grained rewards
4️⃣ Combined SFT+RL approach

April 29, 2025 at 12:24 PM
We evaluate 4 training strategies:
1️⃣ Zero-Shot Learning (ZSL) +/- general-purpose reasoning
2️⃣ Supervised Fine Tuning (SFT) +/- task-specific reasoning traces
3️⃣ Reinforcement Learning (RL) with EXecution accuracy (EX) vs. our fine-grained rewards
4️⃣ Combined SFT+RL approach
1️⃣ Zero-Shot Learning (ZSL) +/- general-purpose reasoning
2️⃣ Supervised Fine Tuning (SFT) +/- task-specific reasoning traces
3️⃣ Reinforcement Learning (RL) with EXecution accuracy (EX) vs. our fine-grained rewards
4️⃣ Combined SFT+RL approach
Think2SQL: Bridging the Reasoning Gap in Text-to-SQL for Small LLMs
Leveraging RL with our reward mechanism, we push Qwen-Coder-2.5 7B to performance on par with much larger LLMs (>400B) on the BIRD dataset! 🤯
Model: huggingface.co/simone-papic...
Paper: huggingface.co/papers/2504....
Details 👇
Leveraging RL with our reward mechanism, we push Qwen-Coder-2.5 7B to performance on par with much larger LLMs (>400B) on the BIRD dataset! 🤯
Model: huggingface.co/simone-papic...
Paper: huggingface.co/papers/2504....
Details 👇

April 29, 2025 at 12:24 PM
Think2SQL: Bridging the Reasoning Gap in Text-to-SQL for Small LLMs
Leveraging RL with our reward mechanism, we push Qwen-Coder-2.5 7B to performance on par with much larger LLMs (>400B) on the BIRD dataset! 🤯
Model: huggingface.co/simone-papic...
Paper: huggingface.co/papers/2504....
Details 👇
Leveraging RL with our reward mechanism, we push Qwen-Coder-2.5 7B to performance on par with much larger LLMs (>400B) on the BIRD dataset! 🤯
Model: huggingface.co/simone-papic...
Paper: huggingface.co/papers/2504....
Details 👇
Our method reduces the inference latency dramatically, making it 2x faster than RAG and practical for real-world scenarios.🚀

March 11, 2025 at 5:17 PM
Our method reduces the inference latency dramatically, making it 2x faster than RAG and practical for real-world scenarios.🚀
Experiments on our synthetic dataset, LongBench-v2, and LongBench show KVCompress excels at broad queries needing information synthesis, while RAG suits narrow queries. For query-agnostic tasks like summarization and code completion, KVCompress strongly outperforms RAG.

March 11, 2025 at 5:17 PM
Experiments on our synthetic dataset, LongBench-v2, and LongBench show KVCompress excels at broad queries needing information synthesis, while RAG suits narrow queries. For query-agnostic tasks like summarization and code completion, KVCompress strongly outperforms RAG.
Inspired by students condensing notes for exams, our method compresses offline an entire corpus using just a task description and few-shot examples. This compressed cache then efficiently answers multiple queries online without recompression.

March 11, 2025 at 5:17 PM
Inspired by students condensing notes for exams, our method compresses offline an entire corpus using just a task description and few-shot examples. This compressed cache then efficiently answers multiple queries online without recompression.
🗜️New LLM compression paper "Beyond RAG: Task-Aware KV Cache Compression for Comprehensive Knowledge Reasoning"
RAG struggles with broad, multi-hop questions.
We surpass RAG by up to 20 absolute points in QA performance, even with extreme cache compression (64x smaller)!
Details 👇
RAG struggles with broad, multi-hop questions.
We surpass RAG by up to 20 absolute points in QA performance, even with extreme cache compression (64x smaller)!
Details 👇

March 11, 2025 at 5:17 PM
🗜️New LLM compression paper "Beyond RAG: Task-Aware KV Cache Compression for Comprehensive Knowledge Reasoning"
RAG struggles with broad, multi-hop questions.
We surpass RAG by up to 20 absolute points in QA performance, even with extreme cache compression (64x smaller)!
Details 👇
RAG struggles with broad, multi-hop questions.
We surpass RAG by up to 20 absolute points in QA performance, even with extreme cache compression (64x smaller)!
Details 👇
Tropes, such as "Hidden Motives", are recurring narrative elements used to evoke familiar patterns in communication
Our #COLING paper uncovers that tropes are used in 37% of the social posts debating immigration and vaccination
📄 coling-2025-proceedings.s3.us-east-1.amazonaws.com/main/pdf/202...
👇
Our #COLING paper uncovers that tropes are used in 37% of the social posts debating immigration and vaccination
📄 coling-2025-proceedings.s3.us-east-1.amazonaws.com/main/pdf/202...
👇

January 23, 2025 at 8:24 AM
Tropes, such as "Hidden Motives", are recurring narrative elements used to evoke familiar patterns in communication
Our #COLING paper uncovers that tropes are used in 37% of the social posts debating immigration and vaccination
📄 coling-2025-proceedings.s3.us-east-1.amazonaws.com/main/pdf/202...
👇
Our #COLING paper uncovers that tropes are used in 37% of the social posts debating immigration and vaccination
📄 coling-2025-proceedings.s3.us-east-1.amazonaws.com/main/pdf/202...
👇
We report results for a data-driven analysis of the birdwatch (CN) program through the lens of the three main components of a fact-checking pipeline: claim detection, evidence retrieval, and claim verification. We compare the performance with expert fact-checkers and computational methods.

January 7, 2025 at 4:55 PM
We report results for a data-driven analysis of the birdwatch (CN) program through the lens of the three main components of a fact-checking pipeline: claim detection, evidence retrieval, and claim verification. We compare the performance with expert fact-checkers and computational methods.
LLMs face GPU memory constraints when handling large inputs. FINCH optimizes resource usage, making applications with extensive input processing more viable, e.g., from 4.5 GB to .6GB for KB cache.
No more large GPUs needed on long context scenarios!
No more large GPUs needed on long context scenarios!

November 24, 2024 at 4:44 PM
LLMs face GPU memory constraints when handling large inputs. FINCH optimizes resource usage, making applications with extensive input processing more viable, e.g., from 4.5 GB to .6GB for KB cache.
No more large GPUs needed on long context scenarios!
No more large GPUs needed on long context scenarios!
With compression ratios up to 93x, FINCH achieves comparable generation quality while being faster and more memory-efficient than other methods on SQuAD v2 and LongBench benchmarks (including question answering, summarization, and code completion tasks)

November 24, 2024 at 4:44 PM
With compression ratios up to 93x, FINCH achieves comparable generation quality while being faster and more memory-efficient than other methods on SQuAD v2 and LongBench benchmarks (including question answering, summarization, and code completion tasks)
Instead of recalculating everything for each token, FINCH identifies the most relevant Key (K) and Value (V) pairs using pre-trained weights of the self-attention mechanism. This reduces the memory footprint while preserving the quality of the output.

November 24, 2024 at 4:44 PM
Instead of recalculating everything for each token, FINCH identifies the most relevant Key (K) and Value (V) pairs using pre-trained weights of the self-attention mechanism. This reduces the memory footprint while preserving the quality of the output.
FINCH is a method for compressing input context by selectively storing only the most relevant Key-Value pairs in the cache. It’s designed to help decoder-based LLMs process longer texts efficiently without the need for fine-tuning.

November 24, 2024 at 4:44 PM
FINCH is a method for compressing input context by selectively storing only the most relevant Key-Value pairs in the cache. It’s designed to help decoder-based LLMs process longer texts efficiently without the need for fine-tuning.
𝗘𝘃𝗲𝗿 𝗰𝗼𝗻𝘀𝗶𝗱𝗲𝗿𝗲𝗱 𝘄𝗼𝗿𝗸𝗶𝗻𝗴 𝗶𝗻 𝘁𝗵𝗲 𝗙𝗿𝗲𝗻𝗰𝗵 𝗥𝗶𝘃𝗶𝗲𝗿𝗮? ☀
I'm seeking PhD and Post-doc candidates to join my research group in 2025 at EURECOM in the south of France.
- 3 new projects on LLMs
- Full-time positions with competitive salaries and benefits
- English-speaking environment
Interested? Ping me!
I'm seeking PhD and Post-doc candidates to join my research group in 2025 at EURECOM in the south of France.
- 3 new projects on LLMs
- Full-time positions with competitive salaries and benefits
- English-speaking environment
Interested? Ping me!

November 16, 2024 at 9:51 AM
𝗘𝘃𝗲𝗿 𝗰𝗼𝗻𝘀𝗶𝗱𝗲𝗿𝗲𝗱 𝘄𝗼𝗿𝗸𝗶𝗻𝗴 𝗶𝗻 𝘁𝗵𝗲 𝗙𝗿𝗲𝗻𝗰𝗵 𝗥𝗶𝘃𝗶𝗲𝗿𝗮? ☀
I'm seeking PhD and Post-doc candidates to join my research group in 2025 at EURECOM in the south of France.
- 3 new projects on LLMs
- Full-time positions with competitive salaries and benefits
- English-speaking environment
Interested? Ping me!
I'm seeking PhD and Post-doc candidates to join my research group in 2025 at EURECOM in the south of France.
- 3 new projects on LLMs
- Full-time positions with competitive salaries and benefits
- English-speaking environment
Interested? Ping me!
Paper: dl.acm.org/doi/10.1145/...
A huge thank you to the team at NYU-AD (Miro Mannino, Junior Francisco Garcia Ayala, Reem Hazim, and Azza Abouzied) for their dedication to this joint effort!
thanks also to the cikm 2024 organizers and the award committee!
A huge thank you to the team at NYU-AD (Miro Mannino, Junior Francisco Garcia Ayala, Reem Hazim, and Azza Abouzied) for their dedication to this joint effort!
thanks also to the cikm 2024 organizers and the award committee!

November 16, 2024 at 9:46 AM
Paper: dl.acm.org/doi/10.1145/...
A huge thank you to the team at NYU-AD (Miro Mannino, Junior Francisco Garcia Ayala, Reem Hazim, and Azza Abouzied) for their dedication to this joint effort!
thanks also to the cikm 2024 organizers and the award committee!
A huge thank you to the team at NYU-AD (Miro Mannino, Junior Francisco Garcia Ayala, Reem Hazim, and Azza Abouzied) for their dedication to this joint effort!
thanks also to the cikm 2024 organizers and the award committee!
In our paper, we explore lightweight strategies to track and mitigate these exploits, using case studies to showcase their effectiveness in both Web search and Knowledge Graph querying contexts.

November 16, 2024 at 9:46 AM
In our paper, we explore lightweight strategies to track and mitigate these exploits, using case studies to showcase their effectiveness in both Web search and Knowledge Graph querying contexts.
Our paper, "Data Void Exploits: Tracking & Mitigation Strategies," has received the Best Paper Award at
ACM #CIKM 2024! 🏆
Data voids are gaps in online information, which are often exploit to spread disinformation.
More details 👇
#CIKM2024 #DataVoids #Disinformation #KGs
ACM #CIKM 2024! 🏆
Data voids are gaps in online information, which are often exploit to spread disinformation.
More details 👇
#CIKM2024 #DataVoids #Disinformation #KGs

November 16, 2024 at 9:46 AM
Our paper, "Data Void Exploits: Tracking & Mitigation Strategies," has received the Best Paper Award at
ACM #CIKM 2024! 🏆
Data voids are gaps in online information, which are often exploit to spread disinformation.
More details 👇
#CIKM2024 #DataVoids #Disinformation #KGs
ACM #CIKM 2024! 🏆
Data voids are gaps in online information, which are often exploit to spread disinformation.
More details 👇
#CIKM2024 #DataVoids #Disinformation #KGs