


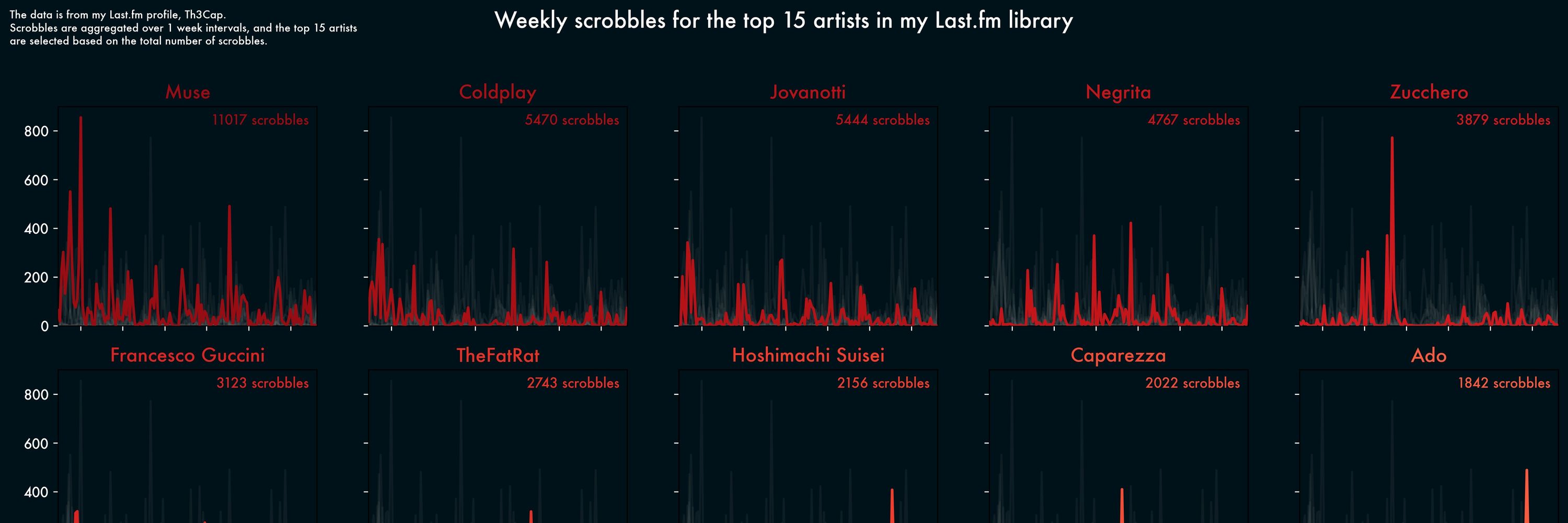

Riccardo Cappuzzo
@riccardocappuzzo.com
Research engineer at Inria Saclay, working on the Skrub library.
Python, data preparation, ML, tabular learning.
ORCID: 0000-0002-4448-2959
Hoshiyomi ☄️
https://www.riccardocappuzzo.com
https://github.com/rcap107
Python, data preparation, ML, tabular learning.
ORCID: 0000-0002-4448-2959
Hoshiyomi ☄️
https://www.riccardocappuzzo.com
https://github.com/rcap107
Random question shot into the ether: if I'm relying on VSCode's interactive windows to emulate notebooks, what are some reasons why I should switch to @marimo.io notebooks?
I haven't looked into marimo's features, so maybe I'm missing out on things I can't do from VSCode.
I haven't looked into marimo's features, so maybe I'm missing out on things I can't do from VSCode.
January 2, 2026 at 11:43 PM
Random question shot into the ether: if I'm relying on VSCode's interactive windows to emulate notebooks, what are some reasons why I should switch to @marimo.io notebooks?
I haven't looked into marimo's features, so maybe I'm missing out on things I can't do from VSCode.
I haven't looked into marimo's features, so maybe I'm missing out on things I can't do from VSCode.
That's me! It was a fun presentation and we got a lot of interesting questions
Also people laughed at the memes which is the most important thing, obviously
Also people laughed at the memes which is the most important thing, obviously
The recording of the talk we did at @pydataparis.bsky.social 2025 is now available on the PyData Youtube channel! 🚀
You can find it here, if you want to check it out 👀
www.youtube.com/watch?v=k9MN...
You can find it here, if you want to check it out 👀
www.youtube.com/watch?v=k9MN...

Skrub: machine learning for dataframes
YouTube video by PyData
www.youtube.com
December 16, 2025 at 11:05 PM
That's me! It was a fun presentation and we got a lot of interesting questions
Also people laughed at the memes which is the most important thing, obviously
Also people laughed at the memes which is the most important thing, obviously
"ok the test run is done, let's see"
...
"this will be hard to debug"
...
"this will be hard to debug"

October 9, 2025 at 1:29 PM
"ok the test run is done, let's see"
...
"this will be hard to debug"
...
"this will be hard to debug"
Reposted by Riccardo Cappuzzo

What a banger is skrub @skrub-data.bsky.social !
Big thumbs up for the sklearn team & the maintainer of this package
Big thumbs up for the sklearn team & the maintainer of this package

October 1, 2025 at 8:24 AM
What a banger is skrub @skrub-data.bsky.social !
Big thumbs up for the sklearn team & the maintainer of this package
Big thumbs up for the sklearn team & the maintainer of this package
My first actual talk in front of a ton of people 🙃
📅 Less than a week away! The talk will be on Oct 1st at 10.05AM in room Louis Armand 1 - Est.
If you want to contribute to skrub, we will also have a sprint on Thursday.
See you there!
If you want to contribute to skrub, we will also have a sprint on Thursday.
See you there!
📢 Talk Announcement
"Skrub: machine learning for dataframes", by Guillaume Lemaitre, Jérôme Dockès and @riccardocappuzzo.com.
@skrub-data.bsky.social
📜 Talk info: pretalx.com/pydata-paris-2025/talk/T9KTPU
📅 Schedule: pydata.org/paris2025/schedule
🎟 Tickets: pydata.org/paris2025/tickets
"Skrub: machine learning for dataframes", by Guillaume Lemaitre, Jérôme Dockès and @riccardocappuzzo.com.
@skrub-data.bsky.social
📜 Talk info: pretalx.com/pydata-paris-2025/talk/T9KTPU
📅 Schedule: pydata.org/paris2025/schedule
🎟 Tickets: pydata.org/paris2025/tickets
September 26, 2025 at 8:52 AM
My first actual talk in front of a ton of people 🙃
TIL about lava lamp encryption
www.cloudflare.com/learning/ssl...
www.cloudflare.com/learning/ssl...

How do lava lamps help with Internet encryption?
The Cloudflare lava lamps are used for Internet encryption. Learn about entropy in cryptography and why randomness is essential for SSL encryption.
www.cloudflare.com
September 5, 2025 at 3:49 PM
TIL about lava lamp encryption
www.cloudflare.com/learning/ssl...
www.cloudflare.com/learning/ssl...
Reposted by Riccardo Cappuzzo

Do you have to deal with numerical features that involve large outliers, and need to train linear models or neural networks?
Then you might want to try the skrub SquashingScaler. The SquashingScaler behaves like scikit-learn RobustScaler, but smoothly clips outliers to predefined boundaries.
Then you might want to try the skrub SquashingScaler. The SquashingScaler behaves like scikit-learn RobustScaler, but smoothly clips outliers to predefined boundaries.

September 5, 2025 at 8:47 AM
Do you have to deal with numerical features that involve large outliers, and need to train linear models or neural networks?
Then you might want to try the skrub SquashingScaler. The SquashingScaler behaves like scikit-learn RobustScaler, but smoothly clips outliers to predefined boundaries.
Then you might want to try the skrub SquashingScaler. The SquashingScaler behaves like scikit-learn RobustScaler, but smoothly clips outliers to predefined boundaries.
Working hard on the next @skrub-data.bsky.social slide deck...


September 4, 2025 at 10:19 PM
Working hard on the next @skrub-data.bsky.social slide deck...
Reposted by Riccardo Cappuzzo

Today at #EuroScipy2025, @glemaitre58.bsky.social and I presented a tutorial on pitfalls of machine learning for imbalanced classification problems.
We discussed what (not) to do when fitting a classifier and obtaining degenerate precision or recall values.
probabl-ai.github.io/calibration-...
We discussed what (not) to do when fitting a classifier and obtaining degenerate precision or recall values.
probabl-ai.github.io/calibration-...
Imbalanced classification: pitfalls and solutions — Probabilistic calibration of cost-sensitive learning
probabl-ai.github.io
August 19, 2025 at 11:58 AM
Today at #EuroScipy2025, @glemaitre58.bsky.social and I presented a tutorial on pitfalls of machine learning for imbalanced classification problems.
We discussed what (not) to do when fitting a classifier and obtaining degenerate precision or recall values.
probabl-ai.github.io/calibration-...
We discussed what (not) to do when fitting a classifier and obtaining degenerate precision or recall values.
probabl-ai.github.io/calibration-...
Reposted by Riccardo Cappuzzo

📢 Talk Announcement
"Skrub: machine learning for dataframes", by Guillaume Lemaitre, Jérôme Dockès and @riccardocappuzzo.com.
@skrub-data.bsky.social
📜 Talk info: pretalx.com/pydata-paris-2025/talk/T9KTPU
📅 Schedule: pydata.org/paris2025/schedule
🎟 Tickets: pydata.org/paris2025/tickets
"Skrub: machine learning for dataframes", by Guillaume Lemaitre, Jérôme Dockès and @riccardocappuzzo.com.
@skrub-data.bsky.social
📜 Talk info: pretalx.com/pydata-paris-2025/talk/T9KTPU
📅 Schedule: pydata.org/paris2025/schedule
🎟 Tickets: pydata.org/paris2025/tickets

August 12, 2025 at 7:00 AM
📢 Talk Announcement
"Skrub: machine learning for dataframes", by Guillaume Lemaitre, Jérôme Dockès and @riccardocappuzzo.com.
@skrub-data.bsky.social
📜 Talk info: pretalx.com/pydata-paris-2025/talk/T9KTPU
📅 Schedule: pydata.org/paris2025/schedule
🎟 Tickets: pydata.org/paris2025/tickets
"Skrub: machine learning for dataframes", by Guillaume Lemaitre, Jérôme Dockès and @riccardocappuzzo.com.
@skrub-data.bsky.social
📜 Talk info: pretalx.com/pydata-paris-2025/talk/T9KTPU
📅 Schedule: pydata.org/paris2025/schedule
🎟 Tickets: pydata.org/paris2025/tickets
Reposted by Riccardo Cappuzzo
Attending the @skrub-data.bsky.social tutorial by @riccardocappuzzo.com and @glemaitre58.bsky.social at #EuroScipy2025. They introduce the new DataOps feature released in skrub 0.6.
Here is the repo with the material for the tutorial: github.com/skrub-data/E...
Here is the repo with the material for the tutorial: github.com/skrub-data/E...

August 18, 2025 at 9:08 AM
Attending the @skrub-data.bsky.social tutorial by @riccardocappuzzo.com and @glemaitre58.bsky.social at #EuroScipy2025. They introduce the new DataOps feature released in skrub 0.6.
Here is the repo with the material for the tutorial: github.com/skrub-data/E...
Here is the repo with the material for the tutorial: github.com/skrub-data/E...
Reposted by Riccardo Cappuzzo

Heads Up, #Python Developers!
There is an active phishing attack targeting PyPI users.
• Threat: Emails from noreply@pypj.org (with a 'j') link to a fake login page.
• Action: Do not click any links. If you already did, change your PyPI password ASAP.
• Note: PyPI itself has not been breached.
There is an active phishing attack targeting PyPI users.
• Threat: Emails from noreply@pypj.org (with a 'j') link to a fake login page.
• Action: Do not click any links. If you already did, change your PyPI password ASAP.
• Note: PyPI itself has not been breached.
July 28, 2025 at 2:35 PM
Heads Up, #Python Developers!
There is an active phishing attack targeting PyPI users.
• Threat: Emails from noreply@pypj.org (with a 'j') link to a fake login page.
• Action: Do not click any links. If you already did, change your PyPI password ASAP.
• Note: PyPI itself has not been breached.
There is an active phishing attack targeting PyPI users.
• Threat: Emails from noreply@pypj.org (with a 'j') link to a fake login page.
• Action: Do not click any links. If you already did, change your PyPI password ASAP.
• Note: PyPI itself has not been breached.
Huge release, and the first one where I felt like I actually contributed a lot to the final result.
I really think DataOps are a game changer, and I can't wait to see what people come up with with them.
I also ended up rewriting most of the user guide, hopefully improving it along on the way 😂
I really think DataOps are a game changer, and I can't wait to see what people come up with with them.
I also ended up rewriting most of the user guide, hopefully improving it along on the way 😂
⚡ Release 0.6.0 is now out! ⚡
🚀 Major update! Skrub DataOps, various improvements for the TableReport, new tools for applying transformers to the columns, and a new robust transformer for numerical features are only some of the features included in this release.
🚀 Major update! Skrub DataOps, various improvements for the TableReport, new tools for applying transformers to the columns, and a new robust transformer for numerical features are only some of the features included in this release.

July 24, 2025 at 4:05 PM
Huge release, and the first one where I felt like I actually contributed a lot to the final result.
I really think DataOps are a game changer, and I can't wait to see what people come up with with them.
I also ended up rewriting most of the user guide, hopefully improving it along on the way 😂
I really think DataOps are a game changer, and I can't wait to see what people come up with with them.
I also ended up rewriting most of the user guide, hopefully improving it along on the way 😂
I got 16/26 on the fstrings.wtf quiz. Can you do better? fstrings.wtf

fstrings.wtf - Python F-String Quiz
Test your knowledge of Python's f-string formatting with this interactive quiz. How well do you know Python's string formatting quirks?
fstrings.wtf
July 19, 2025 at 9:55 PM
I got 16/26 on the fstrings.wtf quiz. Can you do better? fstrings.wtf
Reposted by Riccardo Cappuzzo

David R. Hagen just solved a small mystery that I mentioned 13 years ago in the mouseover text of a comic drhagen.com/blog/the-mis...
The Missing 11th of the Month - David R Hagen
Personal website of David R Hagen, scientific software engineer
drhagen.com
June 19, 2025 at 11:40 AM
David R. Hagen just solved a small mystery that I mentioned 13 years ago in the mouseover text of a comic drhagen.com/blog/the-mis...
Really cool graffiti I spotted while walking around in the town where I live




June 13, 2025 at 9:10 PM
Really cool graffiti I spotted while walking around in the town where I live

Out of all the features in the expressions, this may be my personal favorite. I always end up adding too many configurations just because the syntax is so convenient.
👀 This week's post will be another sneak peek into skrub expressions, an upcoming feature that will ease the preparation and execution of machine learning pipelines on dataframes.
This time we will focus on how expressions can simplify the construction of complex hyperparameter grids.
This time we will focus on how expressions can simplify the construction of complex hyperparameter grids.
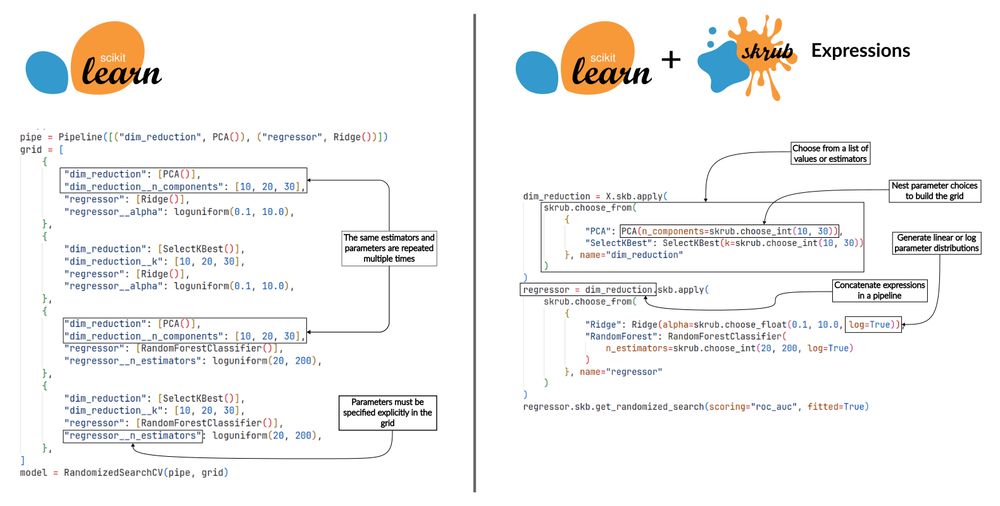
June 4, 2025 at 1:00 PM
Out of all the features in the expressions, this may be my personal favorite. I always end up adding too many configurations just because the syntax is so convenient.
Reposted by Riccardo Cappuzzo
📝 The skrub TextEncoder brings the power of HuggingFace language models to embed text features in tabular machine learning, for all those use cases that involve text-based columns.
May 28, 2025 at 8:43 AM
📝 The skrub TextEncoder brings the power of HuggingFace language models to embed text features in tabular machine learning, for all those use cases that involve text-based columns.
Reposted by Riccardo Cappuzzo
The Skrub Cleaner is a lightweight transformer that performs consistency checks on a dataframe:
🔍 It gives a uniform representation of null values, converting those represented as strings (such as "N/A")
🗑️ It drops columns that contain too many null values (according to a user-defined threshold)
🔍 It gives a uniform representation of null values, converting those represented as strings (such as "N/A")
🗑️ It drops columns that contain too many null values (according to a user-defined threshold)
May 21, 2025 at 8:53 AM
The Skrub Cleaner is a lightweight transformer that performs consistency checks on a dataframe:
🔍 It gives a uniform representation of null values, converting those represented as strings (such as "N/A")
🗑️ It drops columns that contain too many null values (according to a user-defined threshold)
🔍 It gives a uniform representation of null values, converting those represented as strings (such as "N/A")
🗑️ It drops columns that contain too many null values (according to a user-defined threshold)
Now that the paper is out, I can finally share the totally-not-confusing script/plot/table map I made to track which scripts prepare which figures and tables and from what data.
If it wasn't clear, don't do this. If you *really* have to, I used the @obsidian.md canvas for this.
If it wasn't clear, don't do this. If you *really* have to, I used the @obsidian.md canvas for this.

May 20, 2025 at 8:26 AM
Now that the paper is out, I can finally share the totally-not-confusing script/plot/table map I made to track which scripts prepare which figures and tables and from what data.
If it wasn't clear, don't do this. If you *really* have to, I used the @obsidian.md canvas for this.
If it wasn't clear, don't do this. If you *really* have to, I used the @obsidian.md canvas for this.
Work done with @gaelvaroquaux.bsky.social and @papotti.bsky.social
🌟 New paper alert! 🌟
Our paper, "Retrieve, Merge, Predict: Augmenting Tables with Data Lakes", has been published in TMLR!
In this work, we created YADL (a semi-synthetic data lake), and we benchmarked methods for augmenting user-provided tables given information found in data lakes.
1/
Our paper, "Retrieve, Merge, Predict: Augmenting Tables with Data Lakes", has been published in TMLR!
In this work, we created YADL (a semi-synthetic data lake), and we benchmarked methods for augmenting user-provided tables given information found in data lakes.
1/

May 19, 2025 at 4:03 PM
Work done with @gaelvaroquaux.bsky.social and @papotti.bsky.social
A bit of a mess up with this figure! This is what it's supposed to look like 🙈

May 19, 2025 at 4:01 PM
A bit of a mess up with this figure! This is what it's supposed to look like 🙈
🌟 New paper alert! 🌟
Our paper, "Retrieve, Merge, Predict: Augmenting Tables with Data Lakes", has been published in TMLR!
In this work, we created YADL (a semi-synthetic data lake), and we benchmarked methods for augmenting user-provided tables given information found in data lakes.
1/
Our paper, "Retrieve, Merge, Predict: Augmenting Tables with Data Lakes", has been published in TMLR!
In this work, we created YADL (a semi-synthetic data lake), and we benchmarked methods for augmenting user-provided tables given information found in data lakes.
1/
May 19, 2025 at 3:43 PM
🌟 New paper alert! 🌟
Our paper, "Retrieve, Merge, Predict: Augmenting Tables with Data Lakes", has been published in TMLR!
In this work, we created YADL (a semi-synthetic data lake), and we benchmarked methods for augmenting user-provided tables given information found in data lakes.
1/
Our paper, "Retrieve, Merge, Predict: Augmenting Tables with Data Lakes", has been published in TMLR!
In this work, we created YADL (a semi-synthetic data lake), and we benchmarked methods for augmenting user-provided tables given information found in data lakes.
1/