



neurosock
@neurosock.bsky.social
#BrainChips monthly recap. I make #neuro papers easy to understand. To make #Neuralink possible. Neuro PhD. AI🤖ML👾Data Sci 📊 Monkeys🐵Future🚀Cyberpunk⚡🦾🌌
DA is an adaptive signal that switches its function in real-time.
Upon reward delivery, it stops predicting force and starts predicting the *rate of licking* (Fig 9h, 9j).
Upon reward delivery, it stops predicting force and starts predicting the *rate of licking* (Fig 9h, 9j).

October 30, 2025 at 11:36 AM
DA is an adaptive signal that switches its function in real-time.
Upon reward delivery, it stops predicting force and starts predicting the *rate of licking* (Fig 9h, 9j).
Upon reward delivery, it stops predicting force and starts predicting the *rate of licking* (Fig 9h, 9j).
Optogenetically stimulating DA neurons in place of reward was *not sufficient* for learning.
Inhibiting DA neurons during the task *did not impair* learning (Fig 10b, 10i).
Inhibiting DA neurons during the task *did not impair* learning (Fig 10b, 10i).

October 30, 2025 at 11:36 AM
Optogenetically stimulating DA neurons in place of reward was *not sufficient* for learning.
Inhibiting DA neurons during the task *did not impair* learning (Fig 10b, 10i).
Inhibiting DA neurons during the task *did not impair* learning (Fig 10b, 10i).
Changes in DA firing due to reward magnitude, probability, and omission were all explained by parallel changes in the *force* the mice exerted (Figs 4, 5).

October 30, 2025 at 11:36 AM
Changes in DA firing due to reward magnitude, probability, and omission were all explained by parallel changes in the *force* the mice exerted (Figs 4, 5).
This force-tuning was independent of reward, appearing during spontaneous movements.
It even held true during an aversive air puff, proving it's not about "reward" (Fig 3e, 3h).
It even held true during an aversive air puff, proving it's not about "reward" (Fig 3e, 3h).

October 30, 2025 at 11:36 AM
This force-tuning was independent of reward, appearing during spontaneous movements.
It even held true during an aversive air puff, proving it's not about "reward" (Fig 3e, 3h).
It even held true during an aversive air puff, proving it's not about "reward" (Fig 3e, 3h).
This is how we learned that from their results:
They identified two distinct DA neuron types: "Forward" and "Backward" populations.
These cells fire to drive movement in a specific direction (Fig 1e, 1h, 1k).
They identified two distinct DA neuron types: "Forward" and "Backward" populations.
These cells fire to drive movement in a specific direction (Fig 1e, 1h, 1k).

October 30, 2025 at 11:36 AM
This is how we learned that from their results:
They identified two distinct DA neuron types: "Forward" and "Backward" populations.
These cells fire to drive movement in a specific direction (Fig 1e, 1h, 1k).
They identified two distinct DA neuron types: "Forward" and "Backward" populations.
These cells fire to drive movement in a specific direction (Fig 1e, 1h, 1k).
How does reward probability change the DA signal?
RPE view: DA activity scales with reward probability, encoding the *strength* of the prediction.
New view: Probability changes the animal's *effort*, and the DA signal simply tracks that performance.
RPE view: DA activity scales with reward probability, encoding the *strength* of the prediction.
New view: Probability changes the animal's *effort*, and the DA signal simply tracks that performance.

October 30, 2025 at 11:36 AM
How does reward probability change the DA signal?
RPE view: DA activity scales with reward probability, encoding the *strength* of the prediction.
New view: Probability changes the animal's *effort*, and the DA signal simply tracks that performance.
RPE view: DA activity scales with reward probability, encoding the *strength* of the prediction.
New view: Probability changes the animal's *effort*, and the DA signal simply tracks that performance.
Why does a bigger reward cause a bigger DA spike?
RPE view: A larger reward causes a larger DA spike because it's a bigger "positive error."
New view: A larger reward makes the mouse push *harder*, and the DA spike just tracks that *vigor*.
RPE view: A larger reward causes a larger DA spike because it's a bigger "positive error."
New view: A larger reward makes the mouse push *harder*, and the DA spike just tracks that *vigor*.

October 30, 2025 at 11:36 AM
Why does a bigger reward cause a bigger DA spike?
RPE view: A larger reward causes a larger DA spike because it's a bigger "positive error."
New view: A larger reward makes the mouse push *harder*, and the DA spike just tracks that *vigor*.
RPE view: A larger reward causes a larger DA spike because it's a bigger "positive error."
New view: A larger reward makes the mouse push *harder*, and the DA spike just tracks that *vigor*.
Why does DA firing "dip" when a reward is omitted?
RPE view: The famous "dip" in DA when a reward is omitted is a negative prediction error.
New view: The dip simply reflects the animal *abruptly stopping* its forward movement.
RPE view: The famous "dip" in DA when a reward is omitted is a negative prediction error.
New view: The dip simply reflects the animal *abruptly stopping* its forward movement.

October 30, 2025 at 11:36 AM
Why does DA firing "dip" when a reward is omitted?
RPE view: The famous "dip" in DA when a reward is omitted is a negative prediction error.
New view: The dip simply reflects the animal *abruptly stopping* its forward movement.
RPE view: The famous "dip" in DA when a reward is omitted is a negative prediction error.
New view: The dip simply reflects the animal *abruptly stopping* its forward movement.
In RPE, the DA signal shifts from reward to cue 🔔 over time.
Why does the DA signal "move" to the cue?
RPE view: This helps an animal learn what things are important.
New view: the signal shifts because the animal's *action* (pushing forward) shifts to the cue.
Why does the DA signal "move" to the cue?
RPE view: This helps an animal learn what things are important.
New view: the signal shifts because the animal's *action* (pushing forward) shifts to the cue.

October 30, 2025 at 11:36 AM
In RPE, the DA signal shifts from reward to cue 🔔 over time.
Why does the DA signal "move" to the cue?
RPE view: This helps an animal learn what things are important.
New view: the signal shifts because the animal's *action* (pushing forward) shifts to the cue.
Why does the DA signal "move" to the cue?
RPE view: This helps an animal learn what things are important.
New view: the signal shifts because the animal's *action* (pushing forward) shifts to the cue.
Let's unpack this:
The classical RPE model says DA neurons encode the *difference* between expected and actual rewards.
A surprise spikes DA activity, while disappointment causes a dip.
This helps a mouse 🐭 learn what to pay attention to.
The classical RPE model says DA neurons encode the *difference* between expected and actual rewards.
A surprise spikes DA activity, while disappointment causes a dip.
This helps a mouse 🐭 learn what to pay attention to.

October 30, 2025 at 11:36 AM
Let's unpack this:
The classical RPE model says DA neurons encode the *difference* between expected and actual rewards.
A surprise spikes DA activity, while disappointment causes a dip.
This helps a mouse 🐭 learn what to pay attention to.
The classical RPE model says DA neurons encode the *difference* between expected and actual rewards.
A surprise spikes DA activity, while disappointment causes a dip.
This helps a mouse 🐭 learn what to pay attention to.
Dopamine ≠ reward but turns out, also not the learning molecule we thought.
If DA RPE is the emperor, this work SCREAMS it was running naked all the time.
This paper got quite some attention recently. Let's simplify it a bit.
A🧵with my toy model and notes:
#neuroskyence #compneuro #NeuroAI
If DA RPE is the emperor, this work SCREAMS it was running naked all the time.
This paper got quite some attention recently. Let's simplify it a bit.
A🧵with my toy model and notes:
#neuroskyence #compneuro #NeuroAI

October 30, 2025 at 11:36 AM
Dopamine ≠ reward but turns out, also not the learning molecule we thought.
If DA RPE is the emperor, this work SCREAMS it was running naked all the time.
This paper got quite some attention recently. Let's simplify it a bit.
A🧵with my toy model and notes:
#neuroskyence #compneuro #NeuroAI
If DA RPE is the emperor, this work SCREAMS it was running naked all the time.
This paper got quite some attention recently. Let's simplify it a bit.
A🧵with my toy model and notes:
#neuroskyence #compneuro #NeuroAI
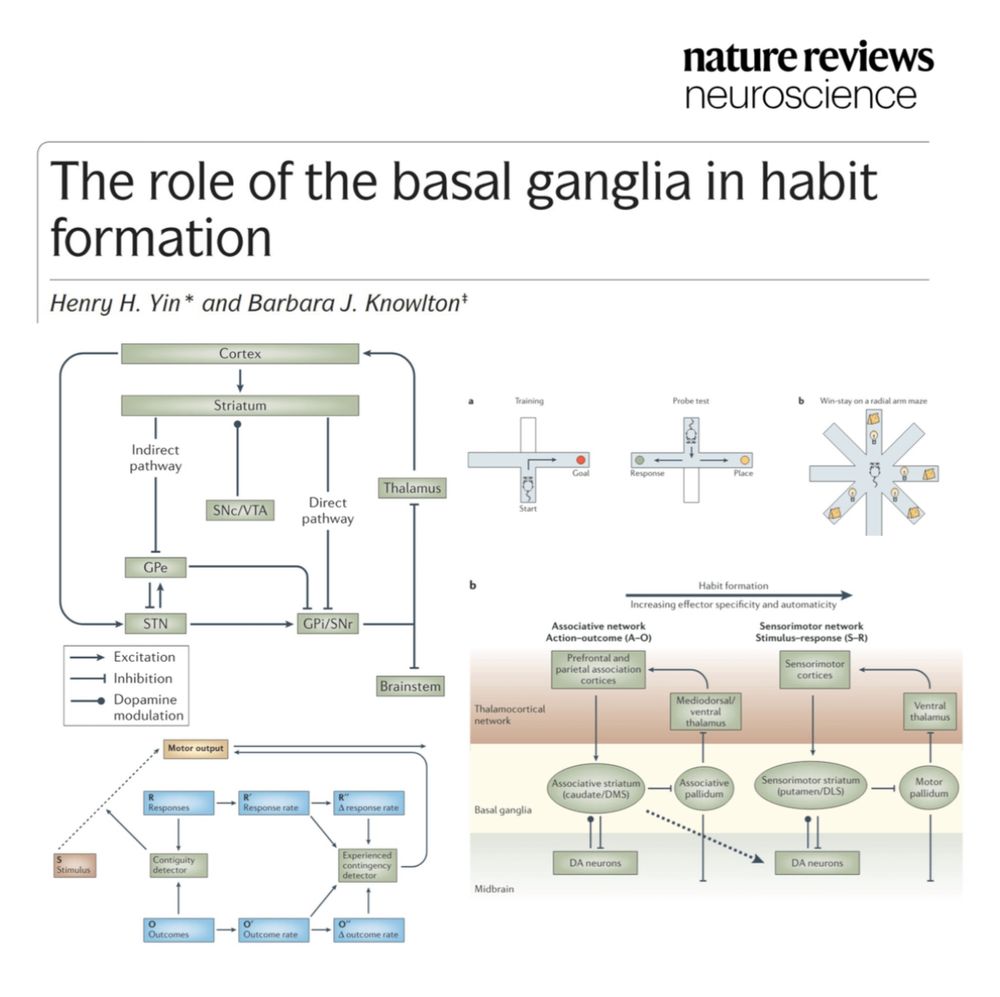
New habits move from the Prefrontal Cortex (conscious effort) to the Basal Ganglia (habit loop). A trick is to automate the first 30 seconds of a habit, minimizing the PFC's required 'energy' for initiation until the Basal Ganglia takes over. #LifeHacks #SelfImprovement #Brain
October 25, 2025 at 3:32 PM
New habits move from the Prefrontal Cortex (conscious effort) to the Basal Ganglia (habit loop). A trick is to automate the first 30 seconds of a habit, minimizing the PFC's required 'energy' for initiation until the Basal Ganglia takes over. #LifeHacks #SelfImprovement #Brain
This work unifies planning with sequence working memory.
The same neural architecture used to *remember* a sequence can be used to *infer* a plan (Fig 2B).
The same neural architecture used to *remember* a sequence can be used to *infer* a plan (Fig 2B).

October 22, 2025 at 9:16 PM
This work unifies planning with sequence working memory.
The same neural architecture used to *remember* a sequence can be used to *infer* a plan (Fig 2B).
The same neural architecture used to *remember* a sequence can be used to *infer* a plan (Fig 2B).
For new mazes, the RNNs adapted by learning *transitions* instead of fixed locations (Fig 6C).
Sensory input about a wall specifically inhibited the neural representation for that impossible transition (Fig 6H).
Sensory input about a wall specifically inhibited the neural representation for that impossible transition (Fig 6H).

October 22, 2025 at 9:16 PM
For new mazes, the RNNs adapted by learning *transitions* instead of fixed locations (Fig 6C).
Sensory input about a wall specifically inhibited the neural representation for that impossible transition (Fig 6H).
Sensory input about a wall specifically inhibited the neural representation for that impossible transition (Fig 6H).
The trained RNNs explicitly learned the maze rules—the 'world model'—in their synaptic weights (Fig 5B).
The connections between subspaces representing future steps perfectly matched the maze's adjacency matrix (Fig 5E).
The connections between subspaces representing future steps perfectly matched the maze's adjacency matrix (Fig 5E).

October 22, 2025 at 9:16 PM
The trained RNNs explicitly learned the maze rules—the 'world model'—in their synaptic weights (Fig 5B).
The connections between subspaces representing future steps perfectly matched the maze's adjacency matrix (Fig 5E).
The connections between subspaces representing future steps perfectly matched the maze's adjacency matrix (Fig 5E).
Recurrent Neural Networks (RNNs) trained to solve these problems learned the STA solution on their own (Fig 4C).
They developed the same "conveyor belt" dynamics, suggesting it's an efficient solution (Fig 4E).
They developed the same "conveyor belt" dynamics, suggesting it's an efficient solution (Fig 4E).

October 22, 2025 at 9:16 PM
Recurrent Neural Networks (RNNs) trained to solve these problems learned the STA solution on their own (Fig 4C).
They developed the same "conveyor belt" dynamics, suggesting it's an efficient solution (Fig 4E).
They developed the same "conveyor belt" dynamics, suggesting it's an efficient solution (Fig 4E).
This is how we learned that from their results:
The Spacetime Attractor (STA) model successfully solves complex, dynamic tasks that other models fail (Fig 3D-E).
It excels when rewards change *within* a trial, like intercepting a moving target.
The Spacetime Attractor (STA) model successfully solves complex, dynamic tasks that other models fail (Fig 3D-E).
It excels when rewards change *within* a trial, like intercepting a moving target.

October 22, 2025 at 9:16 PM
This is how we learned that from their results:
The Spacetime Attractor (STA) model successfully solves complex, dynamic tasks that other models fail (Fig 3D-E).
It excels when rewards change *within* a trial, like intercepting a moving target.
The Spacetime Attractor (STA) model successfully solves complex, dynamic tasks that other models fail (Fig 3D-E).
It excels when rewards change *within* a trial, like intercepting a moving target.
This completes a beautiful picture of how learning/adaptation could happen in the 🧠:
Striatum: temporal-difference learning. Slow, habits🐢
Hippocampus: successor-representation learning. OK fast🐇, memories.
PFC: space-time attractor. Very fast🚀, reconfigures brain.
Striatum: temporal-difference learning. Slow, habits🐢
Hippocampus: successor-representation learning. OK fast🐇, memories.
PFC: space-time attractor. Very fast🚀, reconfigures brain.

October 22, 2025 at 9:16 PM
This completes a beautiful picture of how learning/adaptation could happen in the 🧠:
Striatum: temporal-difference learning. Slow, habits🐢
Hippocampus: successor-representation learning. OK fast🐇, memories.
PFC: space-time attractor. Very fast🚀, reconfigures brain.
Striatum: temporal-difference learning. Slow, habits🐢
Hippocampus: successor-representation learning. OK fast🐇, memories.
PFC: space-time attractor. Very fast🚀, reconfigures brain.
But how does this adapt to new mazes?
Training nets to challenging environments, they found nets learn scaffolds of all possible actions instead of locations.
When it sees a new wall, sensory input just "blocks" or inhibits that specific action, making the plan flexible.
Training nets to challenging environments, they found nets learn scaffolds of all possible actions instead of locations.
When it sees a new wall, sensory input just "blocks" or inhibits that specific action, making the plan flexible.

October 22, 2025 at 9:16 PM
But how does this adapt to new mazes?
Training nets to challenging environments, they found nets learn scaffolds of all possible actions instead of locations.
When it sees a new wall, sensory input just "blocks" or inhibits that specific action, making the plan flexible.
Training nets to challenging environments, they found nets learn scaffolds of all possible actions instead of locations.
When it sees a new wall, sensory input just "blocks" or inhibits that specific action, making the plan flexible.
As the agent takes the first action, the entire plan representation shifts forward in time.
What was in the "NEXT" 🟦 subspace moves to the "NOW" 🟩 subspace, readying the next action without re-planning.
Conveyor belt dynamics, they call it.
What was in the "NEXT" 🟦 subspace moves to the "NOW" 🟩 subspace, readying the next action without re-planning.
Conveyor belt dynamics, they call it.

October 22, 2025 at 9:16 PM
As the agent takes the first action, the entire plan representation shifts forward in time.
What was in the "NEXT" 🟦 subspace moves to the "NOW" 🟩 subspace, readying the next action without re-planning.
Conveyor belt dynamics, they call it.
What was in the "NEXT" 🟦 subspace moves to the "NOW" 🟩 subspace, readying the next action without re-planning.
Conveyor belt dynamics, they call it.
Planning happens when inputs, like the 'start' and 'goal', are applied to this network.
The circuit activity then rapidly "relaxes" into the most stable pattern, which *is* the optimal path.
In each subspace, only the units representing the locations in the plan are active.
The circuit activity then rapidly "relaxes" into the most stable pattern, which *is* the optimal path.
In each subspace, only the units representing the locations in the plan are active.

October 22, 2025 at 9:16 PM
Planning happens when inputs, like the 'start' and 'goal', are applied to this network.
The circuit activity then rapidly "relaxes" into the most stable pattern, which *is* the optimal path.
In each subspace, only the units representing the locations in the plan are active.
The circuit activity then rapidly "relaxes" into the most stable pattern, which *is* the optimal path.
In each subspace, only the units representing the locations in the plan are active.
These subspaces are connected based on the environment's rules, like a 'world model' etched into the wiring.
Synapses from "NOW" 🟩 to "NEXT" 🟦 only exists if the agent can *actually* move between those two locations.
Possible move: excitatory
Not possible move: inhibitory
Synapses from "NOW" 🟩 to "NEXT" 🟦 only exists if the agent can *actually* move between those two locations.
Possible move: excitatory
Not possible move: inhibitory

October 22, 2025 at 9:16 PM
These subspaces are connected based on the environment's rules, like a 'world model' etched into the wiring.
Synapses from "NOW" 🟩 to "NEXT" 🟦 only exists if the agent can *actually* move between those two locations.
Possible move: excitatory
Not possible move: inhibitory
Synapses from "NOW" 🟩 to "NEXT" 🟦 only exists if the agent can *actually* move between those two locations.
Possible move: excitatory
Not possible move: inhibitory
Let's unpack this:
The model assumes the PFC is split into different "subspaces," each representing a different point in the future.
One group of neurons maps "NOW (0)," 🟩 another maps "NEXT (1)," 🟦 and another maps "LATER (2),"🟪 all active simultaneously.
The model assumes the PFC is split into different "subspaces," each representing a different point in the future.
One group of neurons maps "NOW (0)," 🟩 another maps "NEXT (1)," 🟦 and another maps "LATER (2),"🟪 all active simultaneously.

October 22, 2025 at 9:16 PM
Let's unpack this:
The model assumes the PFC is split into different "subspaces," each representing a different point in the future.
One group of neurons maps "NOW (0)," 🟩 another maps "NEXT (1)," 🟦 and another maps "LATER (2),"🟪 all active simultaneously.
The model assumes the PFC is split into different "subspaces," each representing a different point in the future.
One group of neurons maps "NOW (0)," 🟩 another maps "NEXT (1)," 🟦 and another maps "LATER (2),"🟪 all active simultaneously.
To plan the future, the PFC represents a step-by-step map of actions, and at every step, this plan moves to the past like a conveyor belt.
This proposes a simple subspace architecture for planning.
A toy environment can clarify it.
A🧵with my toy model and notes:
#neuroskyence #compneuro #NeuroAI
This proposes a simple subspace architecture for planning.
A toy environment can clarify it.
A🧵with my toy model and notes:
#neuroskyence #compneuro #NeuroAI

October 22, 2025 at 9:16 PM
To plan the future, the PFC represents a step-by-step map of actions, and at every step, this plan moves to the past like a conveyor belt.
This proposes a simple subspace architecture for planning.
A toy environment can clarify it.
A🧵with my toy model and notes:
#neuroskyence #compneuro #NeuroAI
This proposes a simple subspace architecture for planning.
A toy environment can clarify it.
A🧵with my toy model and notes:
#neuroskyence #compneuro #NeuroAI
To stop unwanted thoughts, the PFC sends a control signal to the hippocampus (brain's memory retrieval center). This activates local inhibitory interneurons (GABA), which then suppresses retrieval. Difficulties in this pathway may underlie #PTSD, #OCD, anxiety, and #depression.

October 18, 2025 at 9:49 AM
To stop unwanted thoughts, the PFC sends a control signal to the hippocampus (brain's memory retrieval center). This activates local inhibitory interneurons (GABA), which then suppresses retrieval. Difficulties in this pathway may underlie #PTSD, #OCD, anxiety, and #depression.