




Arvind Nagaraj
@narvind.bsky.social
Deep Learning | ML research |
Ex.Robotics at Invento | 🔗 https://narvind2003.github.io
Here to strictly talk about ML, NNs and related ideas. Casual stuff on x.com/nagaraj_arvind
Ex.Robotics at Invento | 🔗 https://narvind2003.github.io
Here to strictly talk about ML, NNs and related ideas. Casual stuff on x.com/nagaraj_arvind
For years, I died a little inside every time I taught the Transformer model, grudgingly accepting that the elegant loop of the RNN was dead.

August 7, 2025 at 8:50 AM
For years, I died a little inside every time I taught the Transformer model, grudgingly accepting that the elegant loop of the RNN was dead.
🔥🔥
MCTS rollout pruning, python interpreter verifier and iterative self improvement of intermediate steps during each round of training.
Brilliant stuff this💪
rStar-Math is the kind of paper I wish to see more of!
MCTS rollout pruning, python interpreter verifier and iterative self improvement of intermediate steps during each round of training.
Brilliant stuff this💪
rStar-Math is the kind of paper I wish to see more of!

rStar-Math takes qwen2.5 7b & 1.5b as well as qhi3 3.8b and fine tunes them for math
they’re able to exceed o1-preview on math benchmarks (with the 7B)
the magic sauce seems to be in co-evolving the SLM (the main LLM) and the PPM (Process Preference Model, the verifier)
arxiv.org/abs/2501.04519
they’re able to exceed o1-preview on math benchmarks (with the 7B)
the magic sauce seems to be in co-evolving the SLM (the main LLM) and the PPM (Process Preference Model, the verifier)
arxiv.org/abs/2501.04519

rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
We present rStar-Math to demonstrate that small language models (SLMs) can rival or even surpass the math reasoning capability of OpenAI o1, without distillation from superior models. rStar-Math achie...
arxiv.org
January 9, 2025 at 11:45 PM
🔥🔥
MCTS rollout pruning, python interpreter verifier and iterative self improvement of intermediate steps during each round of training.
Brilliant stuff this💪
rStar-Math is the kind of paper I wish to see more of!
MCTS rollout pruning, python interpreter verifier and iterative self improvement of intermediate steps during each round of training.
Brilliant stuff this💪
rStar-Math is the kind of paper I wish to see more of!
Reposted by Arvind Nagaraj

(1/7) For a while we've been working on an ambitious problem: The National Archive of Mexico #AGN holds 58 linear km of documents. Only a drop of this ‘ocean’ has been studied due to many challenges. But great news: we are now unlocking this information! A thread 🧵 (1/8) #HTR #AI #CulturalHeritage


December 17, 2024 at 2:15 PM
(1/7) For a while we've been working on an ambitious problem: The National Archive of Mexico #AGN holds 58 linear km of documents. Only a drop of this ‘ocean’ has been studied due to many challenges. But great news: we are now unlocking this information! A thread 🧵 (1/8) #HTR #AI #CulturalHeritage
Reposted by Arvind Nagaraj

Computer Vision: Fact & Fiction is now available on YouTube 🙌🏼 I made a playlist for it with the seven chapters. Enjoy this time capsule from two decades ago!
December 19, 2024 at 4:50 PM
Computer Vision: Fact & Fiction is now available on YouTube 🙌🏼 I made a playlist for it with the seven chapters. Enjoy this time capsule from two decades ago!
I like how the new gemini 2.0 thinking model insists like a child...lol

December 19, 2024 at 6:38 PM
I like how the new gemini 2.0 thinking model insists like a child...lol
RoPE has been the one 💯 genuine upgrade to the vanilla Vaswani transformer.
This beautiful blogpost by Chris Fleetwood explains the significance and how rotations of Q & K preserves meaning(magnitude) while encodes relative positions(angle shift) 🔥🔥
This beautiful blogpost by Chris Fleetwood explains the significance and how rotations of Q & K preserves meaning(magnitude) while encodes relative positions(angle shift) 🔥🔥
December 3, 2024 at 6:32 AM
RoPE has been the one 💯 genuine upgrade to the vanilla Vaswani transformer.
This beautiful blogpost by Chris Fleetwood explains the significance and how rotations of Q & K preserves meaning(magnitude) while encodes relative positions(angle shift) 🔥🔥
This beautiful blogpost by Chris Fleetwood explains the significance and how rotations of Q & K preserves meaning(magnitude) while encodes relative positions(angle shift) 🔥🔥
Why does ChatGPT refuse to say "David Mayer" ?? 🤔
I have tried a bunch of ways and it refuses to!! 😭
I have tried a bunch of ways and it refuses to!! 😭

December 1, 2024 at 6:38 AM
Why does ChatGPT refuse to say "David Mayer" ?? 🤔
I have tried a bunch of ways and it refuses to!! 😭
I have tried a bunch of ways and it refuses to!! 😭
Reposted by Arvind Nagaraj

🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
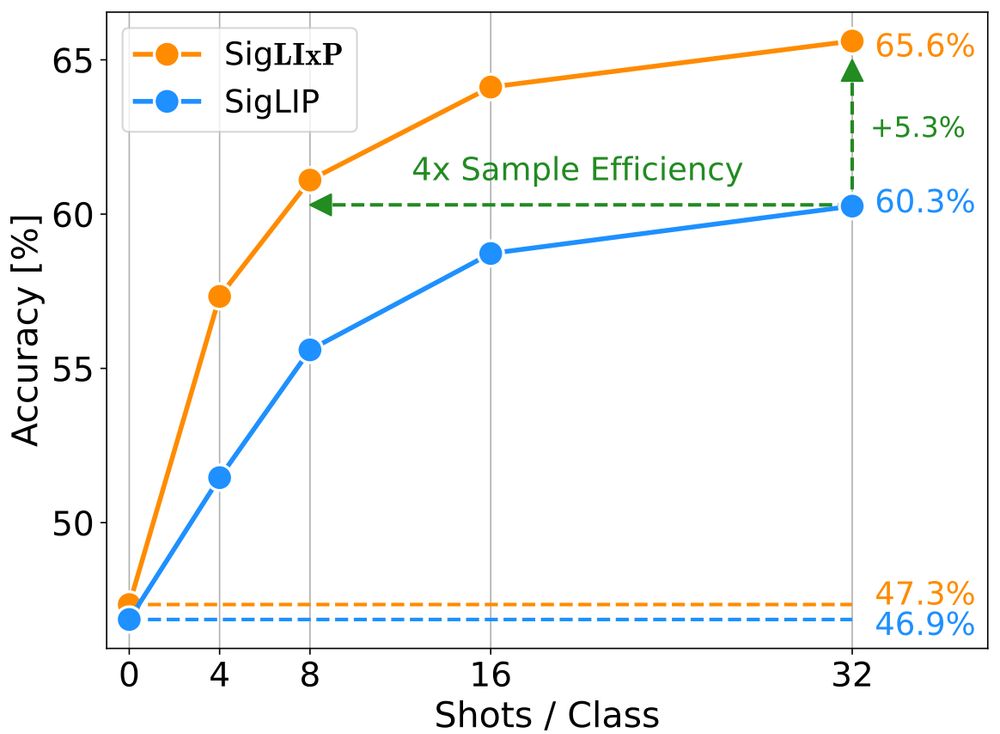
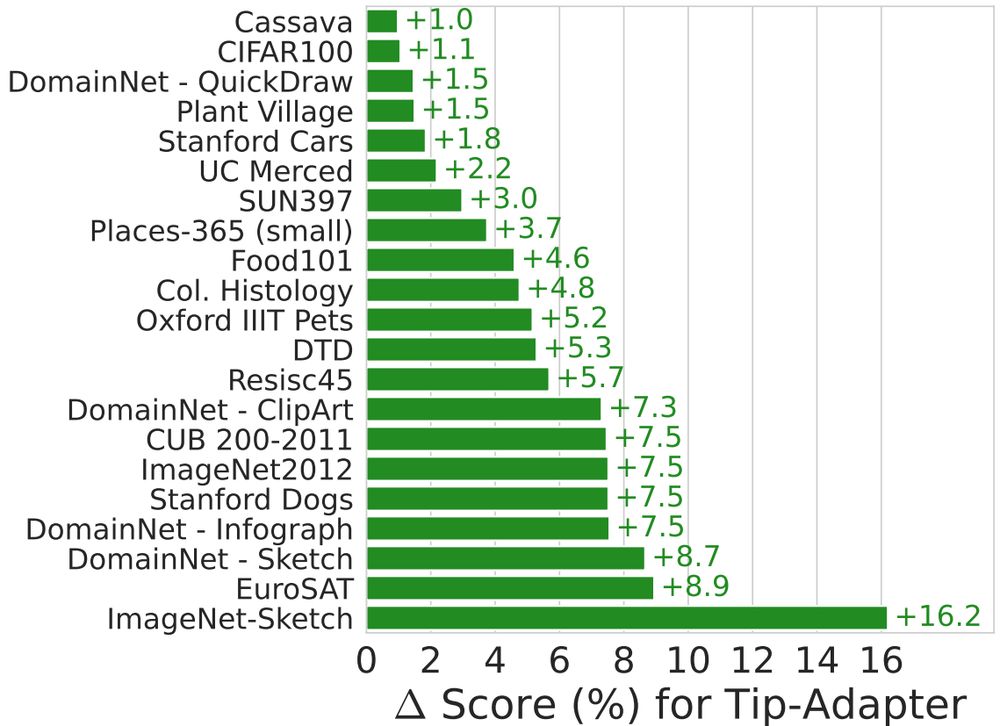

November 28, 2024 at 2:33 PM
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Reposted by Arvind Nagaraj

SIGGRAPH'25 (form): 48 days.
RSS'25 (abs): 49 days.
SIGGRAPH'25 (paper-md5): 55 days.
RSS'25 (paper): 56 days.
ICML'25: 62 days.
RLC'25 (abs): 77 days.
RLC'25 (paper): 84 days.
ICCV'25: 97 days.
RSS'25 (abs): 49 days.
SIGGRAPH'25 (paper-md5): 55 days.
RSS'25 (paper): 56 days.
ICML'25: 62 days.
RLC'25 (abs): 77 days.
RLC'25 (paper): 84 days.
ICCV'25: 97 days.
November 29, 2024 at 10:00 AM
SIGGRAPH'25 (form): 48 days.
RSS'25 (abs): 49 days.
SIGGRAPH'25 (paper-md5): 55 days.
RSS'25 (paper): 56 days.
ICML'25: 62 days.
RLC'25 (abs): 77 days.
RLC'25 (paper): 84 days.
ICCV'25: 97 days.
RSS'25 (abs): 49 days.
SIGGRAPH'25 (paper-md5): 55 days.
RSS'25 (paper): 56 days.
ICML'25: 62 days.
RLC'25 (abs): 77 days.
RLC'25 (paper): 84 days.
ICCV'25: 97 days.
We should give this place a serious try...
It may work 🙏
It may work 🙏
November 29, 2024 at 10:07 AM
We should give this place a serious try...
It may work 🙏
It may work 🙏
So many good X tweets on sparse autoencoders that are not here on 🦋
Trying to find those people and follow them here.
Trying to find those people and follow them here.
November 29, 2024 at 5:25 AM
So many good X tweets on sparse autoencoders that are not here on 🦋
Trying to find those people and follow them here.
Trying to find those people and follow them here.
Look there is chaos everywhere.
More bitterness.
"Us versus Them" factions finger pointing, name calling and blame shifting more than ever before.
Still, I am thankful for all those I get to interact with, learn from and share my ideas and happiness with.
I'm thankful for you all🙏
More bitterness.
"Us versus Them" factions finger pointing, name calling and blame shifting more than ever before.
Still, I am thankful for all those I get to interact with, learn from and share my ideas and happiness with.
I'm thankful for you all🙏
November 28, 2024 at 5:56 PM
Look there is chaos everywhere.
More bitterness.
"Us versus Them" factions finger pointing, name calling and blame shifting more than ever before.
Still, I am thankful for all those I get to interact with, learn from and share my ideas and happiness with.
I'm thankful for you all🙏
More bitterness.
"Us versus Them" factions finger pointing, name calling and blame shifting more than ever before.
Still, I am thankful for all those I get to interact with, learn from and share my ideas and happiness with.
I'm thankful for you all🙏
Reposted by Arvind Nagaraj

Has anyone shared huggingface.co/datasets/alp... as a torrent yet? Happy to support that effort

alpindale/two-million-bluesky-posts · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
November 28, 2024 at 10:30 AM
Has anyone shared huggingface.co/datasets/alp... as a torrent yet? Happy to support that effort
👌👌

Oops I missed one letter in my code. Corrected version:
```
from atproto import *
def f(m): print(m.header, parse_subscribe_repos_message(m))
FirehoseSubscribeReposClient().start(f)
```
```
from atproto import *
def f(m): print(m.header, parse_subscribe_repos_message(m))
FirehoseSubscribeReposClient().start(f)
```
November 28, 2024 at 12:58 PM
👌👌
I'm going to the profiles of each person who threatened the HF guy to see what earth shattering ideas they came up with. So far it's mostly junk and therefore the dataset wouldn't have been of much value anyway.
(Unless you're training 'task vectors' for junk, to improve your models.)
(Unless you're training 'task vectors' for junk, to improve your models.)
November 28, 2024 at 12:55 PM
I'm going to the profiles of each person who threatened the HF guy to see what earth shattering ideas they came up with. So far it's mostly junk and therefore the dataset wouldn't have been of much value anyway.
(Unless you're training 'task vectors' for junk, to improve your models.)
(Unless you're training 'task vectors' for junk, to improve your models.)
Mikolov...
Vinyals...
For the next 8-9 years it's going to be fairly easy to predict the Neurips test of time awards.
Kaiming He 2025 anyone??
Vinyals...
For the next 8-9 years it's going to be fairly easy to predict the Neurips test of time awards.
Kaiming He 2025 anyone??
November 28, 2024 at 3:52 AM
Mikolov...
Vinyals...
For the next 8-9 years it's going to be fairly easy to predict the Neurips test of time awards.
Kaiming He 2025 anyone??
Vinyals...
For the next 8-9 years it's going to be fairly easy to predict the Neurips test of time awards.
Kaiming He 2025 anyone??
Reposted by Arvind Nagaraj

We generate a soundtrack for a silent video, given a text prompt! For example, we can make a cat's meow sound like a lion's roar or a typewriter sound like a piano.
Paper: arxiv.org/abs/2411.17698
Webpage: ificl.github.io/MultiFoley/
Led by @czyang.bsky.social!
bsky.app/profile/czya...
Paper: arxiv.org/abs/2411.17698
Webpage: ificl.github.io/MultiFoley/
Led by @czyang.bsky.social!
bsky.app/profile/czya...
November 27, 2024 at 3:14 AM
We generate a soundtrack for a silent video, given a text prompt! For example, we can make a cat's meow sound like a lion's roar or a typewriter sound like a piano.
Paper: arxiv.org/abs/2411.17698
Webpage: ificl.github.io/MultiFoley/
Led by @czyang.bsky.social!
bsky.app/profile/czya...
Paper: arxiv.org/abs/2411.17698
Webpage: ificl.github.io/MultiFoley/
Led by @czyang.bsky.social!
bsky.app/profile/czya...
Reposted by Arvind Nagaraj

Caddy's a great choice. I love that it stretches from local poking and prodding to full production. The Caddy local file server (i.e. `caddy file-server --listen 0.0.0.0:8000 --browse`) overtook `python -m http<dot>server` for me given it looks nicer and has grid view for images :)
November 25, 2024 at 8:45 PM
Caddy's a great choice. I love that it stretches from local poking and prodding to full production. The Caddy local file server (i.e. `caddy file-server --listen 0.0.0.0:8000 --browse`) overtook `python -m http<dot>server` for me given it looks nicer and has grid view for images :)
o1 style reasoning can solve most of these. But 8 is tricky.
Deepseek's model (inner monologue thinking tokens) are super interesting to watch. But the CoT trajectories take it to 2 incorrect solutions before it runs out thinking time: It either adds an extra 8 or uses cube roots.
Can't nest like👇
Deepseek's model (inner monologue thinking tokens) are super interesting to watch. But the CoT trajectories take it to 2 incorrect solutions before it runs out thinking time: It either adds an extra 8 or uses cube roots.
Can't nest like👇

November 26, 2024 at 6:39 AM
o1 style reasoning can solve most of these. But 8 is tricky.
Deepseek's model (inner monologue thinking tokens) are super interesting to watch. But the CoT trajectories take it to 2 incorrect solutions before it runs out thinking time: It either adds an extra 8 or uses cube roots.
Can't nest like👇
Deepseek's model (inner monologue thinking tokens) are super interesting to watch. But the CoT trajectories take it to 2 incorrect solutions before it runs out thinking time: It either adds an extra 8 or uses cube roots.
Can't nest like👇
🔥🔥🔥 blogpost from @markriedl.bsky.social articulating the history of modern NLP leading up to the LM task, embedding semantics into vectors and learning the underlying representations via gradient descent, the Vaswani transformer and all the way to RLHF alignment and inference tricks like CoT.

I have converted a portion of my NLP Online Masters course to blog form. This is the progression I present that takes one from recurrent neural network to seq2seq with attention to transformer. mark-riedl.medium.com/transformers...
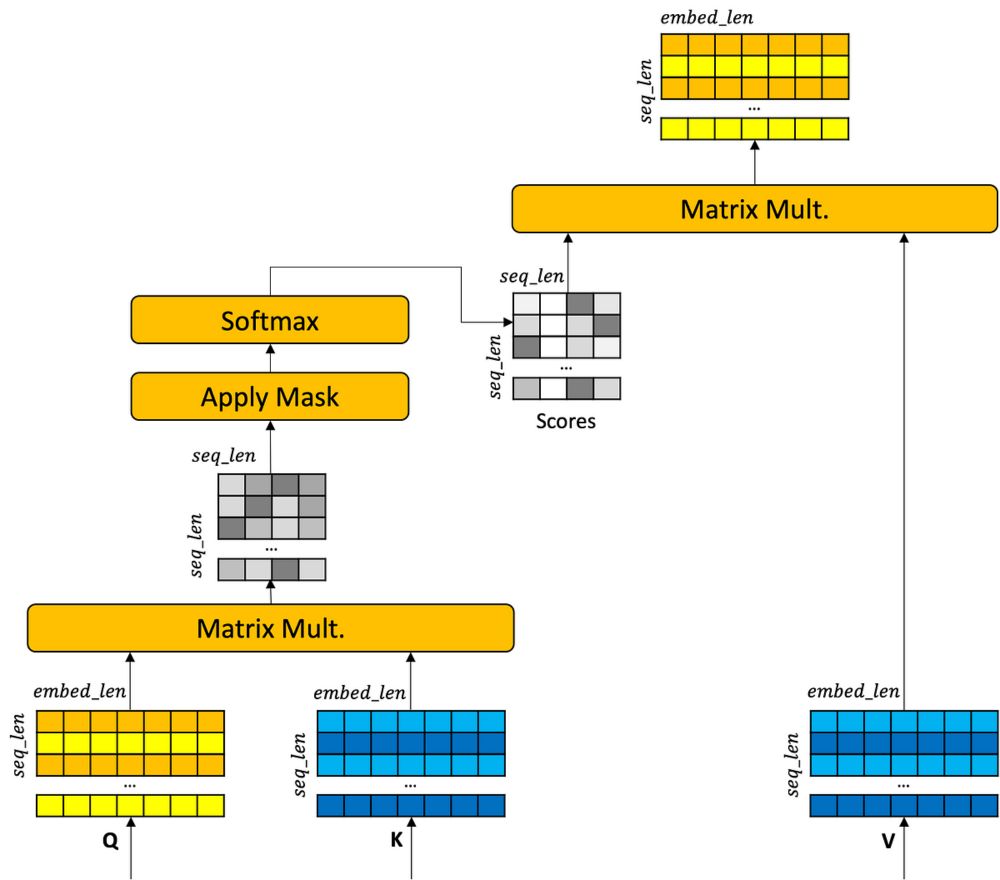
Transformers: Origins
An unofficial origin story of the transformer neural network architecture.
mark-riedl.medium.com
November 26, 2024 at 5:28 AM
🔥🔥🔥 blogpost from @markriedl.bsky.social articulating the history of modern NLP leading up to the LM task, embedding semantics into vectors and learning the underlying representations via gradient descent, the Vaswani transformer and all the way to RLHF alignment and inference tricks like CoT.
Multimodality is super 🔥 now!
The sense of smell got added to the mix as we see companies like Osmo build a digital nose and a smell printer.
IMHO, the digital nose (input) will get adopted sooner than the smell printer(output) like the other senses - vision, touch.
Perhaps audio is an exception 🤔
The sense of smell got added to the mix as we see companies like Osmo build a digital nose and a smell printer.
IMHO, the digital nose (input) will get adopted sooner than the smell printer(output) like the other senses - vision, touch.
Perhaps audio is an exception 🤔
November 26, 2024 at 4:17 AM
Multimodality is super 🔥 now!
The sense of smell got added to the mix as we see companies like Osmo build a digital nose and a smell printer.
IMHO, the digital nose (input) will get adopted sooner than the smell printer(output) like the other senses - vision, touch.
Perhaps audio is an exception 🤔
The sense of smell got added to the mix as we see companies like Osmo build a digital nose and a smell printer.
IMHO, the digital nose (input) will get adopted sooner than the smell printer(output) like the other senses - vision, touch.
Perhaps audio is an exception 🤔
@dottxtai.bsky.social is doing 👌 work with structured data.
Their new blog post describes Coalescence - using Finite state machines to generate JSON output upto 5X faster during LLM inference!🔥
Pydantic model -> JSON schema -> regex -> FSM -> Selective sampling! 👏👏
blog.dottxt.co/coalescence....
Their new blog post describes Coalescence - using Finite state machines to generate JSON output upto 5X faster during LLM inference!🔥
Pydantic model -> JSON schema -> regex -> FSM -> Selective sampling! 👏👏
blog.dottxt.co/coalescence....
Coalescence: making LLM inference 5x faster
blog.dottxt.co
November 25, 2024 at 5:47 PM
@dottxtai.bsky.social is doing 👌 work with structured data.
Their new blog post describes Coalescence - using Finite state machines to generate JSON output upto 5X faster during LLM inference!🔥
Pydantic model -> JSON schema -> regex -> FSM -> Selective sampling! 👏👏
blog.dottxt.co/coalescence....
Their new blog post describes Coalescence - using Finite state machines to generate JSON output upto 5X faster during LLM inference!🔥
Pydantic model -> JSON schema -> regex -> FSM -> Selective sampling! 👏👏
blog.dottxt.co/coalescence....
Thanks Jeremy, for sharing the instructions!
I have moved to a custom domain as well 😊
I have moved to a custom domain as well 😊
I've moved to a custom domain, so I'm now @howard.fm. All links to my previous bsky id (jph) should have auto-updated. I created a new "jph" id to avoid anyone taking over external links to my account.
Directions here for anyone interested in doing the same:
bsky.social/about/blog/4...
Directions here for anyone interested in doing the same:
bsky.social/about/blog/4...
bsky.app
November 25, 2024 at 1:13 PM
Thanks Jeremy, for sharing the instructions!
I have moved to a custom domain as well 😊
I have moved to a custom domain as well 😊
I'm going to read this paper next. But my starting point is that ok scepticism.
I feel the uncertainty is beautifully captured by the final softmax's token logprobs.
Let me see what the authors actually have to say...
I feel the uncertainty is beautifully captured by the final softmax's token logprobs.
Let me see what the authors actually have to say...

This is a simple and good paper, which somehow nobody working on these things cites, or even seems to be aware of arxiv.org/abs/2406.05213 It is simple idea that seems useful; it formulates the subjective uncertainty for natural language generation in a decision-theoretic setup.

On Subjective Uncertainty Quantification and Calibration in Natural Language Generation
Applications of large language models often involve the generation of free-form responses, in which case uncertainty quantification becomes challenging. This is due to the need to identify task-specif...
arxiv.org
November 25, 2024 at 12:15 PM
I'm going to read this paper next. But my starting point is that ok scepticism.
I feel the uncertainty is beautifully captured by the final softmax's token logprobs.
Let me see what the authors actually have to say...
I feel the uncertainty is beautifully captured by the final softmax's token logprobs.
Let me see what the authors actually have to say...
Easy for humans. Hard for LLMs.
Even harder sans tool use and iteration👇
Use any mathematical signs wherever you need:
2 + 2 + 2 = 6
3 3 3 = 6
4 4 4 = 6
5 5 5 = 6
6 6 6 = 6
7 7 7 = 6
8 8 8 = 6
9 9 9 = 6
Even harder sans tool use and iteration👇
Use any mathematical signs wherever you need:
2 + 2 + 2 = 6
3 3 3 = 6
4 4 4 = 6
5 5 5 = 6
6 6 6 = 6
7 7 7 = 6
8 8 8 = 6
9 9 9 = 6
November 25, 2024 at 11:58 AM
Easy for humans. Hard for LLMs.
Even harder sans tool use and iteration👇
Use any mathematical signs wherever you need:
2 + 2 + 2 = 6
3 3 3 = 6
4 4 4 = 6
5 5 5 = 6
6 6 6 = 6
7 7 7 = 6
8 8 8 = 6
9 9 9 = 6
Even harder sans tool use and iteration👇
Use any mathematical signs wherever you need:
2 + 2 + 2 = 6
3 3 3 = 6
4 4 4 = 6
5 5 5 = 6
6 6 6 = 6
7 7 7 = 6
8 8 8 = 6
9 9 9 = 6