




Andreas Kirsch
@blackhc.bsky.social
My opinions only here.
👨🔬 RS DeepMind
Past:
👨🔬 R Midjourney 1y 🧑🎓 DPhil AIMS Uni of Oxford 4.5y
🧙♂️ RE DeepMind 1y 📺 SWE Google 3y 🎓 TUM
👤 @nwspk
👨🔬 RS DeepMind
Past:
👨🔬 R Midjourney 1y 🧑🎓 DPhil AIMS Uni of Oxford 4.5y
🧙♂️ RE DeepMind 1y 📺 SWE Google 3y 🎓 TUM
👤 @nwspk
Pinned
Andreas Kirsch
@blackhc.bsky.social
· Jan 7
Ever wondered why presenting more facts can sometimes *worsen* disagreements, even among rational people? 🤔
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
Reposted by Andreas Kirsch

We launched CoverDrop 🎉 providing sources with a secure and anonymous way to talk to journalists. Having started five years ago as a PhD research project, this now ships within the Guardian app to millions of users—all of which provide cover traffic. Paper, code, and more info: www.coverdrop.org
CoverDrop: Blowing the Whistle Through A News App
www.coverdrop.org
June 9, 2025 at 1:00 PM
We launched CoverDrop 🎉 providing sources with a secure and anonymous way to talk to journalists. Having started five years ago as a PhD research project, this now ships within the Guardian app to millions of users—all of which provide cover traffic. Paper, code, and more info: www.coverdrop.org
Reposted by Andreas Kirsch

This is going to be big news in my field. While we wait for the dataset, the stuff about post-processing makes interesting reading (if you're me)

can't wait til they actually upload the dataset to go with this one arxiv.org/abs/2506.08300

Institutional Books 1.0: A 242B token dataset from Harvard Library's collections, refined for accuracy and usability
Large language models (LLMs) use data to learn about the world in order to produce meaningful correlations and predictions. As such, the nature, scale, quality, and diversity of the datasets used to t...
arxiv.org
June 11, 2025 at 8:07 PM
This is going to be big news in my field. While we wait for the dataset, the stuff about post-processing makes interesting reading (if you're me)
What's your favorite Veo video?
June 11, 2025 at 4:44 PM
What's your favorite Veo video?
I'm late to review the "Illusion of Thinking" paper, so let me collect some of the best threads by and critical takes by @scaling01 in one place and sprinkle some of my own thoughts in as well.
The paper is rather critical of reasoning LLMs (LRMs):
x.com/MFarajtabar...
The paper is rather critical of reasoning LLMs (LRMs):
x.com/MFarajtabar...
June 9, 2025 at 9:49 PM
I'm late to review the "Illusion of Thinking" paper, so let me collect some of the best threads by and critical takes by @scaling01 in one place and sprinkle some of my own thoughts in as well.
The paper is rather critical of reasoning LLMs (LRMs):
x.com/MFarajtabar...
The paper is rather critical of reasoning LLMs (LRMs):
x.com/MFarajtabar...
Reposted by Andreas Kirsch

If the last time you tried to use an LLM for math was ~4 or 5 months ago it’s worth firing up Gemini 2.5 (which you can try for free) or ChatGPT o3 and getting a sense of how rapidly things have progressed.
May 20, 2025 at 1:31 PM
If the last time you tried to use an LLM for math was ~4 or 5 months ago it’s worth firing up Gemini 2.5 (which you can try for free) or ChatGPT o3 and getting a sense of how rapidly things have progressed.
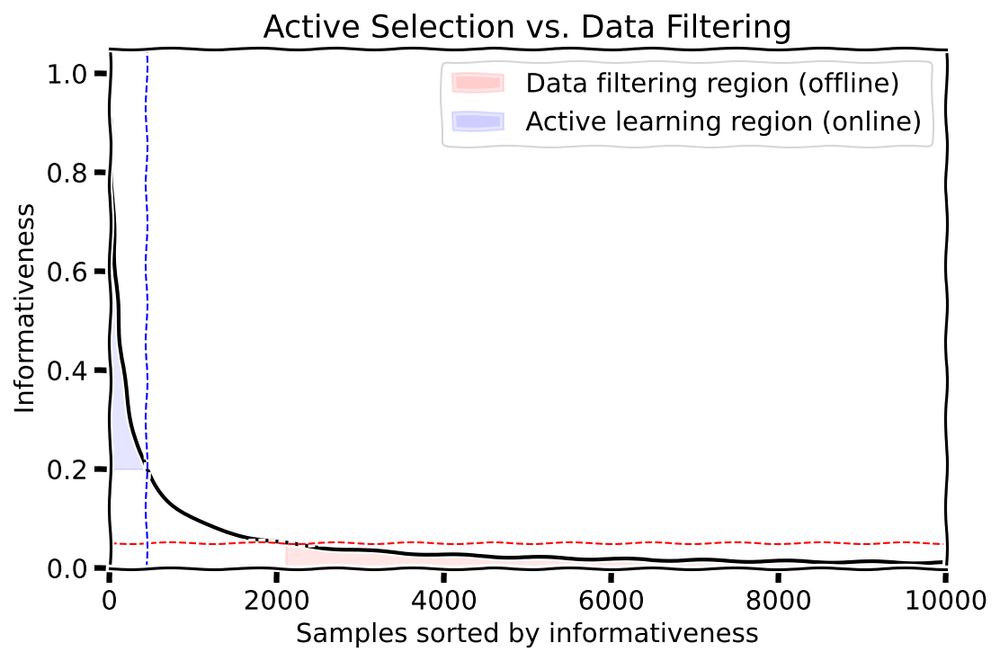
I want to share my latest (very short) blog post: "Active Learning vs. Data Filtering: Selection vs. Rejection."
What is the fundamental difference between active learning and data filtering?
Well, obviously, the difference is that:
1/11
What is the fundamental difference between active learning and data filtering?
Well, obviously, the difference is that:
1/11
May 17, 2025 at 11:47 AM
I want to share my latest (very short) blog post: "Active Learning vs. Data Filtering: Selection vs. Rejection."
What is the fundamental difference between active learning and data filtering?
Well, obviously, the difference is that:
1/11
What is the fundamental difference between active learning and data filtering?
Well, obviously, the difference is that:
1/11
Reposted by Andreas Kirsch

Hive (and all of its expansions) has been added to OpenSpiel! 🎉🤩🐝🐜🕷️🐞🦟🪲
From Gen42: "Hive is an award-winning board game with a difference. There is no board. The pieces are added to the playing area thus creating the board. As more and more pieces are added the game becomes a fight to ...
🧵1/5
From Gen42: "Hive is an award-winning board game with a difference. There is no board. The pieces are added to the playing area thus creating the board. As more and more pieces are added the game becomes a fight to ...
🧵1/5

April 28, 2025 at 12:53 PM
Hive (and all of its expansions) has been added to OpenSpiel! 🎉🤩🐝🐜🕷️🐞🦟🪲
From Gen42: "Hive is an award-winning board game with a difference. There is no board. The pieces are added to the playing area thus creating the board. As more and more pieces are added the game becomes a fight to ...
🧵1/5
From Gen42: "Hive is an award-winning board game with a difference. There is no board. The pieces are added to the playing area thus creating the board. As more and more pieces are added the game becomes a fight to ...
🧵1/5
Reposted by Andreas Kirsch

📢📢 Junior researchers attending #ICLR2025, be sure to check out the mentoring chat sessions!
More info here:
blog.iclr.cc/2025/04/23/i...
You can find all the sessions on the ICLR.cc schedule!
More info here:
blog.iclr.cc/2025/04/23/i...
You can find all the sessions on the ICLR.cc schedule!

April 23, 2025 at 2:01 PM
📢📢 Junior researchers attending #ICLR2025, be sure to check out the mentoring chat sessions!
More info here:
blog.iclr.cc/2025/04/23/i...
You can find all the sessions on the ICLR.cc schedule!
More info here:
blog.iclr.cc/2025/04/23/i...
You can find all the sessions on the ICLR.cc schedule!
I want to share a blog post on our paper "All Models are Wrong, Some are Useful: Model Selection with Limited Labels" which we will present at AISTATS 2025 next week
With @pokanovic.bsky.social, Jannes Kasper, @thoefler.bsky.social, @arkrause.bsky.social, and @nmervegurel.bsky.social
With @pokanovic.bsky.social, Jannes Kasper, @thoefler.bsky.social, @arkrause.bsky.social, and @nmervegurel.bsky.social

April 23, 2025 at 11:20 AM
I want to share a blog post on our paper "All Models are Wrong, Some are Useful: Model Selection with Limited Labels" which we will present at AISTATS 2025 next week
With @pokanovic.bsky.social, Jannes Kasper, @thoefler.bsky.social, @arkrause.bsky.social, and @nmervegurel.bsky.social
With @pokanovic.bsky.social, Jannes Kasper, @thoefler.bsky.social, @arkrause.bsky.social, and @nmervegurel.bsky.social
Reposted by Andreas Kirsch
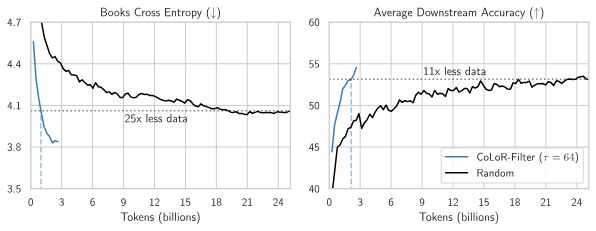
I want to reshare @brandfonbrener.bsky.social's @NeurIPSConf 2024 paper on CoLoR-Filter: A simple yet powerful method for selecting high-quality data for language model pre-training!
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
April 5, 2025 at 12:04 PM
I want to reshare @brandfonbrener.bsky.social's @NeurIPSConf 2024 paper on CoLoR-Filter: A simple yet powerful method for selecting high-quality data for language model pre-training!
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
I want to reshare @brandfonbrener.bsky.social's @NeurIPSConf 2024 paper on CoLoR-Filter: A simple yet powerful method for selecting high-quality data for language model pre-training!
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
April 5, 2025 at 12:04 PM
I want to reshare @brandfonbrener.bsky.social's @NeurIPSConf 2024 paper on CoLoR-Filter: A simple yet powerful method for selecting high-quality data for language model pre-training!
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
Reposted by Andreas Kirsch

The Ukrainian government has a list of places where you can donate to the war effort here. I personally just donated $100: war.ukraine.ua/donate/
Slava Ukraini.
Slava Ukraini.

Donate to Ukraine’s defenders
The National Bank of Ukraine has decided to open a special fundraising account to support the Armed Forces of Ukraine.
war.ukraine.ua
February 28, 2025 at 7:26 PM
The Ukrainian government has a list of places where you can donate to the war effort here. I personally just donated $100: war.ukraine.ua/donate/
Slava Ukraini.
Slava Ukraini.
Reposted by Andreas Kirsch
I am quite excited that our brand-new module "P79: Cryptography and Protocol Engineering" has its first lecture today! @martin.kleppmann.com and I designed the course to bridge the gap between mathematical ideas and the challenge of implementing secure cryptography in the real world. @cst.cam.ac.uk

January 29, 2025 at 1:24 PM
I am quite excited that our brand-new module "P79: Cryptography and Protocol Engineering" has its first lecture today! @martin.kleppmann.com and I designed the course to bridge the gap between mathematical ideas and the challenge of implementing secure cryptography in the real world. @cst.cam.ac.uk
Reposted by Andreas Kirsch

Check out MODEL SELECTOR, a framework for label-efficient selection of pretrained classifiers. We reduce the labeling cost by up to 94.15% to identify the best model.

January 22, 2025 at 8:00 PM
Check out MODEL SELECTOR, a framework for label-efficient selection of pretrained classifiers. We reduce the labeling cost by up to 94.15% to identify the best model.
Reposted by Andreas Kirsch
Ever wondered why presenting more facts can sometimes *worsen* disagreements, even among rational people? 🤔
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
January 7, 2025 at 10:25 PM
Ever wondered why presenting more facts can sometimes *worsen* disagreements, even among rational people? 🤔
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
Reposted by Andreas Kirsch

TMLR is now on Bluesky: be sure to follow @tmlrorg.bsky.social!

🎉Announcing... the 2024 TMLR Outstanding Certifications! (aka, our "best paper" awards!)
Are you bursting with anticipation to see what they are? Check out this blog post, and read down-thread!! 🎉🧵👇 1/n
medium.com/@TmlrOrg/ann...
Are you bursting with anticipation to see what they are? Check out this blog post, and read down-thread!! 🎉🧵👇 1/n
medium.com/@TmlrOrg/ann...
Announcing the 2024 TMLR Outstanding Certification
By the 2024 TMLR Outstanding Paper Committee: Michael Bowling, Brian Kingsbury, Andreas Kirsch, Yingzhen Li, and Eleni Triantafillou
medium.com
January 9, 2025 at 4:12 PM
TMLR is now on Bluesky: be sure to follow @tmlrorg.bsky.social!
Ever wondered why presenting more facts can sometimes *worsen* disagreements, even among rational people? 🤔
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
January 7, 2025 at 10:25 PM
Ever wondered why presenting more facts can sometimes *worsen* disagreements, even among rational people? 🤔
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
I didn't talk about it but I also made heavy use of Claude 3.5 and also o1 and Gemini when creating my lecture series on info theory and active learning in 3.5 weeks:
bsky.app/profile/bla...
bsky.app/profile/bla...

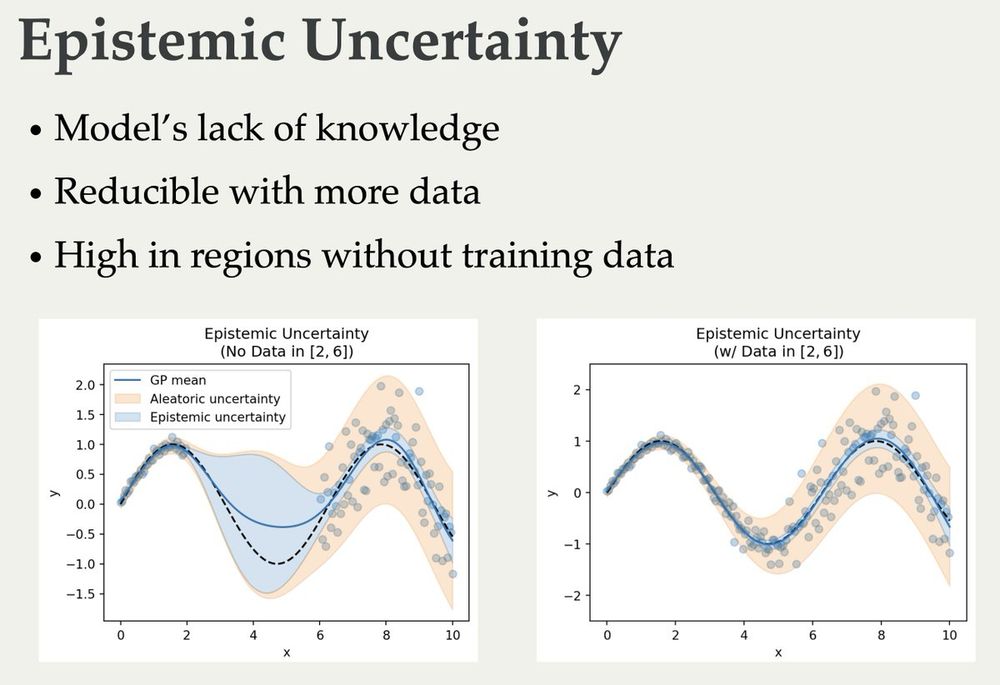
Andreas Kirsch (@blackhc.bsky.social)
The slides for my lectures on (Bayesian) Active Learning, Information Theory, and Uncertainty are online now 🥳 They cover quite a bit from basic information theory to some recent papers:
blackhc.github.io/balitu/
and I'll try to add proper course notes over time 🤗
bsky.app
January 2, 2025 at 5:00 PM
I didn't talk about it but I also made heavy use of Claude 3.5 and also o1 and Gemini when creating my lecture series on info theory and active learning in 3.5 weeks:
bsky.app/profile/bla...
bsky.app/profile/bla...
The slides for my lectures on (Bayesian) Active Learning, Information Theory, and Uncertainty are online now 🥳 They cover quite a bit from basic information theory to some recent papers:
blackhc.github.io/balitu/
and I'll try to add proper course notes over time 🤗
blackhc.github.io/balitu/
and I'll try to add proper course notes over time 🤗
December 17, 2024 at 6:50 AM
The slides for my lectures on (Bayesian) Active Learning, Information Theory, and Uncertainty are online now 🥳 They cover quite a bit from basic information theory to some recent papers:
blackhc.github.io/balitu/
and I'll try to add proper course notes over time 🤗
blackhc.github.io/balitu/
and I'll try to add proper course notes over time 🤗
Reposted by Andreas Kirsch

Just 10 days after o1's public debut, we’re thrilled to unveil the open-source version of the technique behind its success: scaling test-time compute
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!

December 16, 2024 at 9:42 PM
Just 10 days after o1's public debut, we’re thrilled to unveil the open-source version of the technique behind its success: scaling test-time compute
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!
Thanks for following me here! 🫶 I went through my notifications to follow people if they are in ML research, doing PhDs, etc, to have a nice feed focused on ML. Apologies to anyone I have missed! You can unfollow and refollow me to give me a new notification (I suppose)! Plz update your profiles 🙏
December 15, 2024 at 12:30 PM
Thanks for following me here! 🫶 I went through my notifications to follow people if they are in ML research, doing PhDs, etc, to have a nice feed focused on ML. Apologies to anyone I have missed! You can unfollow and refollow me to give me a new notification (I suppose)! Plz update your profiles 🙏
Reposted by Andreas Kirsch

Excited to be presenting my work, "Big batch Bayesian active learning by considering predictive probabilities" at the Bayesian Decision Making & Uncertainty (BDU) Workshop @neuripsconf.bsky.social, as both a lightning talk and a poster!https://openreview.net/pdf?id=VikX9euujU (1/3)

December 14, 2024 at 5:25 PM
Excited to be presenting my work, "Big batch Bayesian active learning by considering predictive probabilities" at the Bayesian Decision Making & Uncertainty (BDU) Workshop @neuripsconf.bsky.social, as both a lightning talk and a poster!https://openreview.net/pdf?id=VikX9euujU (1/3)
Reposted by Andreas Kirsch

The NeurIPS Workshop on Bayesian Decision-making and Uncertainty has started - our first talk is by @mvdw.bsky.social!
Join us at East Meeting Room 8, 15, or online!
Join us at East Meeting Room 8, 15, or online!

December 14, 2024 at 5:45 PM
The NeurIPS Workshop on Bayesian Decision-making and Uncertainty has started - our first talk is by @mvdw.bsky.social!
Join us at East Meeting Room 8, 15, or online!
Join us at East Meeting Room 8, 15, or online!
Reposted by Andreas Kirsch

Hello!
We will be presenting Estimating the Hallucination Rate of Generative AI at NeurIPS. Come if you'd like to chat about epistemic uncertainty for In-Context Learning, or uncertainty more generally. :)
Location: East Exhibit Hall A-C #2703
Time: Friday @ 4:30
Paper: arxiv.org/abs/2406.07457
We will be presenting Estimating the Hallucination Rate of Generative AI at NeurIPS. Come if you'd like to chat about epistemic uncertainty for In-Context Learning, or uncertainty more generally. :)
Location: East Exhibit Hall A-C #2703
Time: Friday @ 4:30
Paper: arxiv.org/abs/2406.07457

December 12, 2024 at 6:13 PM
Hello!
We will be presenting Estimating the Hallucination Rate of Generative AI at NeurIPS. Come if you'd like to chat about epistemic uncertainty for In-Context Learning, or uncertainty more generally. :)
Location: East Exhibit Hall A-C #2703
Time: Friday @ 4:30
Paper: arxiv.org/abs/2406.07457
We will be presenting Estimating the Hallucination Rate of Generative AI at NeurIPS. Come if you'd like to chat about epistemic uncertainty for In-Context Learning, or uncertainty more generally. :)
Location: East Exhibit Hall A-C #2703
Time: Friday @ 4:30
Paper: arxiv.org/abs/2406.07457