



Michel Olvera
@michelolzam.bsky.social
🎧 Machine Listening Researcher
Reposted by Michel Olvera

📢 The short description of the tasks is now available on the website 👇
dcase.community/challenge2025/

DCASE2025 Challenge - DCASE
Introduction Sounds carry a large amount of information...
dcase.community
January 20, 2025 at 2:19 PM
📢 The short description of the tasks is now available on the website 👇
dcase.community/challenge2025/
Reposted by Michel Olvera

Transformers Laid Out by Pramod Goyal
- Give an intuition of how transformers work
- Explain what each section of the paper means and how you can understand and implement it
- Code it down using PyTorch from a beginners perspective
goyalpramod.github.io/blogs/Transf...
- Give an intuition of how transformers work
- Explain what each section of the paper means and how you can understand and implement it
- Code it down using PyTorch from a beginners perspective
goyalpramod.github.io/blogs/Transf...

January 11, 2025 at 9:51 PM
Transformers Laid Out by Pramod Goyal
- Give an intuition of how transformers work
- Explain what each section of the paper means and how you can understand and implement it
- Code it down using PyTorch from a beginners perspective
goyalpramod.github.io/blogs/Transf...
- Give an intuition of how transformers work
- Explain what each section of the paper means and how you can understand and implement it
- Code it down using PyTorch from a beginners perspective
goyalpramod.github.io/blogs/Transf...
If you're at #NeurIPS2024, join @hugomlrd.bsky.social to learn how to bridge the audio-visual modality gap and give your vision-language model the power to hear! 🤖👂
NeurIPS link: neurips.cc/virtual/2024...
Paper: arxiv.org/pdf/2410.05997
🧪📍Poster #3602 (East Hall A-C)
NeurIPS link: neurips.cc/virtual/2024...
Paper: arxiv.org/pdf/2410.05997
🧪📍Poster #3602 (East Hall A-C)

If you want to learn more about audio-visual alignment and how to use it to give audio abilities to your VLM, stop by our @NeurIPSConf poster #3602 (East exhibit hall A-C) today at 11am!

December 13, 2024 at 7:10 PM
If you're at #NeurIPS2024, join @hugomlrd.bsky.social to learn how to bridge the audio-visual modality gap and give your vision-language model the power to hear! 🤖👂
NeurIPS link: neurips.cc/virtual/2024...
Paper: arxiv.org/pdf/2410.05997
🧪📍Poster #3602 (East Hall A-C)
NeurIPS link: neurips.cc/virtual/2024...
Paper: arxiv.org/pdf/2410.05997
🧪📍Poster #3602 (East Hall A-C)
Reposted by Michel Olvera

new paper! 🗣️Sketch2Sound💥
Sketch2Sound can create sounds from sonic imitations (i.e., a vocal imitation or a reference sound) via interpretable, time-varying control signals.
paper: arxiv.org/abs/2412.08550
web: hugofloresgarcia.art/sketch2sound
Sketch2Sound can create sounds from sonic imitations (i.e., a vocal imitation or a reference sound) via interpretable, time-varying control signals.
paper: arxiv.org/abs/2412.08550
web: hugofloresgarcia.art/sketch2sound
December 12, 2024 at 2:43 PM
new paper! 🗣️Sketch2Sound💥
Sketch2Sound can create sounds from sonic imitations (i.e., a vocal imitation or a reference sound) via interpretable, time-varying control signals.
paper: arxiv.org/abs/2412.08550
web: hugofloresgarcia.art/sketch2sound
Sketch2Sound can create sounds from sonic imitations (i.e., a vocal imitation or a reference sound) via interpretable, time-varying control signals.
paper: arxiv.org/abs/2412.08550
web: hugofloresgarcia.art/sketch2sound
Reposted by Michel Olvera
The tasks for DCASE challenge 2025 have been announced.
dcase.community/articles/cha...
Stay tuned for more details.
dcase.community/articles/cha...
Stay tuned for more details.

Challenge tasks for DCASE2025 - DCASE
The DCASE Steering Group has reviewed the task proposals...
dcase.community
December 10, 2024 at 10:13 AM
The tasks for DCASE challenge 2025 have been announced.
dcase.community/articles/cha...
Stay tuned for more details.
dcase.community/articles/cha...
Stay tuned for more details.
Reposted by Michel Olvera

It's possible to do good machine learning research, even without impossibly huge data, without enormous compute clusters, without architecture hacking, and without making unrealistic assumptions of convexity, Gaussianity, etc.
Intriguing Properties of Robust Classification arxiv.org/abs/2412.04245
Intriguing Properties of Robust Classification arxiv.org/abs/2412.04245

Intriguing Properties of Robust Classification
Despite extensive research since the community learned about adversarial examples 10 years ago, we still do not know how to train high-accuracy classifiers that are guaranteed to be robust to small pe...
arxiv.org
December 6, 2024 at 10:24 AM
It's possible to do good machine learning research, even without impossibly huge data, without enormous compute clusters, without architecture hacking, and without making unrealistic assumptions of convexity, Gaussianity, etc.
Intriguing Properties of Robust Classification arxiv.org/abs/2412.04245
Intriguing Properties of Robust Classification arxiv.org/abs/2412.04245
Reposted by Michel Olvera

🚨🚨My team @GoogleDeepMind in Tokyo is looking for a talented research scientist to work on audio generative models! 🔊
Please consider applying if you have expertise in the domain or related areas such as multimodal models, video generation 📹, etc.
boards.greenhouse.io/deepmind/job...
Please consider applying if you have expertise in the domain or related areas such as multimodal models, video generation 📹, etc.
boards.greenhouse.io/deepmind/job...

DeepMind
boards.greenhouse.io
December 6, 2024 at 7:09 AM
🚨🚨My team @GoogleDeepMind in Tokyo is looking for a talented research scientist to work on audio generative models! 🔊
Please consider applying if you have expertise in the domain or related areas such as multimodal models, video generation 📹, etc.
boards.greenhouse.io/deepmind/job...
Please consider applying if you have expertise in the domain or related areas such as multimodal models, video generation 📹, etc.
boards.greenhouse.io/deepmind/job...
Reposted by Michel Olvera

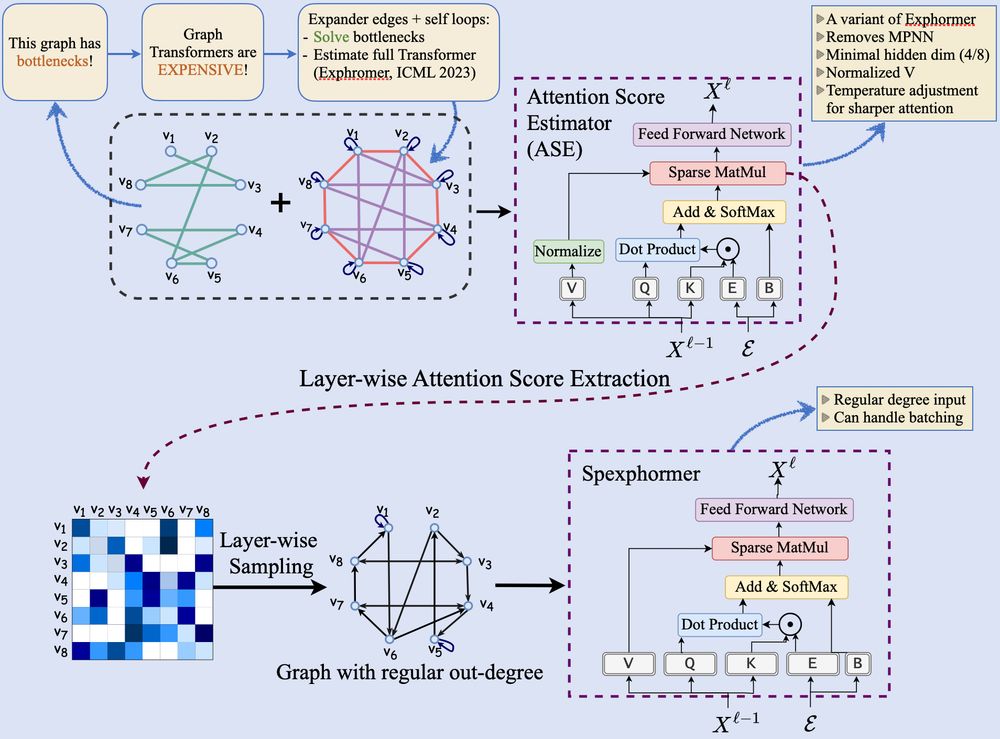
Graph Transformers (GTs) can handle long-range dependencies and resolve information bottlenecks, but they’re computationally expensive. Our new model, Spexphormer, helps scale them to much larger graphs – check it out at NeurIPS next week, or the preview here!
[1/13]
#NeurIPS2024
[1/13]
#NeurIPS2024
December 5, 2024 at 7:58 PM
Graph Transformers (GTs) can handle long-range dependencies and resolve information bottlenecks, but they’re computationally expensive. Our new model, Spexphormer, helps scale them to much larger graphs – check it out at NeurIPS next week, or the preview here!
[1/13]
#NeurIPS2024
[1/13]
#NeurIPS2024
Reposted by Michel Olvera

TACO, a training-free method using NMF to co-factorize audio and visual features from pre-trained models, achieved state-of-the-art unsupervised sound-prompted segmentation.
TACO: Training-free Sound Prompted Segmentation via Deep Audio-visual CO-factorization
Hugo Malard, Michel Olvera, Stephane Lathuiliere, Slim Essid
arxiv.org
December 3, 2024 at 11:41 AM
TACO, a training-free method using NMF to co-factorize audio and visual features from pre-trained models, achieved state-of-the-art unsupervised sound-prompted segmentation.
Shouldn't be any other way! ☺️


November 30, 2024 at 6:25 PM
Shouldn't be any other way! ☺️
Reposted by Michel Olvera

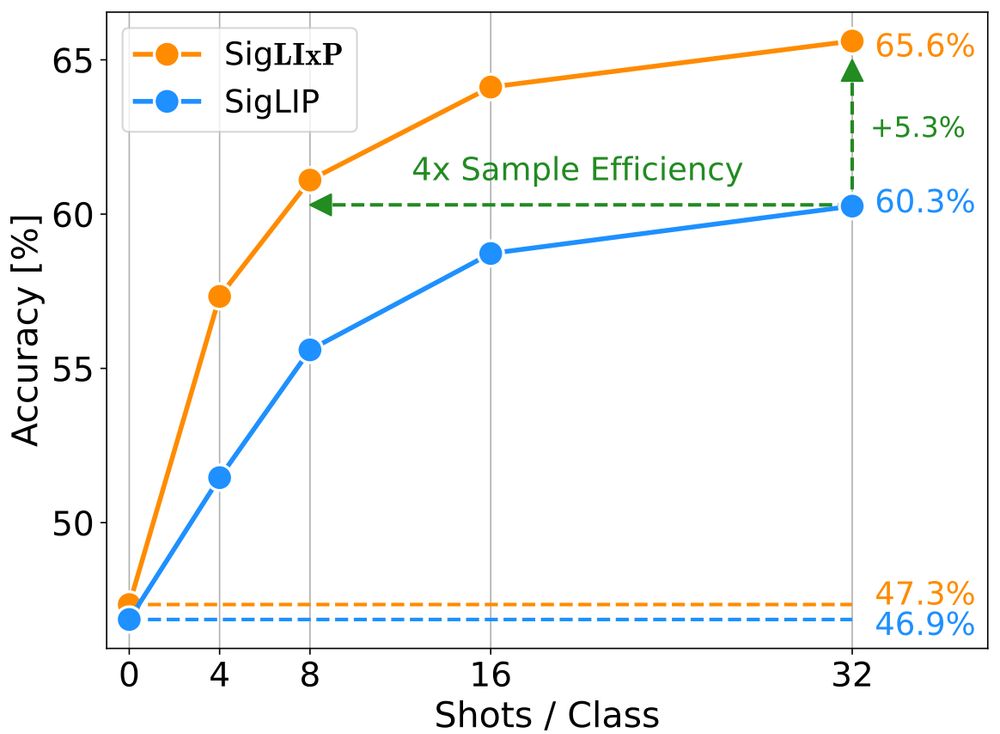
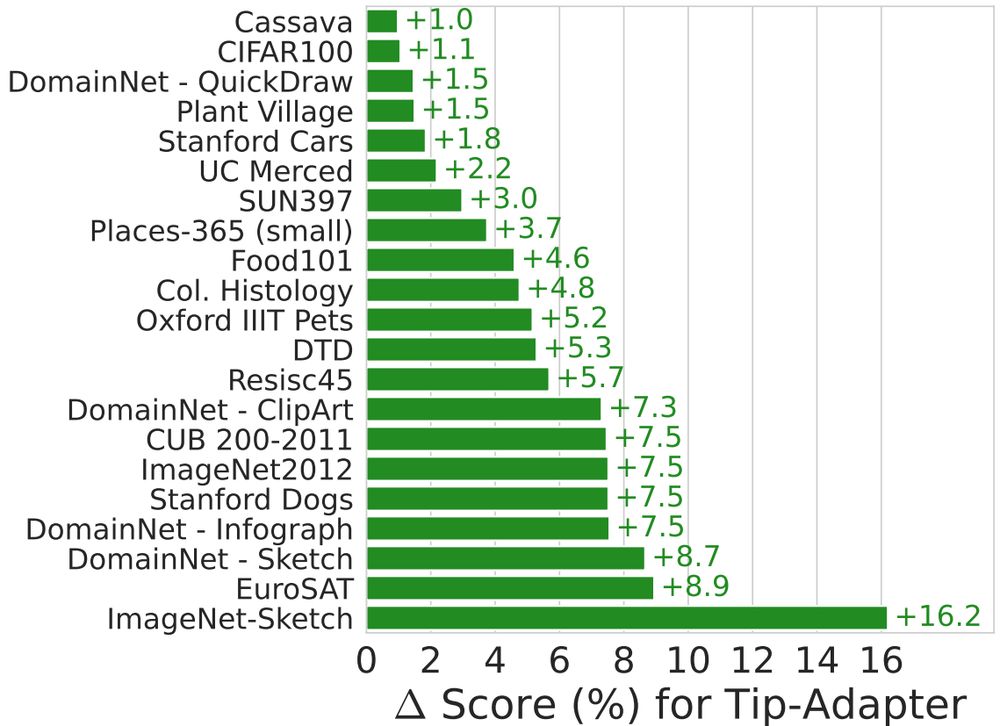
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:

November 28, 2024 at 2:33 PM
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Reposted by Michel Olvera

I made a starter pack for people working or interested in multi-modality learning.
It would be good to add lots more people so do comment and I'll add!
go.bsky.app/97fAH2N
It would be good to add lots more people so do comment and I'll add!
go.bsky.app/97fAH2N
November 27, 2024 at 1:15 PM
I made a starter pack for people working or interested in multi-modality learning.
It would be good to add lots more people so do comment and I'll add!
go.bsky.app/97fAH2N
It would be good to add lots more people so do comment and I'll add!
go.bsky.app/97fAH2N
Reposted by Michel Olvera

Do you know what rating you’ll give after reading the intro? Are your confidence scores 4 or higher? Do you not respond in rebuttal phases? Are you worried how it will look if your rating is the only 8 among 3’s? This thread is for you.
November 27, 2024 at 5:25 PM
Do you know what rating you’ll give after reading the intro? Are your confidence scores 4 or higher? Do you not respond in rebuttal phases? Are you worried how it will look if your rating is the only 8 among 3’s? This thread is for you.
Reposted by Michel Olvera

I was deeply disappointed by the lack of nature/science/climate/enviro on many major end-of-year book lists—so I decided to make my own!
Introducing: ✨🎁📚 The 2024 Holiday Gift Guide to Nature & Science Books ✨🎁📚
Please share: Let's make this go viral in time for Black Friday / holiday shopping!
Introducing: ✨🎁📚 The 2024 Holiday Gift Guide to Nature & Science Books ✨🎁📚
Please share: Let's make this go viral in time for Black Friday / holiday shopping!




November 27, 2024 at 7:08 PM
I was deeply disappointed by the lack of nature/science/climate/enviro on many major end-of-year book lists—so I decided to make my own!
Introducing: ✨🎁📚 The 2024 Holiday Gift Guide to Nature & Science Books ✨🎁📚
Please share: Let's make this go viral in time for Black Friday / holiday shopping!
Introducing: ✨🎁📚 The 2024 Holiday Gift Guide to Nature & Science Books ✨🎁📚
Please share: Let's make this go viral in time for Black Friday / holiday shopping!
Reposted by Michel Olvera

La Era de la Inteligencia Artificial a short documentary produced by Telemundo Houston won a Lone Star Emmy in the Science category www.telemundohouston.com/noticias/tec...

La Era de la Inteligencia Artificial
Nos adentramos a la revolución de la inteligencia artificial con la historia detrás de Ameca, el robot humanoide más avanzado del mundo
www.telemundohouston.com
November 26, 2024 at 3:23 AM
La Era de la Inteligencia Artificial a short documentary produced by Telemundo Houston won a Lone Star Emmy in the Science category www.telemundohouston.com/noticias/tec...
Reposted by Michel Olvera

We published an extended version of our #ICASSP2023 paper:
EPIC-SOUNDS: A Large-scale Dataset of Actions That Sound
+ sound event detection baseline
+ detailed annotations pipeline
+ analysis of visual vs audio events
+ audio-visual models
arxiv.org/abs/2302.006...
EPIC-SOUNDS: A Large-scale Dataset of Actions That Sound
+ sound event detection baseline
+ detailed annotations pipeline
+ analysis of visual vs audio events
+ audio-visual models
arxiv.org/abs/2302.006...

Epic-Sounds: A Large-scale Dataset of Actions That Sound
We introduce Epic-Sounds, a large-scale dataset of audio annotations capturing temporal extents and class labels within the audio stream of the egocentric videos. We propose an annotation pipeline whe...
arxiv.org
November 25, 2024 at 9:04 PM
We published an extended version of our #ICASSP2023 paper:
EPIC-SOUNDS: A Large-scale Dataset of Actions That Sound
+ sound event detection baseline
+ detailed annotations pipeline
+ analysis of visual vs audio events
+ audio-visual models
arxiv.org/abs/2302.006...
EPIC-SOUNDS: A Large-scale Dataset of Actions That Sound
+ sound event detection baseline
+ detailed annotations pipeline
+ analysis of visual vs audio events
+ audio-visual models
arxiv.org/abs/2302.006...
Don't let the scores break your spirit! 💪


November 25, 2024 at 6:12 PM
Don't let the scores break your spirit! 💪
Reposted by Michel Olvera

Outlined an AI research review article for December… I love traveling but I also can’t wait to be back on my computer 😅.
In the meantime, if you are curious how Multimodal LLMs work, I recently wrote an article to explain the main & recent approaches: magazine.sebastianraschka.com/p/understand...
In the meantime, if you are curious how Multimodal LLMs work, I recently wrote an article to explain the main & recent approaches: magazine.sebastianraschka.com/p/understand...

Understanding Multimodal LLMs
An introduction to the main techniques and latest models
magazine.sebastianraschka.com
November 24, 2024 at 6:54 AM
Outlined an AI research review article for December… I love traveling but I also can’t wait to be back on my computer 😅.
In the meantime, if you are curious how Multimodal LLMs work, I recently wrote an article to explain the main & recent approaches: magazine.sebastianraschka.com/p/understand...
In the meantime, if you are curious how Multimodal LLMs work, I recently wrote an article to explain the main & recent approaches: magazine.sebastianraschka.com/p/understand...
Reposted by Michel Olvera

What an awesome video about the Schrödinger equation! www.youtube.com/watch?v=uVKM...
Young people have no idea how they live in a golden age w.r.t. access to knowledge.
Young people have no idea how they live in a golden age w.r.t. access to knowledge.

What is the i really doing in Schrödinger's equation?
YouTube video by Welch Labs
www.youtube.com
November 23, 2024 at 9:30 PM
What an awesome video about the Schrödinger equation! www.youtube.com/watch?v=uVKM...
Young people have no idea how they live in a golden age w.r.t. access to knowledge.
Young people have no idea how they live in a golden age w.r.t. access to knowledge.
Reposted by Michel Olvera

Interested in machine learning in science?
Timo and I recently published a book, and even if you are not a scientist, you'll find useful overviews of topics like causality and robustness.
The best part is that you can read it for free: ml-science-book.com
Timo and I recently published a book, and even if you are not a scientist, you'll find useful overviews of topics like causality and robustness.
The best part is that you can read it for free: ml-science-book.com




November 15, 2024 at 9:46 AM
Interested in machine learning in science?
Timo and I recently published a book, and even if you are not a scientist, you'll find useful overviews of topics like causality and robustness.
The best part is that you can read it for free: ml-science-book.com
Timo and I recently published a book, and even if you are not a scientist, you'll find useful overviews of topics like causality and robustness.
The best part is that you can read it for free: ml-science-book.com
Reposted by Michel Olvera
We're here too now! 🥳
November 22, 2024 at 2:42 PM
We're here too now! 🥳
Reposted by Michel Olvera

For those who missed this post on the-network-that-is-not-to-be-named, I made public my "secrets" for writing a good CVPR paper (or any scientific paper). I've compiled these tips of many years. It's long but hopefully it helps people write better papers. perceiving-systems.blog/en/post/writ...

Writing a good scientific paper
perceiving-systems.blog
November 20, 2024 at 10:18 AM
For those who missed this post on the-network-that-is-not-to-be-named, I made public my "secrets" for writing a good CVPR paper (or any scientific paper). I've compiled these tips of many years. It's long but hopefully it helps people write better papers. perceiving-systems.blog/en/post/writ...
Reposted by Michel Olvera

I initiated a starter pack for Audio ML. Let me know if you'd like to be added/removed.
go.bsky.app/LGmct4z
go.bsky.app/LGmct4z
November 18, 2024 at 4:46 AM
I initiated a starter pack for Audio ML. Let me know if you'd like to be added/removed.
go.bsky.app/LGmct4z
go.bsky.app/LGmct4z