



Michal Wolski
@michalwols.bsky.social
Interested in large vision models
Funemployed, prev founder at bite.ai (acquired by MyFitnessPal), principal ml eng at MFP, 1st employee at Clarifai, ML at Columbia, NYU future labs
Funemployed, prev founder at bite.ai (acquired by MyFitnessPal), principal ml eng at MFP, 1st employee at Clarifai, ML at Columbia, NYU future labs
Reposted by Michal Wolski

I wrote some reflections on DeepSeek, open-source, AI, US and China, starting from Dario's recent essay calling for stronger export controls.
I mostly disagree with his essay and think it missed the point
You can read it here: thomwolf.io/blog/deepsee...
I mostly disagree with his essay and think it missed the point
You can read it here: thomwolf.io/blog/deepsee...
🐳 Some notes on "DeepSeek and export control"
Finally took time to go over Dario's essay on DeepSeek and export control and wrote some notes. I mostly disagree and I think it missed the point.
thomwolf.io
February 1, 2025 at 3:07 PM
I wrote some reflections on DeepSeek, open-source, AI, US and China, starting from Dario's recent essay calling for stronger export controls.
I mostly disagree with his essay and think it missed the point
You can read it here: thomwolf.io/blog/deepsee...
I mostly disagree with his essay and think it missed the point
You can read it here: thomwolf.io/blog/deepsee...
Reposted by Michal Wolski

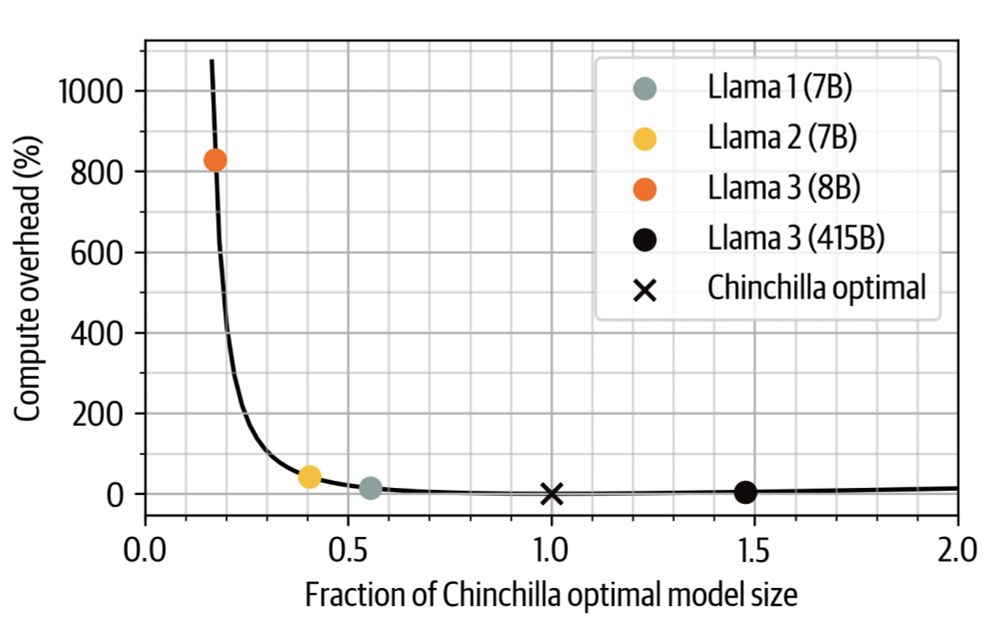
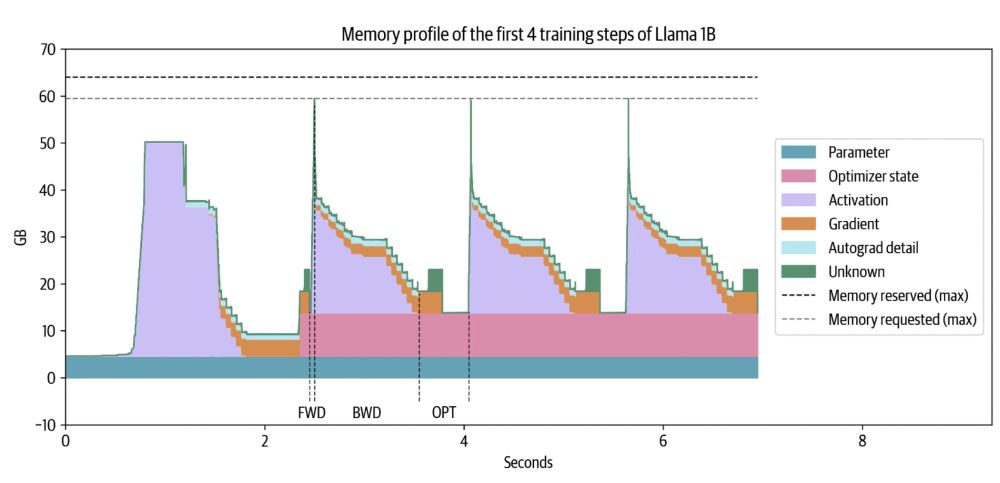
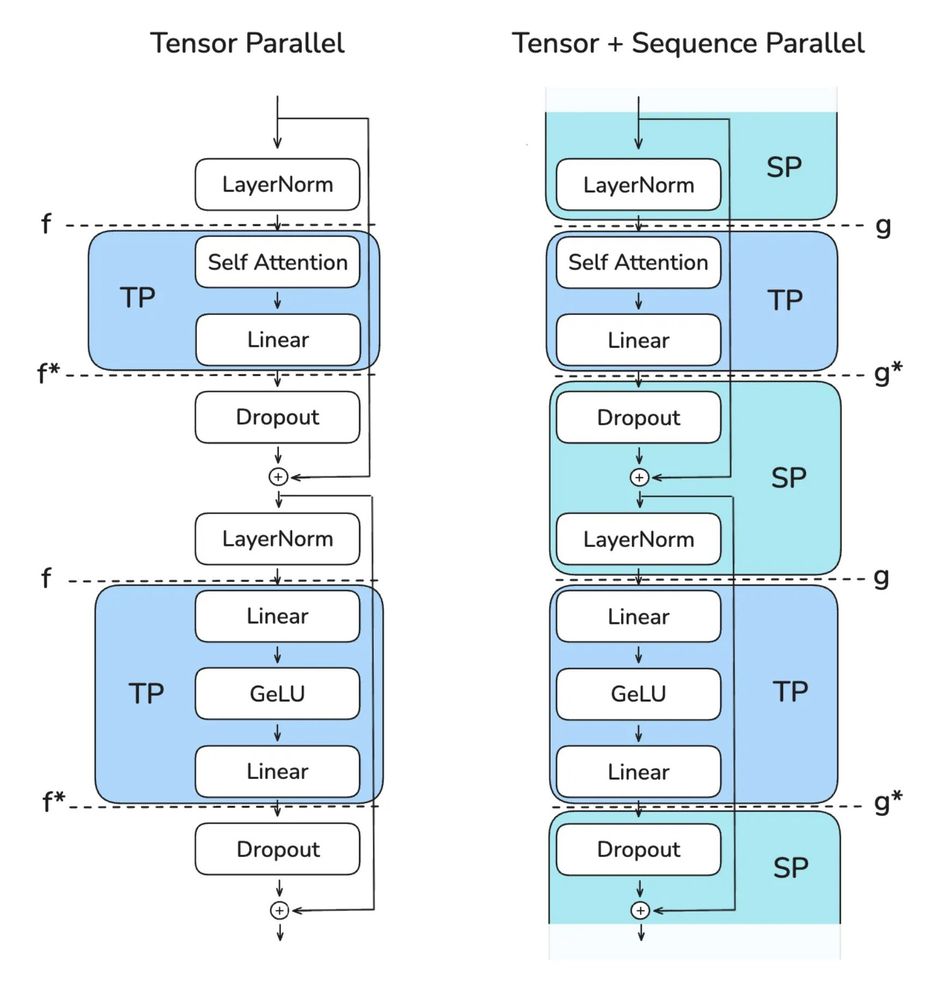
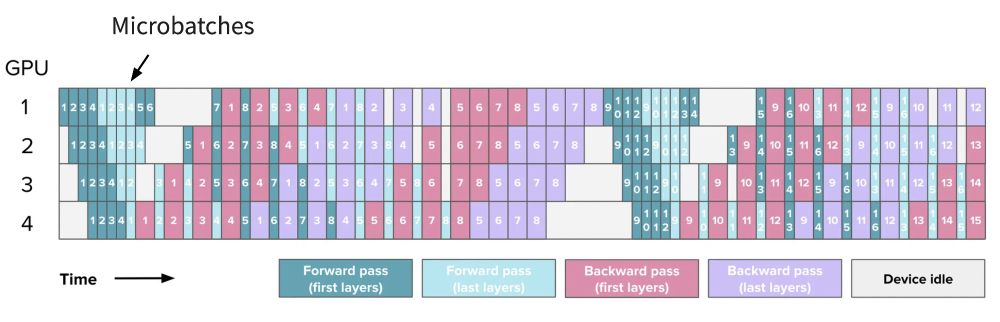
All the things you need to know to pretrain an LLM at home*!
Gave a workshop at Uni Bern: starts with scaling laws and goes to web scale data processing and finishes training with 4D parallelism and ZeRO.
*assuming your home includes an H100 cluster
Gave a workshop at Uni Bern: starts with scaling laws and goes to web scale data processing and finishes training with 4D parallelism and ZeRO.
*assuming your home includes an H100 cluster
November 19, 2024 at 8:37 PM
All the things you need to know to pretrain an LLM at home*!
Gave a workshop at Uni Bern: starts with scaling laws and goes to web scale data processing and finishes training with 4D parallelism and ZeRO.
*assuming your home includes an H100 cluster
Gave a workshop at Uni Bern: starts with scaling laws and goes to web scale data processing and finishes training with 4D parallelism and ZeRO.
*assuming your home includes an H100 cluster
Reposted by Michal Wolski

Deep global descriptors give a convenient way for retrieval, but local descriptors are a game changer in finding needles in a haystack (particular objects in clutter). Due to their high cost, with AMES we optimize the performance/memory trade-off during re-ranking. #ECCV2024

November 20, 2024 at 9:14 PM
Deep global descriptors give a convenient way for retrieval, but local descriptors are a game changer in finding needles in a haystack (particular objects in clutter). Due to their high cost, with AMES we optimize the performance/memory trade-off during re-ranking. #ECCV2024
Reposted by Michal Wolski

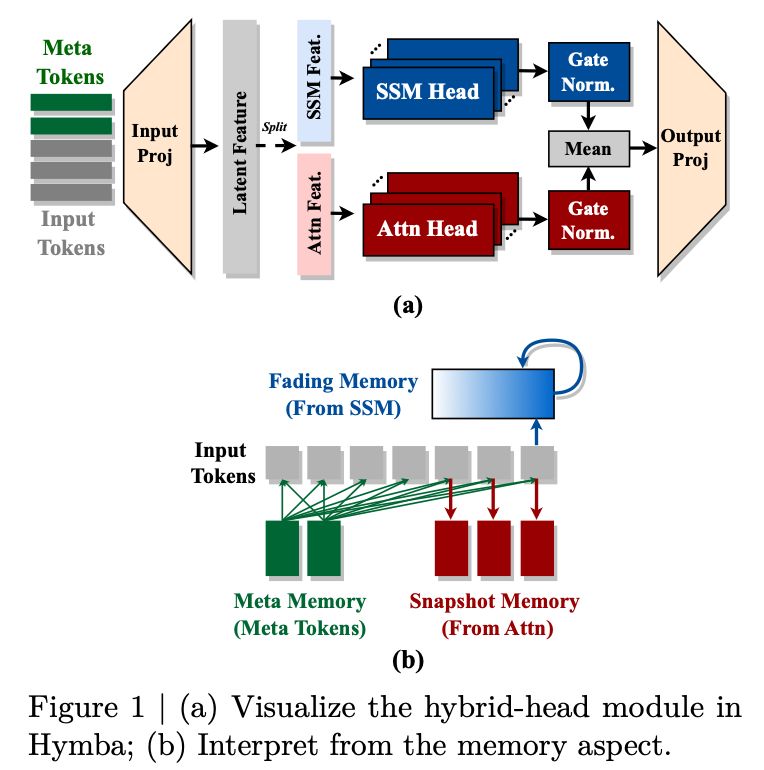
Nvidia's Hymba - an efficient small language model with hybrid architecture.
Their architecture consists of Hymba hybrid blocks, with Mamba and Attention connected in parallel. They found this design to be more effective in disentangling attention into linear and non-linear components.
Their architecture consists of Hymba hybrid blocks, with Mamba and Attention connected in parallel. They found this design to be more effective in disentangling attention into linear and non-linear components.
November 22, 2024 at 5:41 AM
Nvidia's Hymba - an efficient small language model with hybrid architecture.
Their architecture consists of Hymba hybrid blocks, with Mamba and Attention connected in parallel. They found this design to be more effective in disentangling attention into linear and non-linear components.
Their architecture consists of Hymba hybrid blocks, with Mamba and Attention connected in parallel. They found this design to be more effective in disentangling attention into linear and non-linear components.
Reposted by Michal Wolski

𝗗𝗼𝗲𝘀 𝗮𝘂𝘁𝗼𝗿𝗲𝗴𝗿𝗲𝘀𝘀𝗶𝘃𝗲 𝗽𝗿𝗲-𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝘄𝗼𝗿𝗸 𝗳𝗼𝗿 𝘃𝗶𝘀𝗶𝗼𝗻? 🤔
Delighted to share AIMv2, a family of strong, scalable, and open vision encoders that excel at multimodal understanding, recognition, and grounding 🧵
paper: arxiv.org/abs/2411.14402
code: github.com/apple/ml-aim
HF: huggingface.co/collections/...
Delighted to share AIMv2, a family of strong, scalable, and open vision encoders that excel at multimodal understanding, recognition, and grounding 🧵
paper: arxiv.org/abs/2411.14402
code: github.com/apple/ml-aim
HF: huggingface.co/collections/...

November 22, 2024 at 8:32 AM
𝗗𝗼𝗲𝘀 𝗮𝘂𝘁𝗼𝗿𝗲𝗴𝗿𝗲𝘀𝘀𝗶𝘃𝗲 𝗽𝗿𝗲-𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝘄𝗼𝗿𝗸 𝗳𝗼𝗿 𝘃𝗶𝘀𝗶𝗼𝗻? 🤔
Delighted to share AIMv2, a family of strong, scalable, and open vision encoders that excel at multimodal understanding, recognition, and grounding 🧵
paper: arxiv.org/abs/2411.14402
code: github.com/apple/ml-aim
HF: huggingface.co/collections/...
Delighted to share AIMv2, a family of strong, scalable, and open vision encoders that excel at multimodal understanding, recognition, and grounding 🧵
paper: arxiv.org/abs/2411.14402
code: github.com/apple/ml-aim
HF: huggingface.co/collections/...
Reposted by Michal Wolski

Hymba is a hybrid-head architecture for small language models, integrating transformer and state space mechanisms.
It beats llama 3b with only 1.5b parameters
arxiv.org/abs/2411.13676
It beats llama 3b with only 1.5b parameters
arxiv.org/abs/2411.13676

Hymba: A Hybrid-head Architecture for Small Language Models
We propose Hymba, a family of small language models featuring a hybrid-head parallel architecture that integrates transformer attention mechanisms with state space models (SSMs) for enhanced efficienc...
arxiv.org
November 22, 2024 at 11:17 AM
Hymba is a hybrid-head architecture for small language models, integrating transformer and state space mechanisms.
It beats llama 3b with only 1.5b parameters
arxiv.org/abs/2411.13676
It beats llama 3b with only 1.5b parameters
arxiv.org/abs/2411.13676