



Alaa El-Nouby
@alaaelnouby.bsky.social
Research Scientist at @Apple. Previous: @Meta (FAIR), @Inria, @MSFTResearch, @VectorInst and @UofG . Egyptian 🇪🇬
Reposted by Alaa El-Nouby

Check out our Apple research work on scaling laws for native multimodal models! Combined with mixtures of experts, native models develop both specialized and multimodal representations! Lots of rich findings and opportunists for follow up research!

Shukor, Fini, da Costa, Cord, Susskind, El-Nouby: Scaling Laws for Native Multimodal Models Scaling Laws for Native Multimodal Models https://arxiv.org/abs/2504.07951 https://arxiv.org/pdf/2504.07951 https://arxiv.org/html/2504.07951
April 11, 2025 at 10:37 PM
Check out our Apple research work on scaling laws for native multimodal models! Combined with mixtures of experts, native models develop both specialized and multimodal representations! Lots of rich findings and opportunists for follow up research!
Reposted by Alaa El-Nouby

🚨 One question that has always intrigued me is the role of different ways to increase a model's capacity: parameters, parallelizable compute, or sequential compute?
We explored this through the lens of MoEs:
We explored this through the lens of MoEs:

January 28, 2025 at 6:26 AM
🚨 One question that has always intrigued me is the role of different ways to increase a model's capacity: parameters, parallelizable compute, or sequential compute?
We explored this through the lens of MoEs:
We explored this through the lens of MoEs:
Reposted by Alaa El-Nouby

Apple released AIMv2 🍏 a family of state-of-the-art open-set vision encoders
> like CLIP, but add a decoder and train on autoregression 🤯
> 19 open models come in 300M, 600M, 1.2B, 2.7B with resolutions of 224, 336, 448
> Loadable and usable with 🤗 transformers huggingface.co/collections/...
> like CLIP, but add a decoder and train on autoregression 🤯
> 19 open models come in 300M, 600M, 1.2B, 2.7B with resolutions of 224, 336, 448
> Loadable and usable with 🤗 transformers huggingface.co/collections/...
November 22, 2024 at 10:06 AM
Apple released AIMv2 🍏 a family of state-of-the-art open-set vision encoders
> like CLIP, but add a decoder and train on autoregression 🤯
> 19 open models come in 300M, 600M, 1.2B, 2.7B with resolutions of 224, 336, 448
> Loadable and usable with 🤗 transformers huggingface.co/collections/...
> like CLIP, but add a decoder and train on autoregression 🤯
> 19 open models come in 300M, 600M, 1.2B, 2.7B with resolutions of 224, 336, 448
> Loadable and usable with 🤗 transformers huggingface.co/collections/...
Reposted by Alaa El-Nouby

The return of the Autoregressive Image Model: AIMv2 now going multimodal.
Excellent work by @alaaelnouby.bsky.social & team with code and checkpoints already up:
arxiv.org/abs/2411.14402
Excellent work by @alaaelnouby.bsky.social & team with code and checkpoints already up:
arxiv.org/abs/2411.14402


November 22, 2024 at 9:44 AM
The return of the Autoregressive Image Model: AIMv2 now going multimodal.
Excellent work by @alaaelnouby.bsky.social & team with code and checkpoints already up:
arxiv.org/abs/2411.14402
Excellent work by @alaaelnouby.bsky.social & team with code and checkpoints already up:
arxiv.org/abs/2411.14402
Reposted by Alaa El-Nouby

Multimodal Autoregressive Pre-training of Large Vision Encoders
Enrico Fini et 15 al
tl;dr: in title. Scaling laws and ablations.
they claim to be better than SigLIP and DINOv2 for semantic tasks. I would be interested in monodepth performance though.
arxiv.org/abs/2411.14402
Enrico Fini et 15 al
tl;dr: in title. Scaling laws and ablations.
they claim to be better than SigLIP and DINOv2 for semantic tasks. I would be interested in monodepth performance though.
arxiv.org/abs/2411.14402




November 22, 2024 at 8:07 AM
Multimodal Autoregressive Pre-training of Large Vision Encoders
Enrico Fini et 15 al
tl;dr: in title. Scaling laws and ablations.
they claim to be better than SigLIP and DINOv2 for semantic tasks. I would be interested in monodepth performance though.
arxiv.org/abs/2411.14402
Enrico Fini et 15 al
tl;dr: in title. Scaling laws and ablations.
they claim to be better than SigLIP and DINOv2 for semantic tasks. I would be interested in monodepth performance though.
arxiv.org/abs/2411.14402
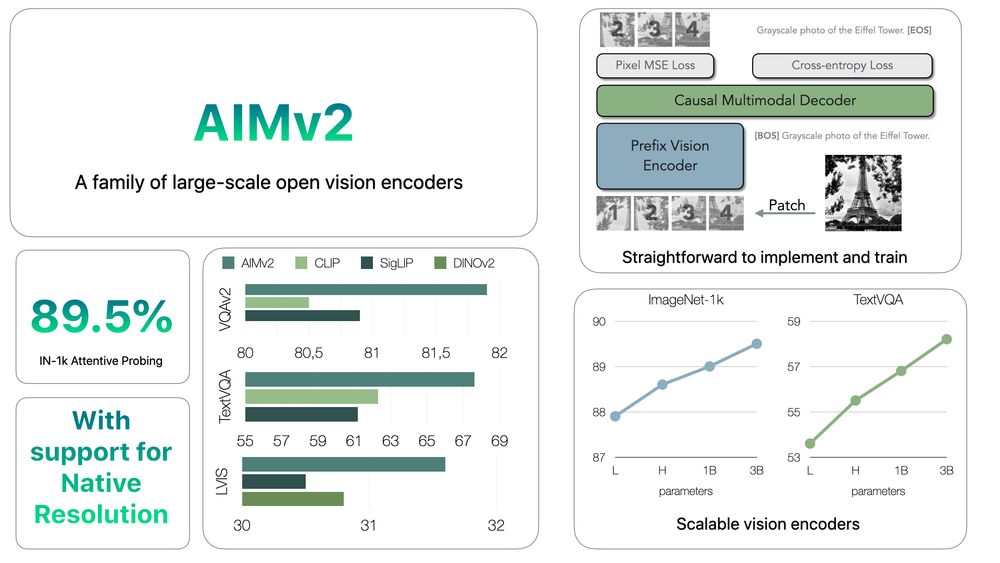
𝗗𝗼𝗲𝘀 𝗮𝘂𝘁𝗼𝗿𝗲𝗴𝗿𝗲𝘀𝘀𝗶𝘃𝗲 𝗽𝗿𝗲-𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝘄𝗼𝗿𝗸 𝗳𝗼𝗿 𝘃𝗶𝘀𝗶𝗼𝗻? 🤔
Delighted to share AIMv2, a family of strong, scalable, and open vision encoders that excel at multimodal understanding, recognition, and grounding 🧵
paper: arxiv.org/abs/2411.14402
code: github.com/apple/ml-aim
HF: huggingface.co/collections/...
Delighted to share AIMv2, a family of strong, scalable, and open vision encoders that excel at multimodal understanding, recognition, and grounding 🧵
paper: arxiv.org/abs/2411.14402
code: github.com/apple/ml-aim
HF: huggingface.co/collections/...

November 22, 2024 at 8:32 AM
𝗗𝗼𝗲𝘀 𝗮𝘂𝘁𝗼𝗿𝗲𝗴𝗿𝗲𝘀𝘀𝗶𝘃𝗲 𝗽𝗿𝗲-𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝘄𝗼𝗿𝗸 𝗳𝗼𝗿 𝘃𝗶𝘀𝗶𝗼𝗻? 🤔
Delighted to share AIMv2, a family of strong, scalable, and open vision encoders that excel at multimodal understanding, recognition, and grounding 🧵
paper: arxiv.org/abs/2411.14402
code: github.com/apple/ml-aim
HF: huggingface.co/collections/...
Delighted to share AIMv2, a family of strong, scalable, and open vision encoders that excel at multimodal understanding, recognition, and grounding 🧵
paper: arxiv.org/abs/2411.14402
code: github.com/apple/ml-aim
HF: huggingface.co/collections/...