



Michael Hanna
@michaelwhanna.bsky.social
PhD Student at the ILLC / UvA doing work at the intersection of (mechanistic) interpretability and cognitive science. Current Anthropic Fellow.
hannamw.github.io
hannamw.github.io
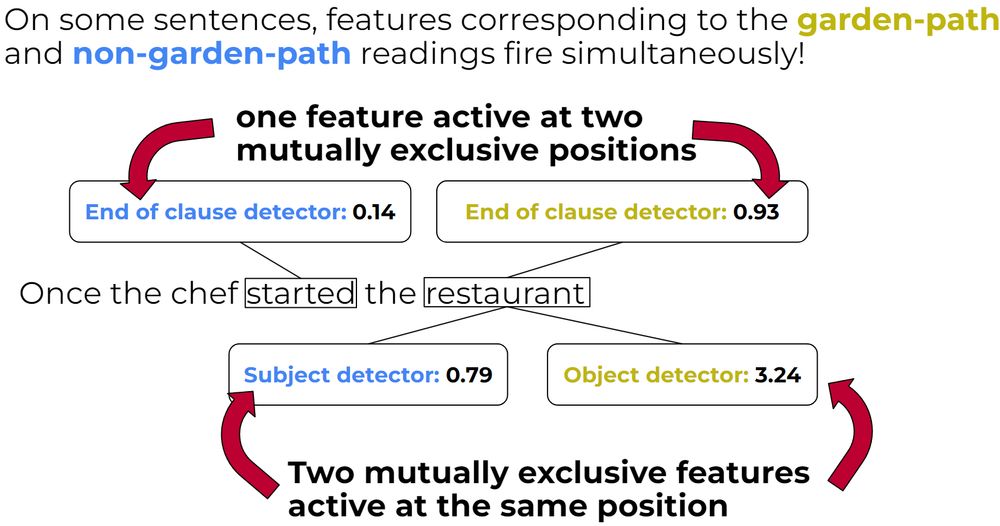
Do LMs represent multiple readings at once? We find that features corresponding to both readings (which should be mutually exclusive) fire at the same time! Structural probes yield the same conclusion, and rely on the same features to do so. 7/10
December 19, 2024 at 1:40 PM
Do LMs represent multiple readings at once? We find that features corresponding to both readings (which should be mutually exclusive) fire at the same time! Structural probes yield the same conclusion, and rely on the same features to do so. 7/10
We can also verify that LMs use these features in the ways that we expect. By deactivating features corresponding to one reading, and strongly activating those corresponding to another, we can control the LM’s preferred reading! 6/10

December 19, 2024 at 1:40 PM
We can also verify that LMs use these features in the ways that we expect. By deactivating features corresponding to one reading, and strongly activating those corresponding to another, we can control the LM’s preferred reading! 6/10
We assemble these features into a circuit describing how they are built up! Earlier layers perform low-level word / part-of-speech detection, while higher-level syntactic features are constructed in later layers. 5/10

December 19, 2024 at 1:40 PM
We assemble these features into a circuit describing how they are built up! Earlier layers perform low-level word / part-of-speech detection, while higher-level syntactic features are constructed in later layers. 5/10
First, we decompose the LM’s activations into SAE features, and find those that cause it to prefer a given reading. Some represent syntactically relevant (and surprisingly complex) features, like subject/objecthood and the ends of subordinate clauses. 4/10

December 19, 2024 at 1:40 PM
First, we decompose the LM’s activations into SAE features, and find those that cause it to prefer a given reading. Some represent syntactically relevant (and surprisingly complex) features, like subject/objecthood and the ends of subordinate clauses. 4/10
We use garden path sentences as a case study. These are great stimuli for this purpose, as they initially suggest one reading, but are later revealed to have another—see figure for example. We propose to use these to do a mechanistic investigation of LM sentence processing! 2/10

December 19, 2024 at 1:40 PM
We use garden path sentences as a case study. These are great stimuli for this purpose, as they initially suggest one reading, but are later revealed to have another—see figure for example. We propose to use these to do a mechanistic investigation of LM sentence processing! 2/10
Sentences are partially understood before they're fully read. How do LMs incrementally interpret their inputs?
In a new paper, @amuuueller.bsky.social and I use mech interp tools to study how LMs process structurally ambiguous sentences. We show LMs rely on both syntactic & spurious features! 1/10
In a new paper, @amuuueller.bsky.social and I use mech interp tools to study how LMs process structurally ambiguous sentences. We show LMs rely on both syntactic & spurious features! 1/10

December 19, 2024 at 1:40 PM
Sentences are partially understood before they're fully read. How do LMs incrementally interpret their inputs?
In a new paper, @amuuueller.bsky.social and I use mech interp tools to study how LMs process structurally ambiguous sentences. We show LMs rely on both syntactic & spurious features! 1/10
In a new paper, @amuuueller.bsky.social and I use mech interp tools to study how LMs process structurally ambiguous sentences. We show LMs rely on both syntactic & spurious features! 1/10