



Michael Hanna
@michaelwhanna.bsky.social
PhD Student at the ILLC / UvA doing work at the intersection of (mechanistic) interpretability and cognitive science. Current Anthropic Fellow.
hannamw.github.io
hannamw.github.io
Reposted by Michael Hanna

(NAACL) When reading a sentence, humans predict what's likely to come next. When the ending is unexpected, this leads to garden-path effects: e.g., "The child bought an ice cream smiled."
Do LLMs show similar mechanisms? @michaelwhanna.bsky.social and I investigate: arxiv.org/abs/2412.05353
Do LLMs show similar mechanisms? @michaelwhanna.bsky.social and I investigate: arxiv.org/abs/2412.05353

Incremental Sentence Processing Mechanisms in Autoregressive Transformer Language Models
Autoregressive transformer language models (LMs) possess strong syntactic abilities, often successfully handling phenomena from agreement to NPI licensing. However, the features they use to incrementa...
arxiv.org
March 11, 2025 at 2:30 PM
(NAACL) When reading a sentence, humans predict what's likely to come next. When the ending is unexpected, this leads to garden-path effects: e.g., "The child bought an ice cream smiled."
Do LLMs show similar mechanisms? @michaelwhanna.bsky.social and I investigate: arxiv.org/abs/2412.05353
Do LLMs show similar mechanisms? @michaelwhanna.bsky.social and I investigate: arxiv.org/abs/2412.05353
Want to know the whole story? Check out the pre-print here! arxiv.org/abs/2412.05353 10/10

Incremental Sentence Processing Mechanisms in Autoregressive Transformer Language Models
Autoregressive transformer language models (LMs) possess strong syntactic abilities, often successfully handling phenomena from agreement to NPI licensing. However, the features they use to incrementa...
arxiv.org
December 19, 2024 at 1:40 PM
Want to know the whole story? Check out the pre-print here! arxiv.org/abs/2412.05353 10/10
Unexpectedly, we find that, when answering follow-up questions like "The boy fed the chicken smiled. Did the boy feed the chicken?", LMs don't repair or rely on earlier syntactic features! But they also don't generate new syntactic features. 9/10
December 19, 2024 at 1:40 PM
Unexpectedly, we find that, when answering follow-up questions like "The boy fed the chicken smiled. Did the boy feed the chicken?", LMs don't repair or rely on earlier syntactic features! But they also don't generate new syntactic features. 9/10
What do LMs do when the ambiguity is resolved? Do they repair their initial representations—which could look like adding on to the circuit we've shown? Or do they reanalyze—for example, by ignoring that circuit and using new syntactic features? 8/10
December 19, 2024 at 1:40 PM
What do LMs do when the ambiguity is resolved? Do they repair their initial representations—which could look like adding on to the circuit we've shown? Or do they reanalyze—for example, by ignoring that circuit and using new syntactic features? 8/10
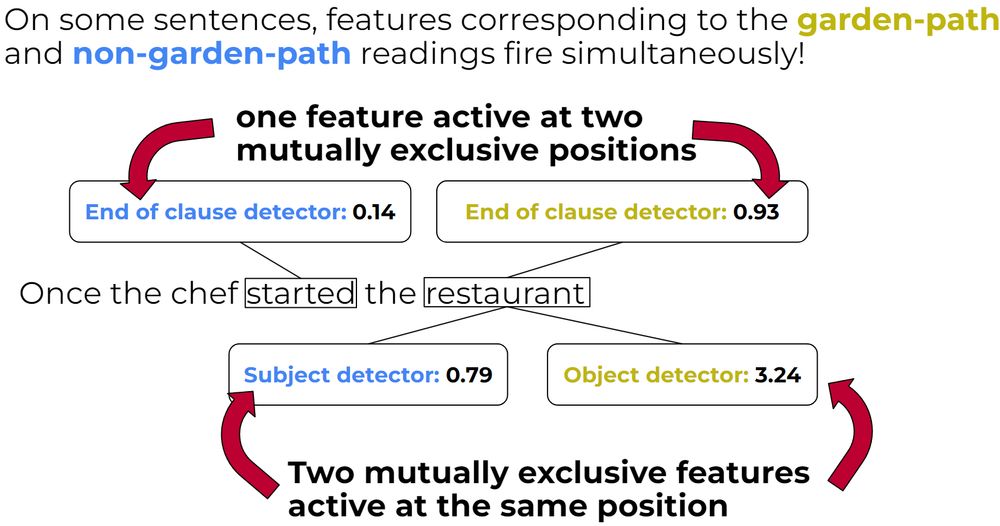
Do LMs represent multiple readings at once? We find that features corresponding to both readings (which should be mutually exclusive) fire at the same time! Structural probes yield the same conclusion, and rely on the same features to do so. 7/10
December 19, 2024 at 1:40 PM
Do LMs represent multiple readings at once? We find that features corresponding to both readings (which should be mutually exclusive) fire at the same time! Structural probes yield the same conclusion, and rely on the same features to do so. 7/10
We can also verify that LMs use these features in the ways that we expect. By deactivating features corresponding to one reading, and strongly activating those corresponding to another, we can control the LM’s preferred reading! 6/10

December 19, 2024 at 1:40 PM
We can also verify that LMs use these features in the ways that we expect. By deactivating features corresponding to one reading, and strongly activating those corresponding to another, we can control the LM’s preferred reading! 6/10
We assemble these features into a circuit describing how they are built up! Earlier layers perform low-level word / part-of-speech detection, while higher-level syntactic features are constructed in later layers. 5/10

December 19, 2024 at 1:40 PM
We assemble these features into a circuit describing how they are built up! Earlier layers perform low-level word / part-of-speech detection, while higher-level syntactic features are constructed in later layers. 5/10
First, we decompose the LM’s activations into SAE features, and find those that cause it to prefer a given reading. Some represent syntactically relevant (and surprisingly complex) features, like subject/objecthood and the ends of subordinate clauses. 4/10

December 19, 2024 at 1:40 PM
First, we decompose the LM’s activations into SAE features, and find those that cause it to prefer a given reading. Some represent syntactically relevant (and surprisingly complex) features, like subject/objecthood and the ends of subordinate clauses. 4/10
How humans process sentences like these has been hotly debated. Do we consider only one reading, or many at once? And if we realize our reading was wrong, do we repair our representations or reanalyze from scratch? We set out to answer these questions in LMs! 3/10
December 19, 2024 at 1:40 PM
How humans process sentences like these has been hotly debated. Do we consider only one reading, or many at once? And if we realize our reading was wrong, do we repair our representations or reanalyze from scratch? We set out to answer these questions in LMs! 3/10
We use garden path sentences as a case study. These are great stimuli for this purpose, as they initially suggest one reading, but are later revealed to have another—see figure for example. We propose to use these to do a mechanistic investigation of LM sentence processing! 2/10

December 19, 2024 at 1:40 PM
We use garden path sentences as a case study. These are great stimuli for this purpose, as they initially suggest one reading, but are later revealed to have another—see figure for example. We propose to use these to do a mechanistic investigation of LM sentence processing! 2/10
Would love to be added to this!
November 26, 2024 at 3:50 PM
Would love to be added to this!
Thanks for having me, and for the great questions and discussion! The pleasure was all mine 😁
November 22, 2024 at 4:05 PM
Thanks for having me, and for the great questions and discussion! The pleasure was all mine 😁