



Forgot to tag the one and only @hadasorgad.bsky.social !!!
March 31, 2025 at 5:39 PM
Forgot to tag the one and only @hadasorgad.bsky.social !!!
Check out our paper and code for more details, analyses, and cool examples!
🔗 Paper: arxiv.org/abs/2501.08319
🔗 HF: huggingface.co/papers/2501.08319
🔗 Code: github.com/yoavgur/Feature-Descriptions
7/
🔗 Paper: arxiv.org/abs/2501.08319
🔗 HF: huggingface.co/papers/2501.08319
🔗 Code: github.com/yoavgur/Feature-Descriptions
7/

Enhancing Automated Interpretability with Output-Centric Feature Descriptions
Automated interpretability pipelines generate natural language descriptions for the concepts represented by features in large language models (LLMs), such as plants or the first word in a sentence. Th...
arxiv.org
January 28, 2025 at 7:38 PM
Check out our paper and code for more details, analyses, and cool examples!
🔗 Paper: arxiv.org/abs/2501.08319
🔗 HF: huggingface.co/papers/2501.08319
🔗 Code: github.com/yoavgur/Feature-Descriptions
7/
🔗 Paper: arxiv.org/abs/2501.08319
🔗 HF: huggingface.co/papers/2501.08319
🔗 Code: github.com/yoavgur/Feature-Descriptions
7/
In a final experiment, we show that output-centric methods can be used to "revive" features previously thought to be "dead" 🧟♂️ reviving hundreds of SAE features in Gemma 2! 6/

January 28, 2025 at 7:38 PM
In a final experiment, we show that output-centric methods can be used to "revive" features previously thought to be "dead" 🧟♂️ reviving hundreds of SAE features in Gemma 2! 6/
In a final experiment, we show that output-centric methods can be used to "revive" features previously thought to be "dead" 🧟♂️ reviving hundreds of SAE features in Gemma 2! 6/
January 28, 2025 at 7:38 PM
In a final experiment, we show that output-centric methods can be used to "revive" features previously thought to be "dead" 🧟♂️ reviving hundreds of SAE features in Gemma 2! 6/
Unsurprisingly, while activating inputs better describe what activates a feature, output-centric methods do much better at predicting how steering the feature will affect the model’s output!
But combining the two works best! 🚀 5/
But combining the two works best! 🚀 5/

January 28, 2025 at 7:37 PM
Unsurprisingly, while activating inputs better describe what activates a feature, output-centric methods do much better at predicting how steering the feature will affect the model’s output!
But combining the two works best! 🚀 5/
But combining the two works best! 🚀 5/
Next, we evaluate the widely-used activating inputs approach versus two output-centric methods:
- vocabulary projection (a.k.a logit lens)
- tokens with max probability change in the output
Our output-centric methods require no more than a few inference passes! 4/
- vocabulary projection (a.k.a logit lens)
- tokens with max probability change in the output
Our output-centric methods require no more than a few inference passes! 4/
January 28, 2025 at 7:36 PM
Next, we evaluate the widely-used activating inputs approach versus two output-centric methods:
- vocabulary projection (a.k.a logit lens)
- tokens with max probability change in the output
Our output-centric methods require no more than a few inference passes! 4/
- vocabulary projection (a.k.a logit lens)
- tokens with max probability change in the output
Our output-centric methods require no more than a few inference passes! 4/
To fix this, we first propose using both input- and output-based evaluations for feature descriptions.
Our output-based eval measures how well a description of a feature captures its effect on the model's generation. 3/
Our output-based eval measures how well a description of a feature captures its effect on the model's generation. 3/

January 28, 2025 at 7:36 PM
To fix this, we first propose using both input- and output-based evaluations for feature descriptions.
Our output-based eval measures how well a description of a feature captures its effect on the model's generation. 3/
Our output-based eval measures how well a description of a feature captures its effect on the model's generation. 3/
Autointerp pipelines describe neurons and SAE features based on inputs that activate them.
This is problematic ⚠️
1. Collecting activations for large data is expensive, time-consuming, and often unfeasible.
2. It overlooks how features affect model outputs!
2/
This is problematic ⚠️
1. Collecting activations for large data is expensive, time-consuming, and often unfeasible.
2. It overlooks how features affect model outputs!
2/
January 28, 2025 at 7:35 PM
Autointerp pipelines describe neurons and SAE features based on inputs that activate them.
This is problematic ⚠️
1. Collecting activations for large data is expensive, time-consuming, and often unfeasible.
2. It overlooks how features affect model outputs!
2/
This is problematic ⚠️
1. Collecting activations for large data is expensive, time-consuming, and often unfeasible.
2. It overlooks how features affect model outputs!
2/
Check out our paper and code for more details and cool results!
Paper: arxiv.org/abs/2412.11965
Code: github.com/amitelhelo/M...
(10/10!)
Paper: arxiv.org/abs/2412.11965
Code: github.com/amitelhelo/M...
(10/10!)
Inferring Functionality of Attention Heads from their Parameters
Attention heads are one of the building blocks of large language models (LLMs). Prior work on investigating their operation mostly focused on analyzing their behavior during inference for specific cir...
arxiv.org
December 18, 2024 at 6:01 PM
Check out our paper and code for more details and cool results!
Paper: arxiv.org/abs/2412.11965
Code: github.com/amitelhelo/M...
(10/10!)
Paper: arxiv.org/abs/2412.11965
Code: github.com/amitelhelo/M...
(10/10!)
Most operation descriptions are plausible based on human judgment.
We also observe interesting operations implemented by heads, like the extension of time periods (day → month → year) and association of known figures with years relevant to their historical significance (9/10)
We also observe interesting operations implemented by heads, like the extension of time periods (day → month → year) and association of known figures with years relevant to their historical significance (9/10)

December 18, 2024 at 6:01 PM
Most operation descriptions are plausible based on human judgment.
We also observe interesting operations implemented by heads, like the extension of time periods (day → month → year) and association of known figures with years relevant to their historical significance (9/10)
We also observe interesting operations implemented by heads, like the extension of time periods (day → month → year) and association of known figures with years relevant to their historical significance (9/10)
Next, we establish an automatic pipeline that uses GPT-4o to annotate the salient mappings from MAPS.
We map the attention heads of Pythia 6.9B and GPT2-xl and manage to identify operations for most heads, reaching 60%-96% in the middle and upper layers (8/10)
We map the attention heads of Pythia 6.9B and GPT2-xl and manage to identify operations for most heads, reaching 60%-96% in the middle and upper layers (8/10)
December 18, 2024 at 6:00 PM
Next, we establish an automatic pipeline that uses GPT-4o to annotate the salient mappings from MAPS.
We map the attention heads of Pythia 6.9B and GPT2-xl and manage to identify operations for most heads, reaching 60%-96% in the middle and upper layers (8/10)
We map the attention heads of Pythia 6.9B and GPT2-xl and manage to identify operations for most heads, reaching 60%-96% in the middle and upper layers (8/10)
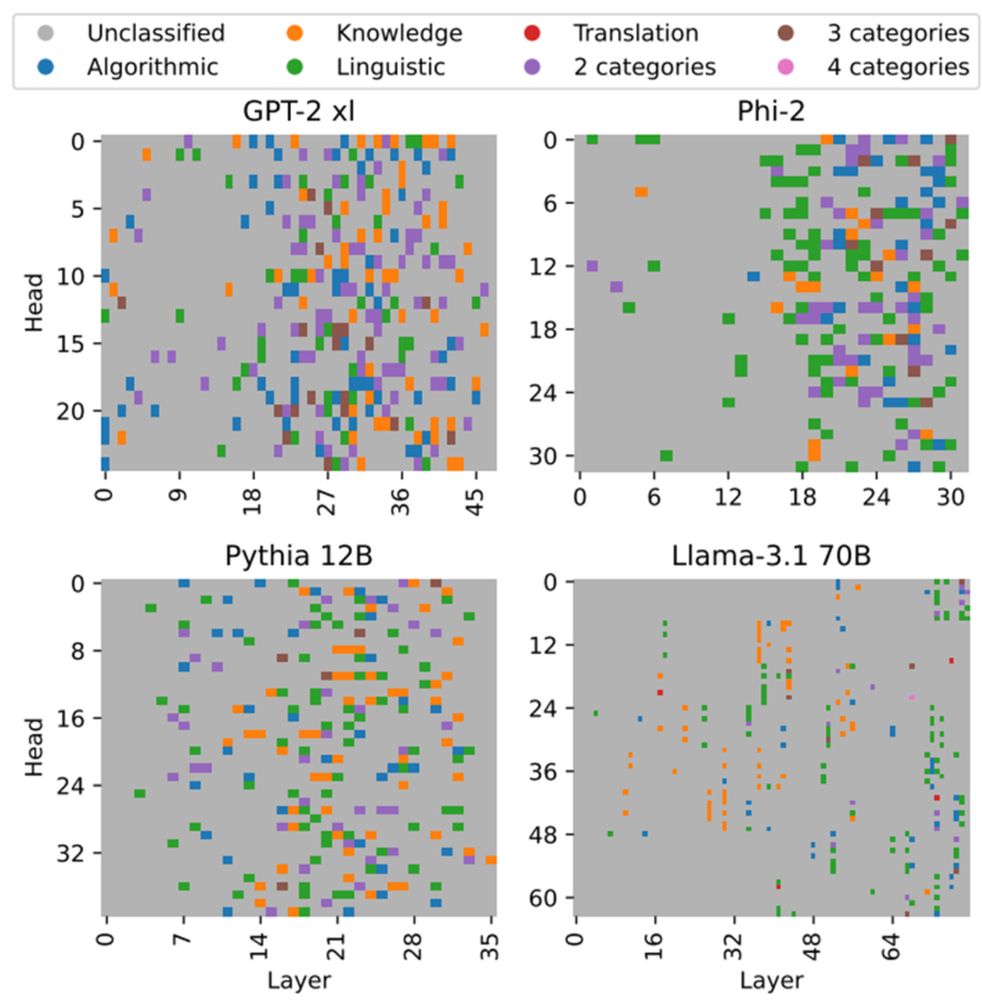
(3) Smaller models tend to encode higher numbers of relations in a single head
(4) In Llama-3.1 models, which use grouped-query attention, grouped heads often implement the same or similar relations (7/10)
(4) In Llama-3.1 models, which use grouped-query attention, grouped heads often implement the same or similar relations (7/10)
December 18, 2024 at 5:59 PM
(3) Smaller models tend to encode higher numbers of relations in a single head
(4) In Llama-3.1 models, which use grouped-query attention, grouped heads often implement the same or similar relations (7/10)
(4) In Llama-3.1 models, which use grouped-query attention, grouped heads often implement the same or similar relations (7/10)
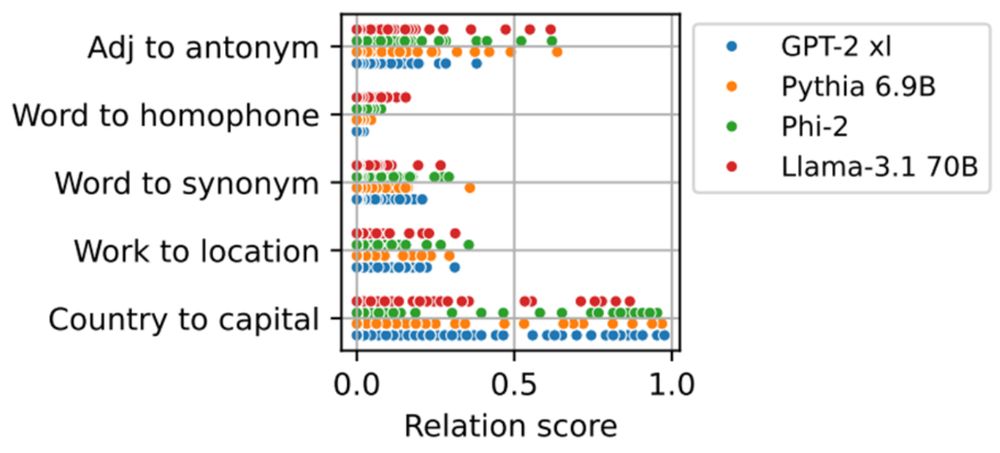
(1) Different models encode certain relations across attention heads to similar degrees
(2) Different heads implement the same relation to varying degrees, which has implications for localization and editing of LLMs (6/10)
(2) Different heads implement the same relation to varying degrees, which has implications for localization and editing of LLMs (6/10)
December 18, 2024 at 5:58 PM
(1) Different models encode certain relations across attention heads to similar degrees
(2) Different heads implement the same relation to varying degrees, which has implications for localization and editing of LLMs (6/10)
(2) Different heads implement the same relation to varying degrees, which has implications for localization and editing of LLMs (6/10)
Using MAPS, we study the distribution of operations across heads in different models -- Llama, Pythia, Phi, GPT2 -- and see some cool trends of function encoding universality and architecture biases: (5/10)
December 18, 2024 at 5:58 PM
Using MAPS, we study the distribution of operations across heads in different models -- Llama, Pythia, Phi, GPT2 -- and see some cool trends of function encoding universality and architecture biases: (5/10)
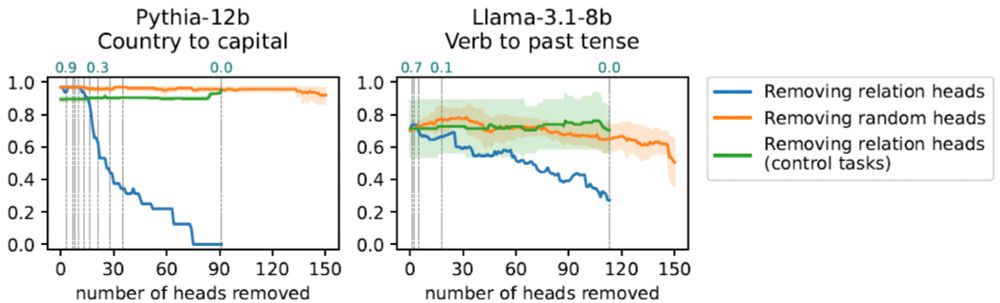
Experiments on 20 operations and 6 LLMs show that MAPS estimations strongly correlate with the head’s outputs during inference
Ablating heads implementing an operation damages the model’s ability to perform tasks requiring the operation compared to removing other heads (4/10)
Ablating heads implementing an operation damages the model’s ability to perform tasks requiring the operation compared to removing other heads (4/10)
December 18, 2024 at 5:57 PM
Experiments on 20 operations and 6 LLMs show that MAPS estimations strongly correlate with the head’s outputs during inference
Ablating heads implementing an operation damages the model’s ability to perform tasks requiring the operation compared to removing other heads (4/10)
Ablating heads implementing an operation damages the model’s ability to perform tasks requiring the operation compared to removing other heads (4/10)