



Max Zhdanov
@maxxxzdn.bsky.social
PhD candidate at AMLab with Max Welling and Jan-Willem van de Meent.
Research in physics-inspired and geometric deep learning.
Research in physics-inspired and geometric deep learning.
thats a wrap!
you can find the code here: github.com/maxxxzdn/erwin
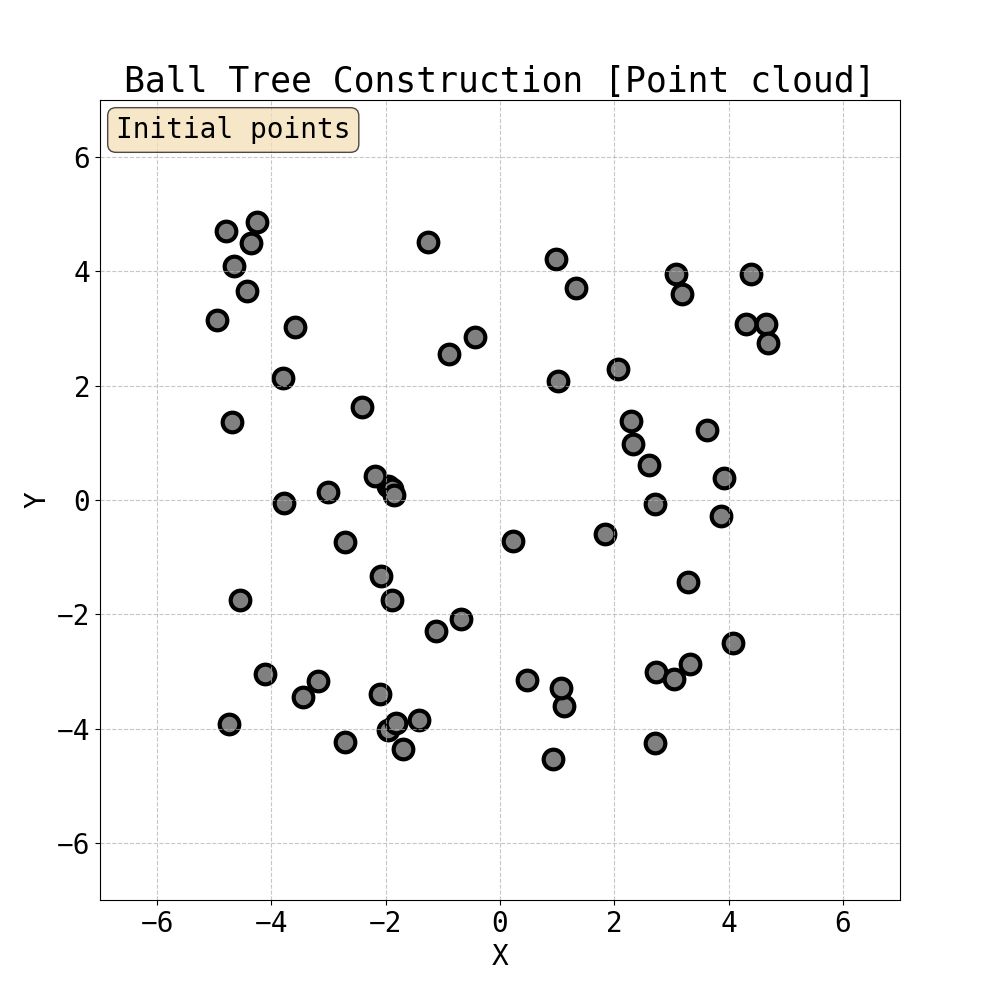
and here is a cute visualisation of Ball Tree building:
you can find the code here: github.com/maxxxzdn/erwin
and here is a cute visualisation of Ball Tree building:
June 21, 2025 at 4:23 PM
thats a wrap!
you can find the code here: github.com/maxxxzdn/erwin
and here is a cute visualisation of Ball Tree building:
you can find the code here: github.com/maxxxzdn/erwin
and here is a cute visualisation of Ball Tree building:
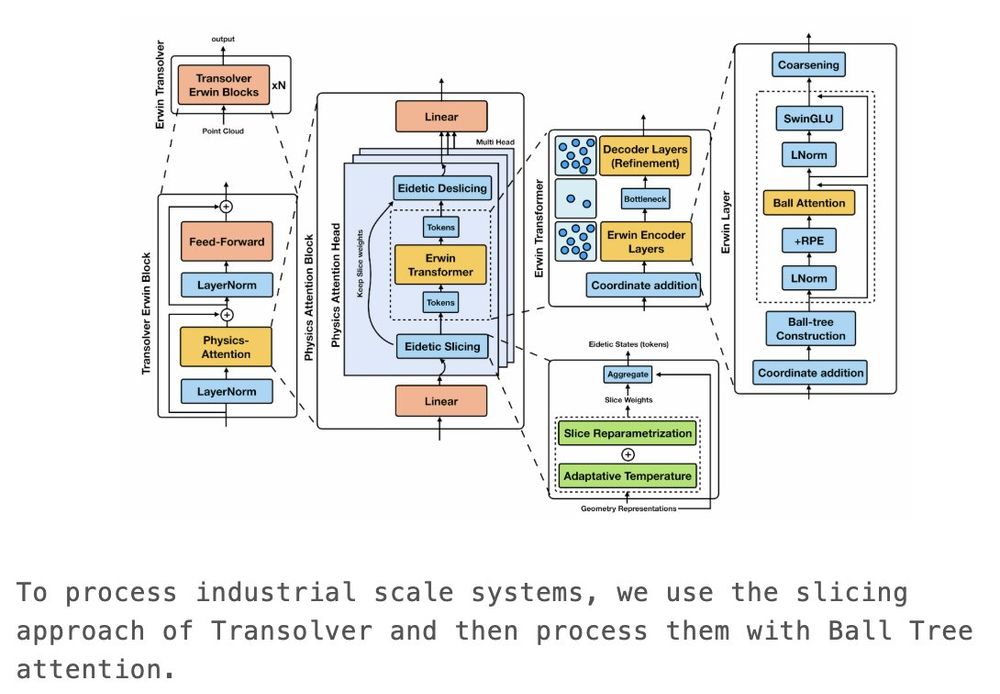
To scale Erwin further to gigantic industrial datasets, we combine Transolver and Erwin by applying ball tree attention over latent tokens.
The key insight is that by using Erwin, we can afford larger bottleneck sizes while maintaining efficiency.
Stay tuned for updates!
The key insight is that by using Erwin, we can afford larger bottleneck sizes while maintaining efficiency.
Stay tuned for updates!
June 21, 2025 at 4:23 PM
To scale Erwin further to gigantic industrial datasets, we combine Transolver and Erwin by applying ball tree attention over latent tokens.
The key insight is that by using Erwin, we can afford larger bottleneck sizes while maintaining efficiency.
Stay tuned for updates!
The key insight is that by using Erwin, we can afford larger bottleneck sizes while maintaining efficiency.
Stay tuned for updates!
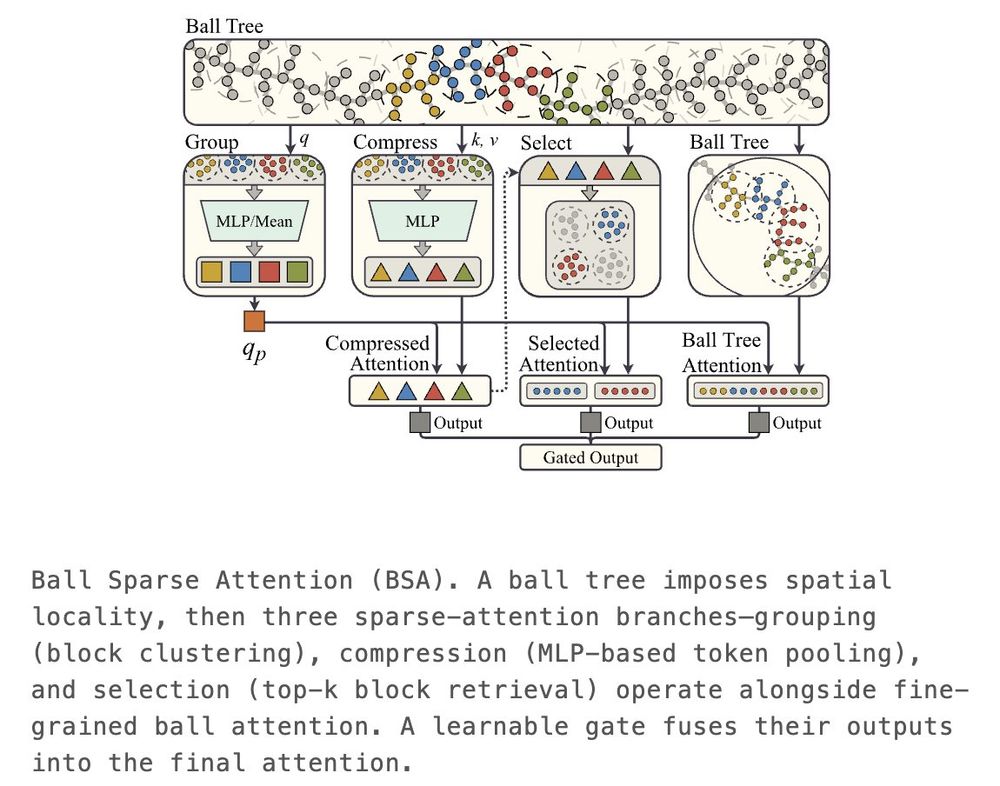
To improve the processing of long-range information while keeping the cost sub-quadratic, we combine the ball tree with Native Sparse Attention (NSA), which align naturally with each other.
Accepted to Long-Context Foundation Models at ICML 2025!
paper: arxiv.org/abs/2506.12541
Accepted to Long-Context Foundation Models at ICML 2025!
paper: arxiv.org/abs/2506.12541
June 21, 2025 at 4:23 PM
To improve the processing of long-range information while keeping the cost sub-quadratic, we combine the ball tree with Native Sparse Attention (NSA), which align naturally with each other.
Accepted to Long-Context Foundation Models at ICML 2025!
paper: arxiv.org/abs/2506.12541
Accepted to Long-Context Foundation Models at ICML 2025!
paper: arxiv.org/abs/2506.12541
There are many possible directions for building upon this work. I will highlight two on which I have been working together with my students.
June 21, 2025 at 4:23 PM
There are many possible directions for building upon this work. I will highlight two on which I have been working together with my students.
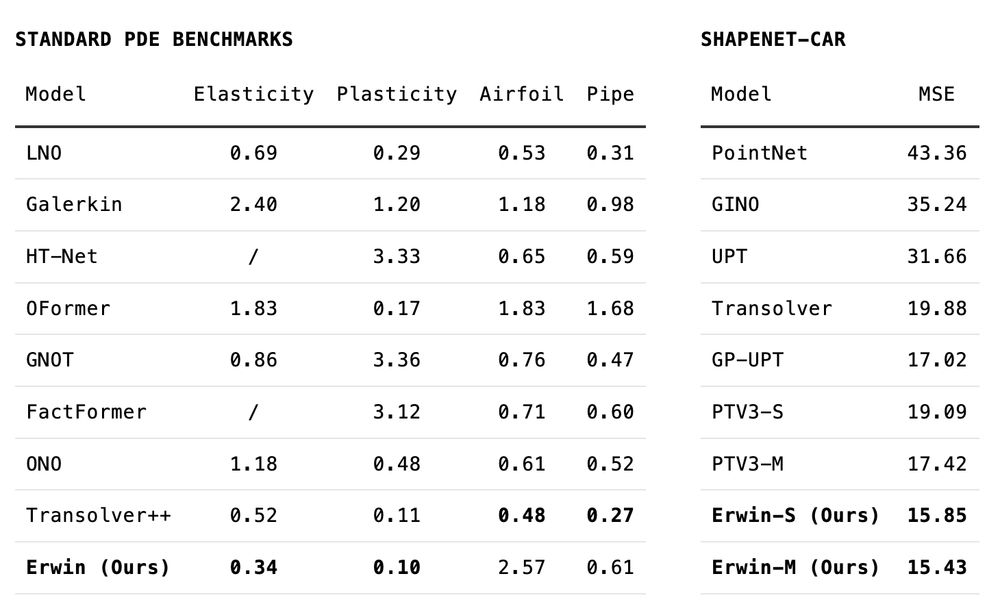
On top of the initial experiments in the first version of the paper, we include two more PDE-related benchmarks, where Erwin shows strong performance, achieving state-of-the-art on multiple tasks.
June 21, 2025 at 4:23 PM
On top of the initial experiments in the first version of the paper, we include two more PDE-related benchmarks, where Erwin shows strong performance, achieving state-of-the-art on multiple tasks.
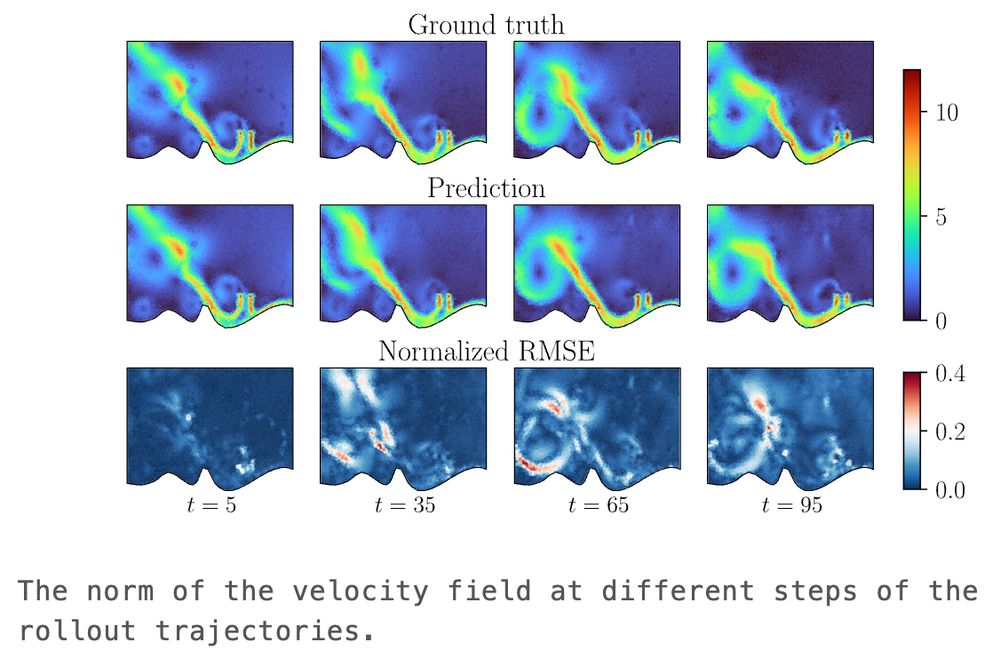
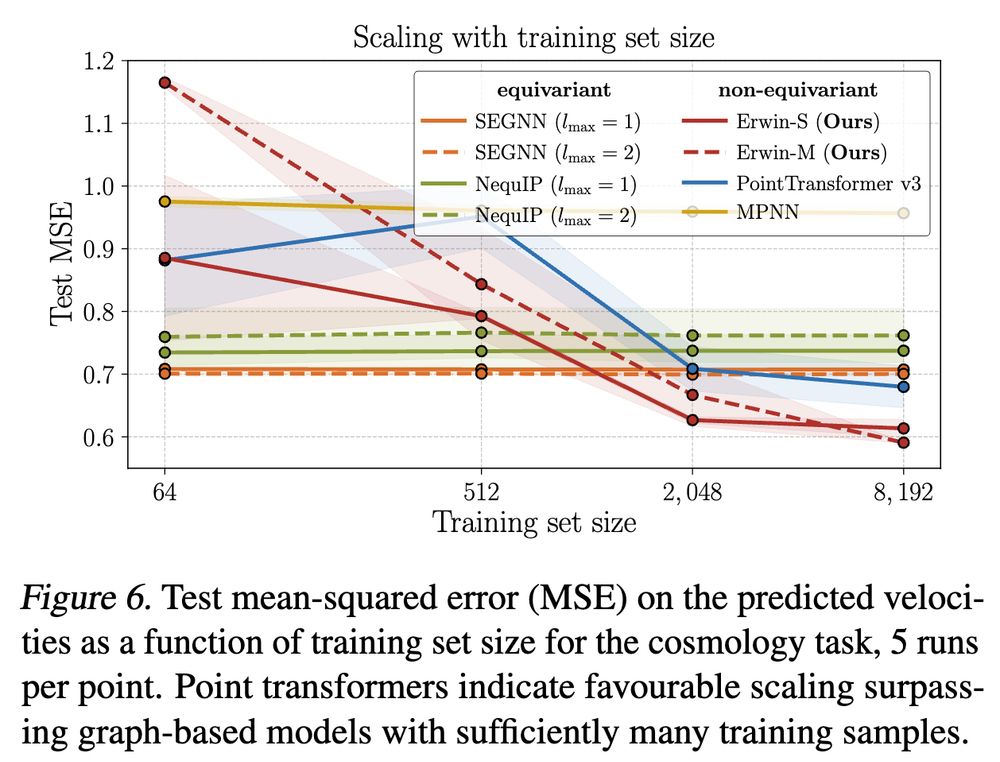
Original experiments: cosmology, molecular dynamics and turbulent fluid dynamics (EAGLE).
June 21, 2025 at 4:23 PM
Original experiments: cosmology, molecular dynamics and turbulent fluid dynamics (EAGLE).
Ball tree representation comes with a huge advantage of contiguous memory layout, making all operations extremely simple and efficient.

June 21, 2025 at 4:23 PM
Ball tree representation comes with a huge advantage of contiguous memory layout, making all operations extremely simple and efficient.
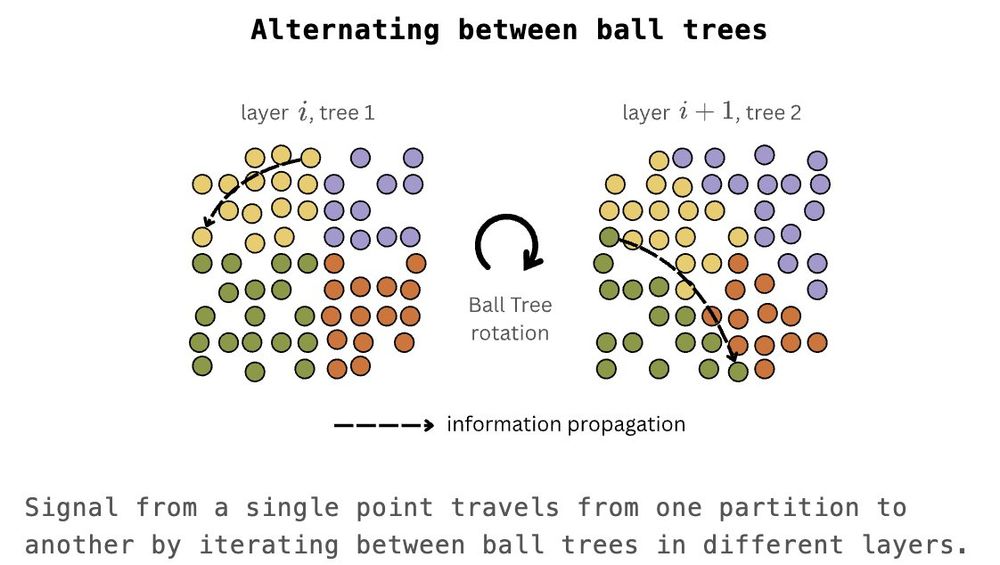
Implemented naively, however, the model will not be able to exchange information between partitions - and thus unable to capture global interactions.
To overcome this, we adapt the idea from the Swin Transformer, but instead of shifting windows, we rotate trees.
To overcome this, we adapt the idea from the Swin Transformer, but instead of shifting windows, we rotate trees.
June 21, 2025 at 4:23 PM
Implemented naively, however, the model will not be able to exchange information between partitions - and thus unable to capture global interactions.
To overcome this, we adapt the idea from the Swin Transformer, but instead of shifting windows, we rotate trees.
To overcome this, we adapt the idea from the Swin Transformer, but instead of shifting windows, we rotate trees.
For that reason, we impose a regular structure onto irregular data via ball trees.
That allows us to restrict attention computation to local partitions, reducing the cost to linear.
That allows us to restrict attention computation to local partitions, reducing the cost to linear.

June 21, 2025 at 4:23 PM
For that reason, we impose a regular structure onto irregular data via ball trees.
That allows us to restrict attention computation to local partitions, reducing the cost to linear.
That allows us to restrict attention computation to local partitions, reducing the cost to linear.
In the context of modeling large physical systems, this is critical, as the largest applications can include millions of points, which makes full attention unrealistic.
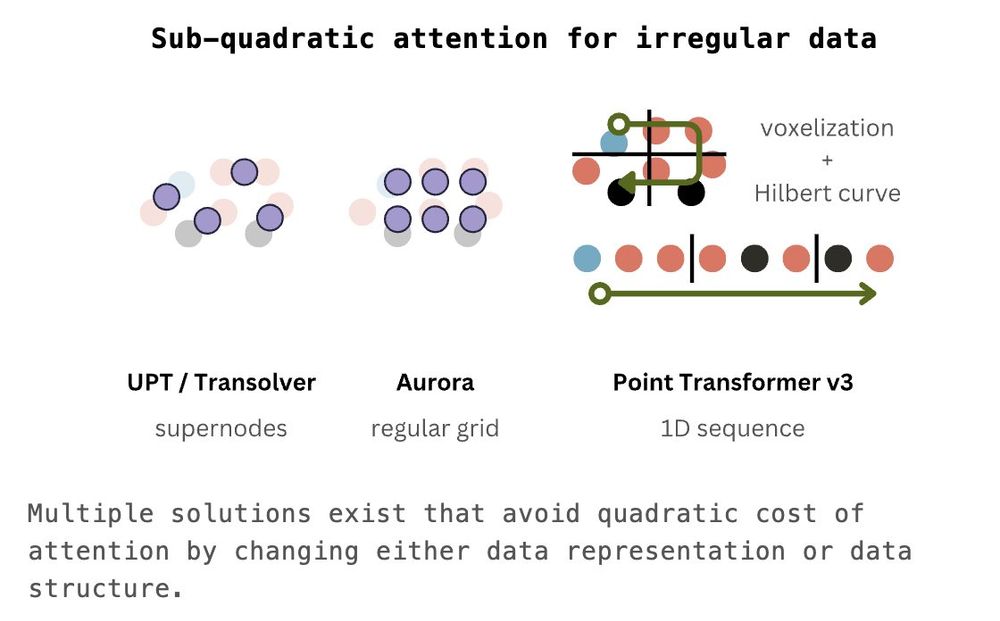
There are two ways: either change the data representation or the data structure.
There are two ways: either change the data representation or the data structure.
June 21, 2025 at 4:23 PM
In the context of modeling large physical systems, this is critical, as the largest applications can include millions of points, which makes full attention unrealistic.
There are two ways: either change the data representation or the data structure.
There are two ways: either change the data representation or the data structure.
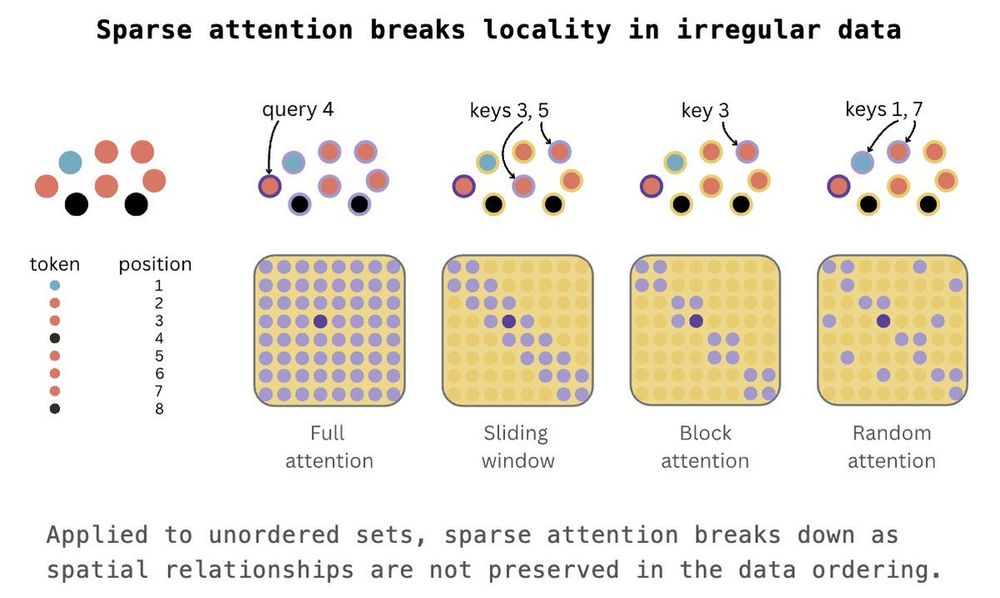
When it comes to irregular data, however, there is no natural ordering of points, hence standard sparse attention mechanisms break down as there is no guarantee that the locality they were based upon still exists.
June 21, 2025 at 4:23 PM
When it comes to irregular data, however, there is no natural ordering of points, hence standard sparse attention mechanisms break down as there is no guarantee that the locality they were based upon still exists.
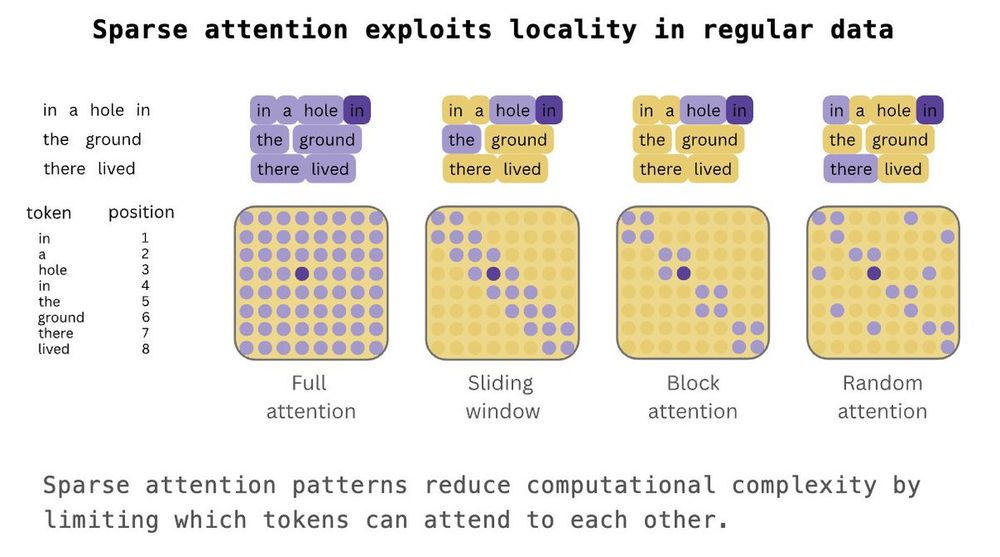
We start with sparse (sub-quadratic) attention coming in different flavors but all following the same idea - exploiting the regular structure of the data to model interactions between tokens.
June 21, 2025 at 4:23 PM
We start with sparse (sub-quadratic) attention coming in different flavors but all following the same idea - exploiting the regular structure of the data to model interactions between tokens.
🤹 New blog post!
I write about our recent work on using hierarchical trees to enable sparse attention over irregular data (point clouds, meshes) - Erwin Transformer, accepted to ICML 2025
blog: maxxxzdn.github.io/blog/erwin/
paper: arxiv.org/abs/2502.17019
Compressed version in the thread below:
I write about our recent work on using hierarchical trees to enable sparse attention over irregular data (point clouds, meshes) - Erwin Transformer, accepted to ICML 2025
blog: maxxxzdn.github.io/blog/erwin/
paper: arxiv.org/abs/2502.17019
Compressed version in the thread below:

June 21, 2025 at 4:23 PM
🤹 New blog post!
I write about our recent work on using hierarchical trees to enable sparse attention over irregular data (point clouds, meshes) - Erwin Transformer, accepted to ICML 2025
blog: maxxxzdn.github.io/blog/erwin/
paper: arxiv.org/abs/2502.17019
Compressed version in the thread below:
I write about our recent work on using hierarchical trees to enable sparse attention over irregular data (point clouds, meshes) - Erwin Transformer, accepted to ICML 2025
blog: maxxxzdn.github.io/blog/erwin/
paper: arxiv.org/abs/2502.17019
Compressed version in the thread below:
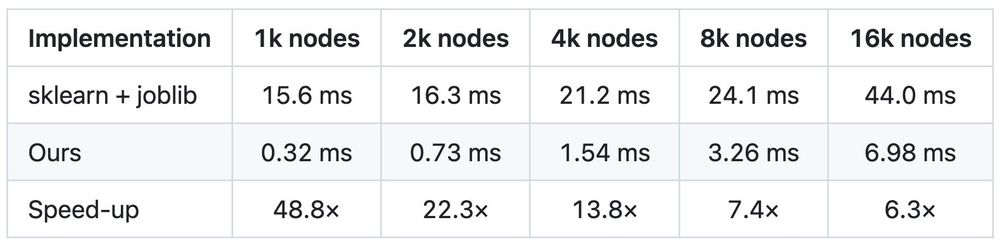
Bonus: to minimize the computational overhead of ball tree construction, we develop a fast, parallelized implementation in C++.
15/N
15/N
March 5, 2025 at 6:04 PM
Bonus: to minimize the computational overhead of ball tree construction, we develop a fast, parallelized implementation in C++.
15/N
15/N
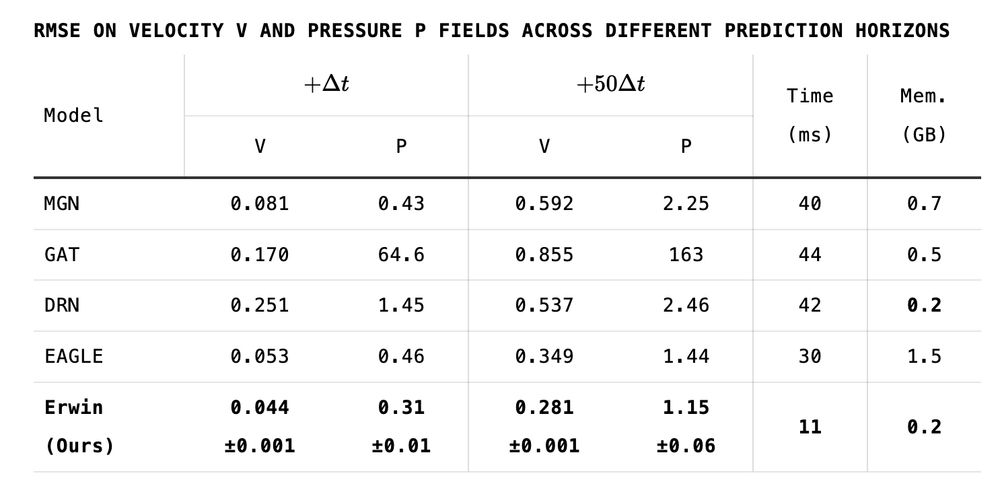
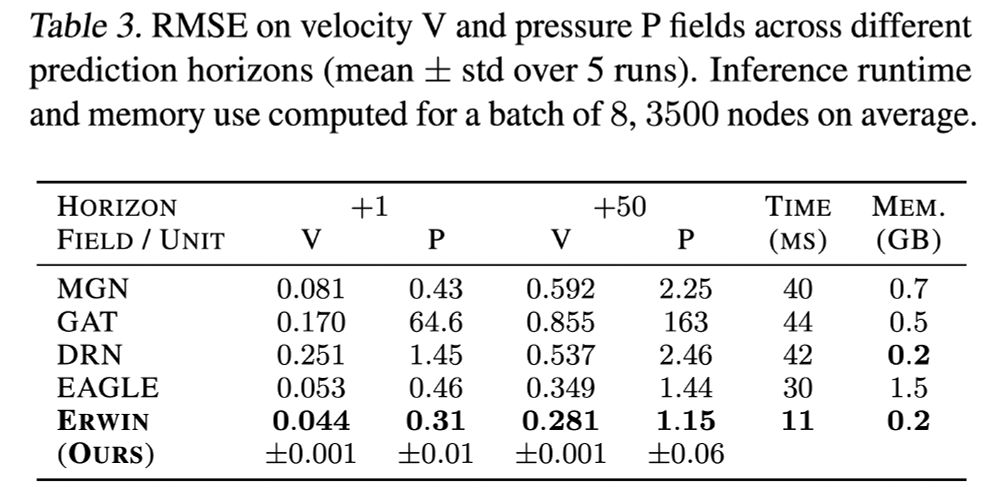
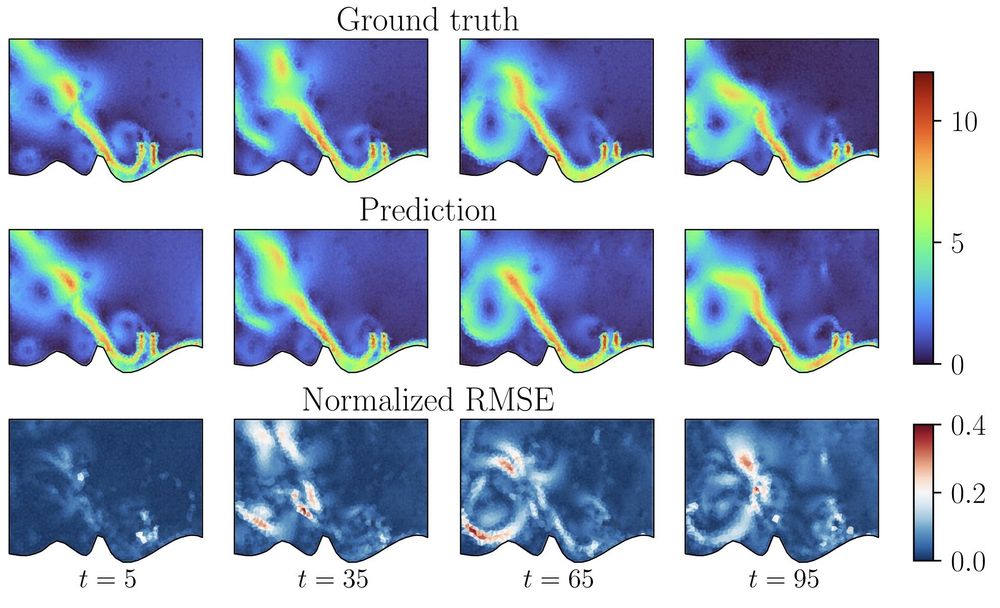
On the large-scale EAGLE benchmark (1M meshes, each with ~3500 nodes), we achieve SOTA performance in simulating unsteady fluid dynamics.
14/N
14/N
March 5, 2025 at 6:04 PM
On the large-scale EAGLE benchmark (1M meshes, each with ~3500 nodes), we achieve SOTA performance in simulating unsteady fluid dynamics.
14/N
14/N
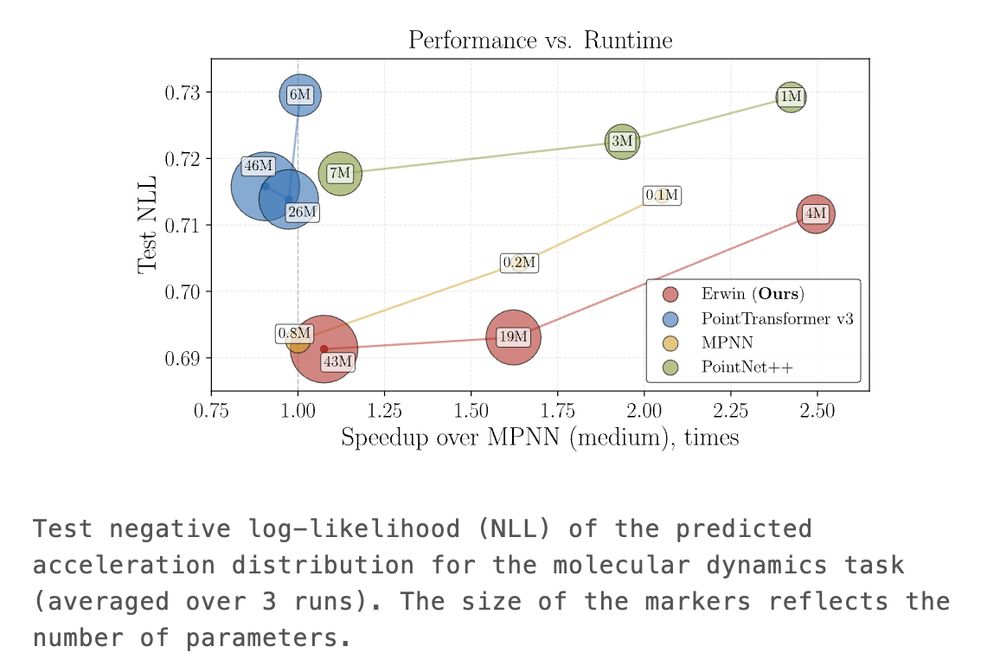
At the molecular dynamics task, Erwin pushes the Pareto frontier in performance vs runtime, proving to be a viable alternative to message-passing based architectures.
13/N
13/N
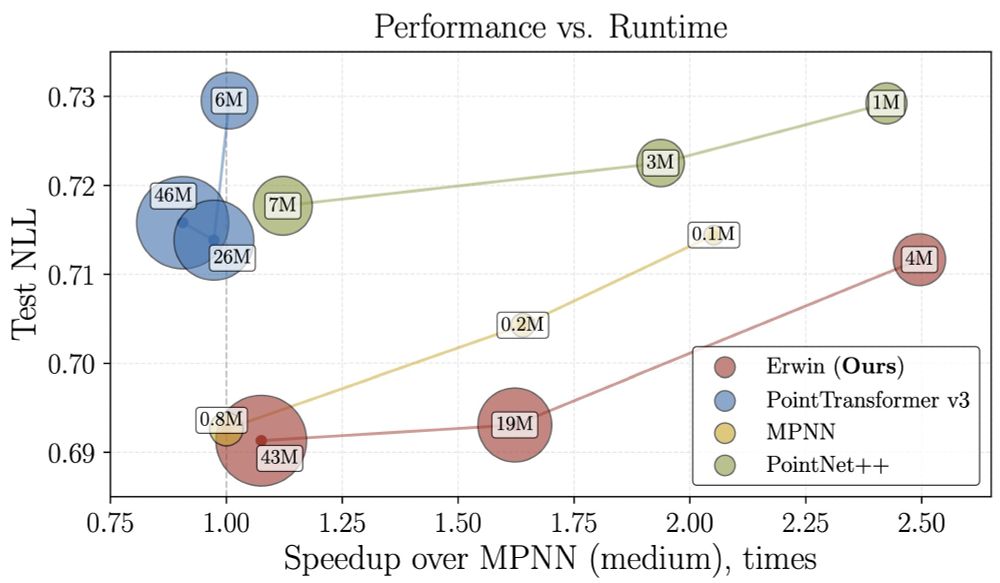
March 5, 2025 at 6:04 PM
At the molecular dynamics task, Erwin pushes the Pareto frontier in performance vs runtime, proving to be a viable alternative to message-passing based architectures.
13/N
13/N
The cosmological data exhibits long-range dependencies. As each point cloud is relatively large (5,000 points), this poses a challenge for message-passing models. Erwin, on the other hand, is able to capture those effects.
12/N
12/N
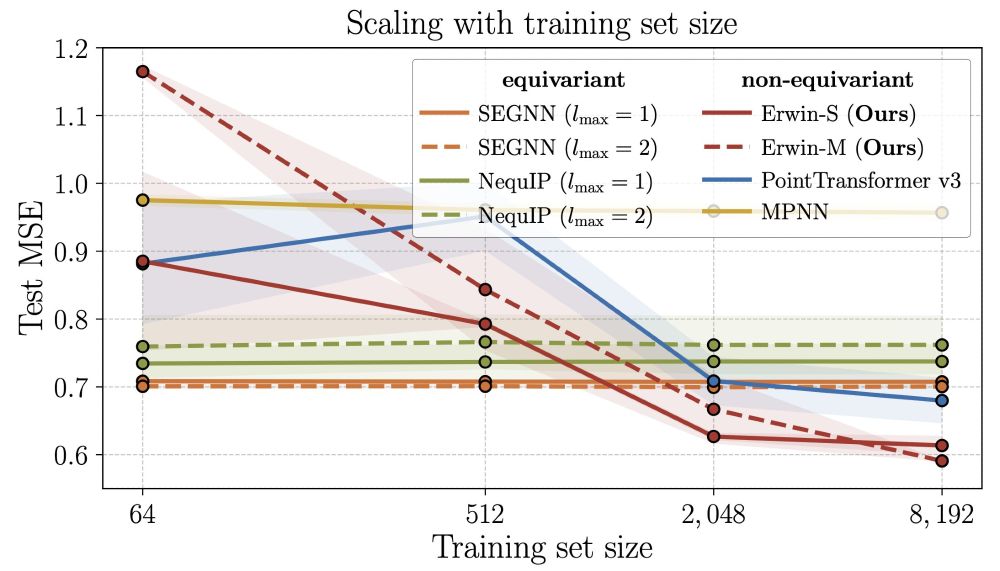
March 5, 2025 at 6:04 PM
The cosmological data exhibits long-range dependencies. As each point cloud is relatively large (5,000 points), this poses a challenge for message-passing models. Erwin, on the other hand, is able to capture those effects.
12/N
12/N
Due to the simplicity of implementation, Erwin is blazing fast. For a batch of 16 point clouds, 4096 points each, it only takes ~30 ms to compute the forward pass!
10/N
10/N
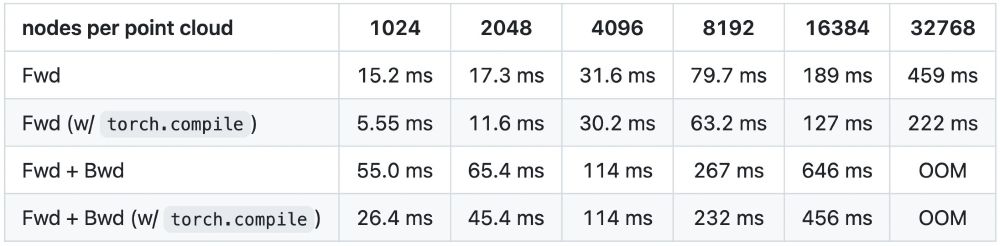
March 5, 2025 at 6:04 PM
Due to the simplicity of implementation, Erwin is blazing fast. For a batch of 16 point clouds, 4096 points each, it only takes ~30 ms to compute the forward pass!
10/N
10/N
The ball tree is stored in memory contiguously - at each level of the tree, points in the same ball are stored next to each other.
This property is critical and allows us to implement the key operations described above simply via .view() or .mean()!
9/N
This property is critical and allows us to implement the key operations described above simply via .view() or .mean()!
9/N

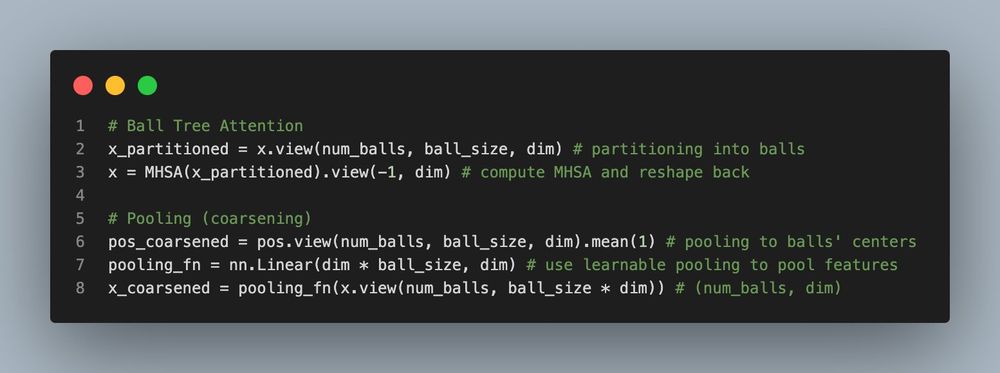
March 5, 2025 at 6:04 PM
The ball tree is stored in memory contiguously - at each level of the tree, points in the same ball are stored next to each other.
This property is critical and allows us to implement the key operations described above simply via .view() or .mean()!
9/N
This property is critical and allows us to implement the key operations described above simply via .view() or .mean()!
9/N
As Ball Tree Attention is local, we progressively coarsen and then refine the ball tree while keeping the ball size for attention fixed, following a U-Net-like architecture.
This allows us to learn multi-scale features and effectively increase the model's receptive field.
8/N
This allows us to learn multi-scale features and effectively increase the model's receptive field.
8/N
March 5, 2025 at 6:04 PM
As Ball Tree Attention is local, we progressively coarsen and then refine the ball tree while keeping the ball size for attention fixed, following a U-Net-like architecture.
This allows us to learn multi-scale features and effectively increase the model's receptive field.
8/N
This allows us to learn multi-scale features and effectively increase the model's receptive field.
8/N
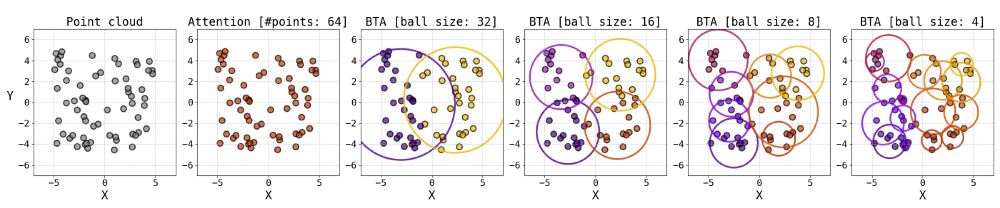
The main idea of the paper is to compute attention within the ball tree partitions.
Once the tree is built, one can choose the level of the tree and compute attention (Ball Tree Attention, BTA) within the balls in parallel.
7/N
Once the tree is built, one can choose the level of the tree and compute attention (Ball Tree Attention, BTA) within the balls in parallel.
7/N
March 5, 2025 at 6:04 PM
The main idea of the paper is to compute attention within the ball tree partitions.
Once the tree is built, one can choose the level of the tree and compute attention (Ball Tree Attention, BTA) within the balls in parallel.
7/N
Once the tree is built, one can choose the level of the tree and compute attention (Ball Tree Attention, BTA) within the balls in parallel.
7/N
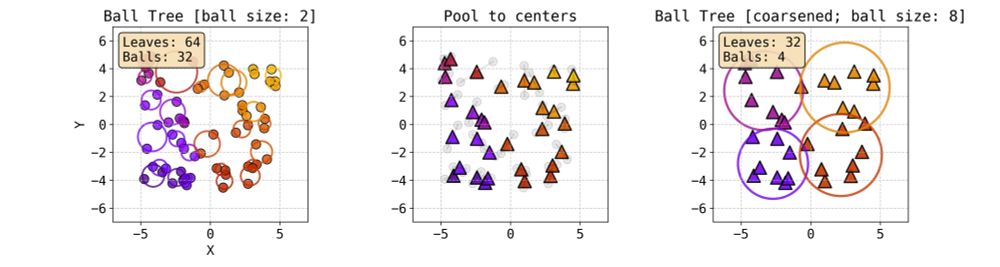
Erwin organizes the computation via a ball tree - a hierarchical data structure that recursively partitions points into nested sets of similar size, where each set is represented by a ball that covers all the points in the set.
6/N
6/N
March 5, 2025 at 6:04 PM
Erwin organizes the computation via a ball tree - a hierarchical data structure that recursively partitions points into nested sets of similar size, where each set is represented by a ball that covers all the points in the set.
6/N
6/N
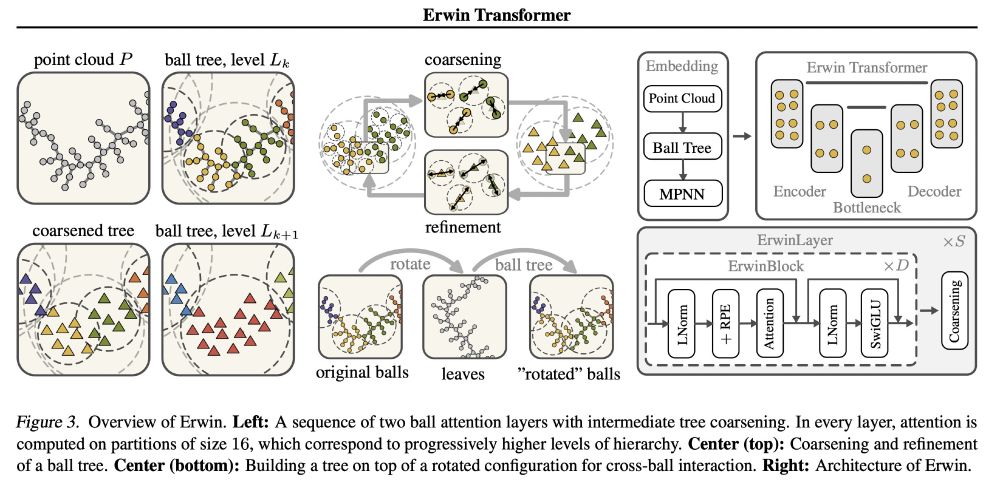
In this paper, we combine the scalability of tree-based algorithms and the efficiency of attention to build a transformer that:
- scales linearly with the number of points;
- captures global dependencies in data through hierarchical learning across multiple scales.
5/N
- scales linearly with the number of points;
- captures global dependencies in data through hierarchical learning across multiple scales.
5/N
March 5, 2025 at 6:04 PM
In this paper, we combine the scalability of tree-based algorithms and the efficiency of attention to build a transformer that:
- scales linearly with the number of points;
- captures global dependencies in data through hierarchical learning across multiple scales.
5/N
- scales linearly with the number of points;
- captures global dependencies in data through hierarchical learning across multiple scales.
5/N
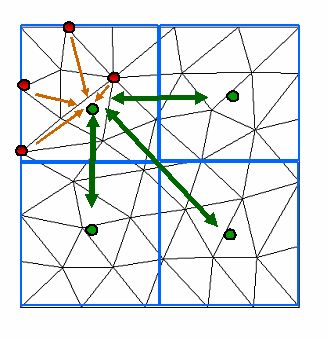
The problem was studied extensively in the 1980s in many-body physics.
To avoid the brute-force computation, tree-based algorithms were introduced that hierarchically organize particles, and the resolution of interactions depends on the distance between particles.
3/N
To avoid the brute-force computation, tree-based algorithms were introduced that hierarchically organize particles, and the resolution of interactions depends on the distance between particles.
3/N
March 5, 2025 at 6:04 PM
The problem was studied extensively in the 1980s in many-body physics.
To avoid the brute-force computation, tree-based algorithms were introduced that hierarchically organize particles, and the resolution of interactions depends on the distance between particles.
3/N
To avoid the brute-force computation, tree-based algorithms were introduced that hierarchically organize particles, and the resolution of interactions depends on the distance between particles.
3/N
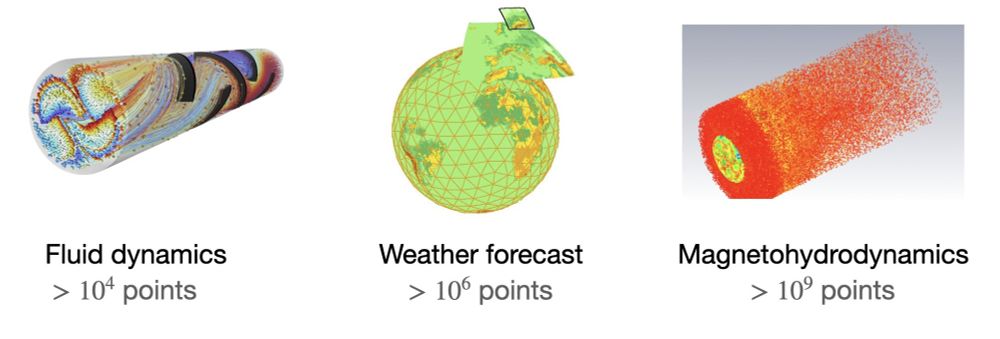
Physical systems with complex geometries are often represented using irregular meshes or point clouds.
These systems often exhibit long-range effects that are computationally challenging to model, as calculating all-to-all interactions scales quadratically with node count.
2/N
These systems often exhibit long-range effects that are computationally challenging to model, as calculating all-to-all interactions scales quadratically with node count.
2/N
March 5, 2025 at 6:04 PM
Physical systems with complex geometries are often represented using irregular meshes or point clouds.
These systems often exhibit long-range effects that are computationally challenging to model, as calculating all-to-all interactions scales quadratically with node count.
2/N
These systems often exhibit long-range effects that are computationally challenging to model, as calculating all-to-all interactions scales quadratically with node count.
2/N