



Kajetan Schweighofer
@kschweig.bsky.social
ELLIS PhD Student @ JKU supervised by Sepp Hochreiter
Working on Predictive Uncertainty in ML
Working on Predictive Uncertainty in ML
Reposted by Kajetan Schweighofer

TiRex 🦖 time series xLSTM model ranked #1 on all leaderboards.
➡️ Outperforms models by Amazon, Google, Datadog, Salesforce, Alibaba
➡️ industrial applications
➡️ limited data
➡️ embedded AI and edge devices
➡️ Europe is leading
Code: lnkd.in/eHXb-XwZ
Paper: lnkd.in/e8e7xnri
shorturl.at/jcQeq
➡️ Outperforms models by Amazon, Google, Datadog, Salesforce, Alibaba
➡️ industrial applications
➡️ limited data
➡️ embedded AI and edge devices
➡️ Europe is leading
Code: lnkd.in/eHXb-XwZ
Paper: lnkd.in/e8e7xnri
shorturl.at/jcQeq

Introducing TiRex - xLSTM based time series model | NXAI
TiRex model at the top 🦖
We are proud of TiRex - our first time series model based on #xLSTM technology.
Key take aways:
🥇 Ranked #1 on official international leaderboards
➡️ Outperforms models ...
www.linkedin.com
June 2, 2025 at 12:12 PM
TiRex 🦖 time series xLSTM model ranked #1 on all leaderboards.
➡️ Outperforms models by Amazon, Google, Datadog, Salesforce, Alibaba
➡️ industrial applications
➡️ limited data
➡️ embedded AI and edge devices
➡️ Europe is leading
Code: lnkd.in/eHXb-XwZ
Paper: lnkd.in/e8e7xnri
shorturl.at/jcQeq
➡️ Outperforms models by Amazon, Google, Datadog, Salesforce, Alibaba
➡️ industrial applications
➡️ limited data
➡️ embedded AI and edge devices
➡️ Europe is leading
Code: lnkd.in/eHXb-XwZ
Paper: lnkd.in/e8e7xnri
shorturl.at/jcQeq
Reposted by Kajetan Schweighofer

Happy to introduce 🔥LaM-SLidE🔥!
We show how trajectories of spatial dynamical systems can be modeled in latent space by
--> leveraging IDENTIFIERS.
📚Paper: arxiv.org/abs/2502.12128
💻Code: github.com/ml-jku/LaM-S...
📝Blog: ml-jku.github.io/LaM-SLidE/
1/n
We show how trajectories of spatial dynamical systems can be modeled in latent space by
--> leveraging IDENTIFIERS.
📚Paper: arxiv.org/abs/2502.12128
💻Code: github.com/ml-jku/LaM-S...
📝Blog: ml-jku.github.io/LaM-SLidE/
1/n

May 22, 2025 at 12:24 PM
Happy to introduce 🔥LaM-SLidE🔥!
We show how trajectories of spatial dynamical systems can be modeled in latent space by
--> leveraging IDENTIFIERS.
📚Paper: arxiv.org/abs/2502.12128
💻Code: github.com/ml-jku/LaM-S...
📝Blog: ml-jku.github.io/LaM-SLidE/
1/n
We show how trajectories of spatial dynamical systems can be modeled in latent space by
--> leveraging IDENTIFIERS.
📚Paper: arxiv.org/abs/2502.12128
💻Code: github.com/ml-jku/LaM-S...
📝Blog: ml-jku.github.io/LaM-SLidE/
1/n
Reposted by Kajetan Schweighofer

1/11 Excited to present our latest work "Scalable Discrete Diffusion Samplers: Combinatorial Optimization and Statistical Physics" at #ICLR2025 on Fri 25 Apr at 10 am!
#CombinatorialOptimization #StatisticalPhysics #DiffusionModels
#CombinatorialOptimization #StatisticalPhysics #DiffusionModels

April 24, 2025 at 8:57 AM
1/11 Excited to present our latest work "Scalable Discrete Diffusion Samplers: Combinatorial Optimization and Statistical Physics" at #ICLR2025 on Fri 25 Apr at 10 am!
#CombinatorialOptimization #StatisticalPhysics #DiffusionModels
#CombinatorialOptimization #StatisticalPhysics #DiffusionModels
Reposted by Kajetan Schweighofer

⚠️ Beware: Your AI assistant could be hijacked just by encountering a malicious image online!
Our latest research exposes critical security risks in AI assistants. An attacker can hijack them by simply posting an image on social media and waiting for it to be captured. [1/6] 🧵
Our latest research exposes critical security risks in AI assistants. An attacker can hijack them by simply posting an image on social media and waiting for it to be captured. [1/6] 🧵
March 18, 2025 at 6:25 PM
⚠️ Beware: Your AI assistant could be hijacked just by encountering a malicious image online!
Our latest research exposes critical security risks in AI assistants. An attacker can hijack them by simply posting an image on social media and waiting for it to be captured. [1/6] 🧵
Our latest research exposes critical security risks in AI assistants. An attacker can hijack them by simply posting an image on social media and waiting for it to be captured. [1/6] 🧵
Reposted by Kajetan Schweighofer
Exploration imitation learning architectures: Transformer, Mamba, xLSTM: arxiv.org/abs/2502.12330
*LIBERO: “xLSTM shows great potential”
*RoboCasa: “xLSTM models, we achieved success rate of 53.6%, compared to 40.0% of BC-Transformer”
*Point Clouds: “xLSTM model achieves a 60.9% success rate”
*LIBERO: “xLSTM shows great potential”
*RoboCasa: “xLSTM models, we achieved success rate of 53.6%, compared to 40.0% of BC-Transformer”
*Point Clouds: “xLSTM model achieves a 60.9% success rate”

X-IL: Exploring the Design Space of Imitation Learning Policies
Designing modern imitation learning (IL) policies requires making numerous decisions, including the selection of feature encoding, architecture, policy representation, and more. As the field rapidly a...
arxiv.org
February 19, 2025 at 7:43 PM
Exploration imitation learning architectures: Transformer, Mamba, xLSTM: arxiv.org/abs/2502.12330
*LIBERO: “xLSTM shows great potential”
*RoboCasa: “xLSTM models, we achieved success rate of 53.6%, compared to 40.0% of BC-Transformer”
*Point Clouds: “xLSTM model achieves a 60.9% success rate”
*LIBERO: “xLSTM shows great potential”
*RoboCasa: “xLSTM models, we achieved success rate of 53.6%, compared to 40.0% of BC-Transformer”
*Point Clouds: “xLSTM model achieves a 60.9% success rate”
Reposted by Kajetan Schweighofer

Ever wondered why presenting more facts can sometimes *worsen* disagreements, even among rational people? 🤔
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
January 7, 2025 at 10:25 PM
Ever wondered why presenting more facts can sometimes *worsen* disagreements, even among rational people? 🤔
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
Reposted by Kajetan Schweighofer
Often LLMs hallucinate because of semantic uncertainty due to missing factual training data. We propose a method to detect such uncertainties using only one generated output sequence. Super efficient method to detect hallucination in LLMs.
𝗡𝗲𝘄 𝗣𝗮𝗽𝗲𝗿 𝗔𝗹𝗲𝗿𝘁: Rethinking Uncertainty Estimation in Natural Language Generation 🌟
Introducing 𝗚-𝗡𝗟𝗟, a theoretically grounded and highly efficient uncertainty estimate, perfect for scalable LLM applications 🚀
Dive into the paper: arxiv.org/abs/2412.15176 👇
Introducing 𝗚-𝗡𝗟𝗟, a theoretically grounded and highly efficient uncertainty estimate, perfect for scalable LLM applications 🚀
Dive into the paper: arxiv.org/abs/2412.15176 👇

Rethinking Uncertainty Estimation in Natural Language Generation
Large Language Models (LLMs) are increasingly employed in real-world applications, driving the need to evaluate the trustworthiness of their generated text. To this end, reliable uncertainty estimatio...
arxiv.org
December 20, 2024 at 12:52 PM
Often LLMs hallucinate because of semantic uncertainty due to missing factual training data. We propose a method to detect such uncertainties using only one generated output sequence. Super efficient method to detect hallucination in LLMs.
Reposted by Kajetan Schweighofer
𝗡𝗲𝘄 𝗣𝗮𝗽𝗲𝗿 𝗔𝗹𝗲𝗿𝘁: Rethinking Uncertainty Estimation in Natural Language Generation 🌟
Introducing 𝗚-𝗡𝗟𝗟, a theoretically grounded and highly efficient uncertainty estimate, perfect for scalable LLM applications 🚀
Dive into the paper: arxiv.org/abs/2412.15176 👇
Introducing 𝗚-𝗡𝗟𝗟, a theoretically grounded and highly efficient uncertainty estimate, perfect for scalable LLM applications 🚀
Dive into the paper: arxiv.org/abs/2412.15176 👇
Rethinking Uncertainty Estimation in Natural Language Generation
Large Language Models (LLMs) are increasingly employed in real-world applications, driving the need to evaluate the trustworthiness of their generated text. To this end, reliable uncertainty estimatio...
arxiv.org
December 20, 2024 at 11:44 AM
𝗡𝗲𝘄 𝗣𝗮𝗽𝗲𝗿 𝗔𝗹𝗲𝗿𝘁: Rethinking Uncertainty Estimation in Natural Language Generation 🌟
Introducing 𝗚-𝗡𝗟𝗟, a theoretically grounded and highly efficient uncertainty estimate, perfect for scalable LLM applications 🚀
Dive into the paper: arxiv.org/abs/2412.15176 👇
Introducing 𝗚-𝗡𝗟𝗟, a theoretically grounded and highly efficient uncertainty estimate, perfect for scalable LLM applications 🚀
Dive into the paper: arxiv.org/abs/2412.15176 👇
Reposted by Kajetan Schweighofer

🔊 Super excited to announce the first ever Frontiers of Probabilistic Inference: Learning meets Sampling workshop at #ICLR2025 @iclr-conf.bsky.social!
🔗 website: sites.google.com/view/fpiwork...
🔥 Call for papers: sites.google.com/view/fpiwork...
more details in thread below👇 🧵
🔗 website: sites.google.com/view/fpiwork...
🔥 Call for papers: sites.google.com/view/fpiwork...
more details in thread below👇 🧵

December 18, 2024 at 7:09 PM
🔊 Super excited to announce the first ever Frontiers of Probabilistic Inference: Learning meets Sampling workshop at #ICLR2025 @iclr-conf.bsky.social!
🔗 website: sites.google.com/view/fpiwork...
🔥 Call for papers: sites.google.com/view/fpiwork...
more details in thread below👇 🧵
🔗 website: sites.google.com/view/fpiwork...
🔥 Call for papers: sites.google.com/view/fpiwork...
more details in thread below👇 🧵
Reposted by Kajetan Schweighofer

Just 10 days after o1's public debut, we’re thrilled to unveil the open-source version of the technique behind its success: scaling test-time compute
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!

December 16, 2024 at 9:42 PM
Just 10 days after o1's public debut, we’re thrilled to unveil the open-source version of the technique behind its success: scaling test-time compute
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!
Reposted by Kajetan Schweighofer

Proud to announce our NeurIPS spotlight, which was in the works for over a year now :) We dig into why decomposing aleatoric and epistemic uncertainty is hard, and what this means for the future of uncertainty quantification.
📖 arxiv.org/abs/2402.19460 🧵1/10
📖 arxiv.org/abs/2402.19460 🧵1/10
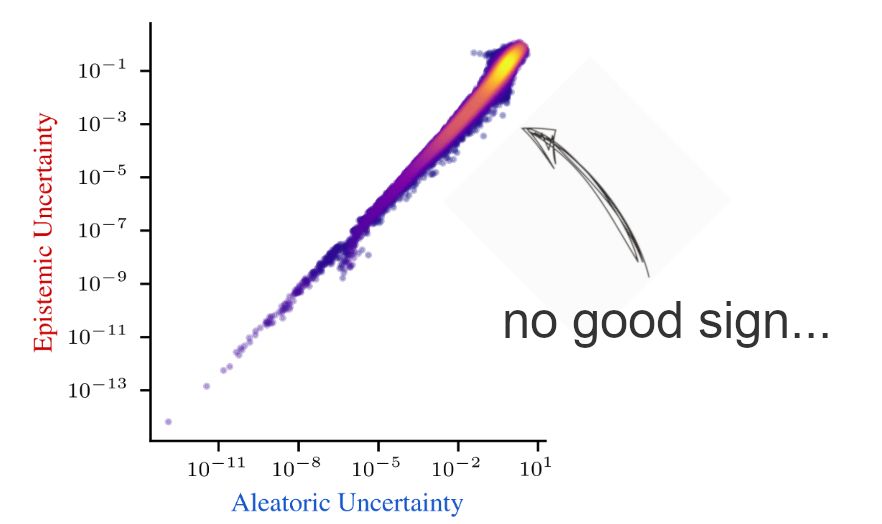
December 3, 2024 at 9:45 AM
Proud to announce our NeurIPS spotlight, which was in the works for over a year now :) We dig into why decomposing aleatoric and epistemic uncertainty is hard, and what this means for the future of uncertainty quantification.
📖 arxiv.org/abs/2402.19460 🧵1/10
📖 arxiv.org/abs/2402.19460 🧵1/10
Reposted by Kajetan Schweighofer

Thrilled to share our NeurIPS spotlight on uncertainty disentanglement! ✨ We study how well existing methods disentangle different sources of uncertainty, like epistemic and aleatoric. While all tested methods fail at this task, there are promising avenues ahead. 🧵 👇 1/7
📖: arxiv.org/abs/2402.19460
📖: arxiv.org/abs/2402.19460

December 3, 2024 at 1:38 PM
Thrilled to share our NeurIPS spotlight on uncertainty disentanglement! ✨ We study how well existing methods disentangle different sources of uncertainty, like epistemic and aleatoric. While all tested methods fail at this task, there are promising avenues ahead. 🧵 👇 1/7
📖: arxiv.org/abs/2402.19460
📖: arxiv.org/abs/2402.19460
Reposted by Kajetan Schweighofer

The Machine Learning for Molecules workshop 2024 will take place THIS FRIDAY, December 6.
Tickets for in-person participation are "SOLD" OUT.
We still have a few free tickets for online/virtual participation!
Registration link here: moleculediscovery.github.io/workshop2024/
Tickets for in-person participation are "SOLD" OUT.
We still have a few free tickets for online/virtual participation!
Registration link here: moleculediscovery.github.io/workshop2024/
ML for molecules and materials in the era of LLMs [ML4Molecules]
ELLIS workshop, HYBRID, December 6, 2024
moleculediscovery.github.io
December 3, 2024 at 12:35 PM
The Machine Learning for Molecules workshop 2024 will take place THIS FRIDAY, December 6.
Tickets for in-person participation are "SOLD" OUT.
We still have a few free tickets for online/virtual participation!
Registration link here: moleculediscovery.github.io/workshop2024/
Tickets for in-person participation are "SOLD" OUT.
We still have a few free tickets for online/virtual participation!
Registration link here: moleculediscovery.github.io/workshop2024/