


Jan-Thorsten Peter
@jtpeter.bsky.social
Reposted by Jan-Thorsten Peter

🥁Introducing Gemini 2.5, our most intelligent model with impressive capabilities in advanced reasoning and coding.
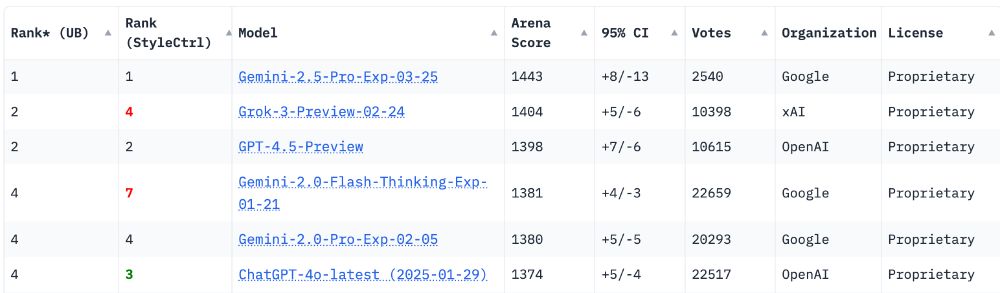
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇

March 25, 2025 at 5:25 PM
🥁Introducing Gemini 2.5, our most intelligent model with impressive capabilities in advanced reasoning and coding.
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
Reposted by Jan-Thorsten Peter

We've just released Gemma 3!!!
There was a lot of care and love in this launch
Check out the video
youtu.be/UU13FN2Xpyw?...
There was a lot of care and love in this launch
Check out the video
youtu.be/UU13FN2Xpyw?...

What’s new in Gemma 3?
YouTube video by Google for Developers
youtu.be
March 12, 2025 at 9:59 AM
We've just released Gemma 3!!!
There was a lot of care and love in this launch
Check out the video
youtu.be/UU13FN2Xpyw?...
There was a lot of care and love in this launch
Check out the video
youtu.be/UU13FN2Xpyw?...
Reposted by Jan-Thorsten Peter

Big news from WMT! 🎉 We are expanding beyond MT and launching a new multilingual instruction shared task. Our goal is to foster truly multilingual LLM evaluation and best practices in automatic and human evaluation. Join us and build the winning multilingual system!
www2.statmt.org/wmt25/multil...
www2.statmt.org/wmt25/multil...
Multilingual Instruction Shared Task
www2.statmt.org
March 11, 2025 at 6:26 PM
Big news from WMT! 🎉 We are expanding beyond MT and launching a new multilingual instruction shared task. Our goal is to foster truly multilingual LLM evaluation and best practices in automatic and human evaluation. Join us and build the winning multilingual system!
www2.statmt.org/wmt25/multil...
www2.statmt.org/wmt25/multil...
Reposted by Jan-Thorsten Peter

We're particularly proud to release Aya Vision 8B - it's compact 🐭 and efficient 🐎, outperforming models up to 11x its size 📈.
Releasing open weights helps to make breakthroughs in VLMs accessible to the research community.
Releasing open weights helps to make breakthroughs in VLMs accessible to the research community.

March 5, 2025 at 5:56 PM
We're particularly proud to release Aya Vision 8B - it's compact 🐭 and efficient 🐎, outperforming models up to 11x its size 📈.
Releasing open weights helps to make breakthroughs in VLMs accessible to the research community.
Releasing open weights helps to make breakthroughs in VLMs accessible to the research community.
Reposted by Jan-Thorsten Peter
Huge shoutout to colleagues at Google & Unbabel for extending our WMT24 testset to 55 languages in four domains, this is game changer! 🚀
I really hope it puts the final nail in the coffin of FLORES or WMT14. The field is evolving, legacy testsets can't show your progress
arxiv.org/abs/2502.124...
I really hope it puts the final nail in the coffin of FLORES or WMT14. The field is evolving, legacy testsets can't show your progress
arxiv.org/abs/2502.124...

WMT24++: Expanding the Language Coverage of WMT24 to 55 Languages & Dialects
As large language models (LLM) become more and more capable in languages other than English, it is important to collect benchmark datasets in order to evaluate their multilingual performance, includin...
arxiv.org
March 1, 2025 at 8:30 PM
Huge shoutout to colleagues at Google & Unbabel for extending our WMT24 testset to 55 languages in four domains, this is game changer! 🚀
I really hope it puts the final nail in the coffin of FLORES or WMT14. The field is evolving, legacy testsets can't show your progress
arxiv.org/abs/2502.124...
I really hope it puts the final nail in the coffin of FLORES or WMT14. The field is evolving, legacy testsets can't show your progress
arxiv.org/abs/2502.124...
Reposted by Jan-Thorsten Peter

😼SMOL DATA ALERT! 😼Anouncing SMOL, a professionally-translated dataset for 115 very low-resource languages! Paper: arxiv.org/pdf/2502.12301
Huggingface: huggingface.co/datasets/goo...
Huggingface: huggingface.co/datasets/goo...

February 19, 2025 at 5:36 PM
😼SMOL DATA ALERT! 😼Anouncing SMOL, a professionally-translated dataset for 115 very low-resource languages! Paper: arxiv.org/pdf/2502.12301
Huggingface: huggingface.co/datasets/goo...
Huggingface: huggingface.co/datasets/goo...