



Jonathan Berant
@jonathanberant.bsky.social
NLP at Tel Aviv Uni and Google DeepMind
Reposted by Jonathan Berant

With GDM friends Adam Fisch, @jonathanberant.bsky.social, Alekh Agarwal, and special guest Anastasios Angelopoulos.
June 10, 2025 at 3:24 PM
With GDM friends Adam Fisch, @jonathanberant.bsky.social, Alekh Agarwal, and special guest Anastasios Angelopoulos.
Reposted by Jonathan Berant
We offer cost-optimal policies for selecting which rater should annotate which examples, which link the cost, the annotation noise, and the *uncertainty* of the cheaper rater.
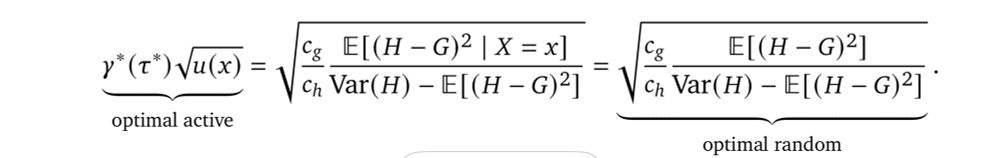
June 10, 2025 at 3:24 PM
We offer cost-optimal policies for selecting which rater should annotate which examples, which link the cost, the annotation noise, and the *uncertainty* of the cheaper rater.
Reposted by Jonathan Berant
Cheap but noisy?
Or accurate but expensive?
How to split a limited annotation budget between different types of judges?👩⚖️🤖🦧
www.arxiv.org/abs/2506.07949
Or accurate but expensive?
How to split a limited annotation budget between different types of judges?👩⚖️🤖🦧
www.arxiv.org/abs/2506.07949

Cost-Optimal Active AI Model Evaluation
The development lifecycle of generative AI systems requires continual evaluation, data acquisition, and annotation, which is costly in both resources and time. In practice, rapid iteration often makes...
www.arxiv.org
June 10, 2025 at 3:24 PM
Cheap but noisy?
Or accurate but expensive?
How to split a limited annotation budget between different types of judges?👩⚖️🤖🦧
www.arxiv.org/abs/2506.07949
Or accurate but expensive?
How to split a limited annotation budget between different types of judges?👩⚖️🤖🦧
www.arxiv.org/abs/2506.07949
Reposted by Jonathan Berant
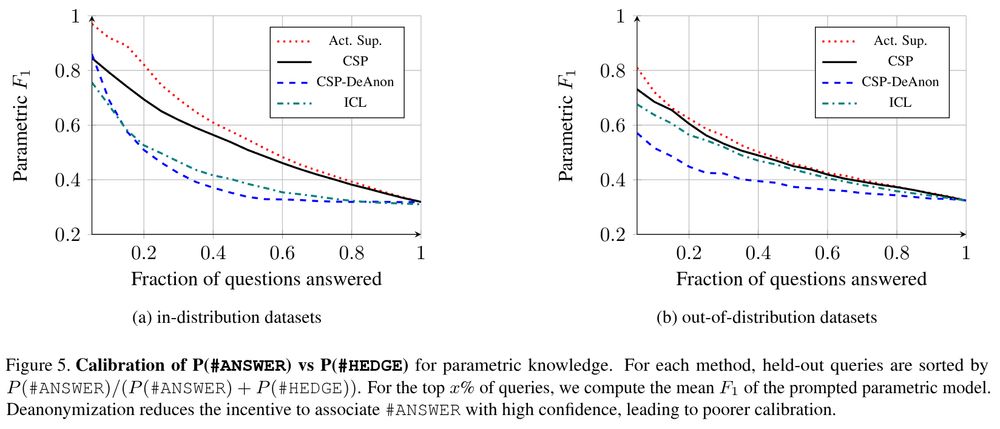
An ablation reveals the importance of mechanism design: when the helper identities are known to the asker during training (CSP-DeAnon), calibrated hedging is no longer learned.
March 24, 2025 at 3:39 PM
An ablation reveals the importance of mechanism design: when the helper identities are known to the asker during training (CSP-DeAnon), calibrated hedging is no longer learned.
Reposted by Jonathan Berant
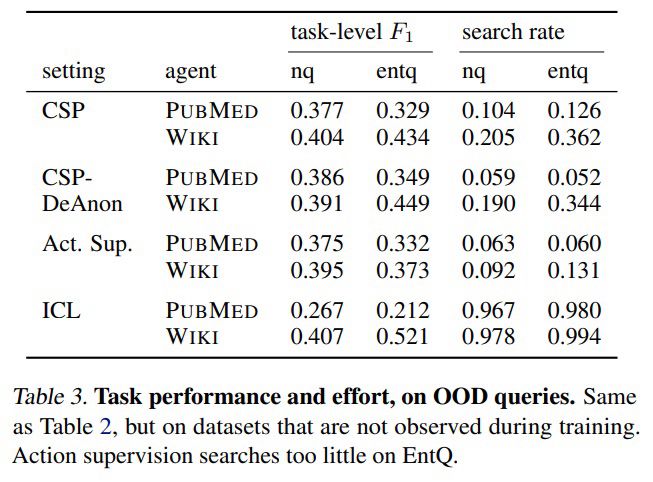
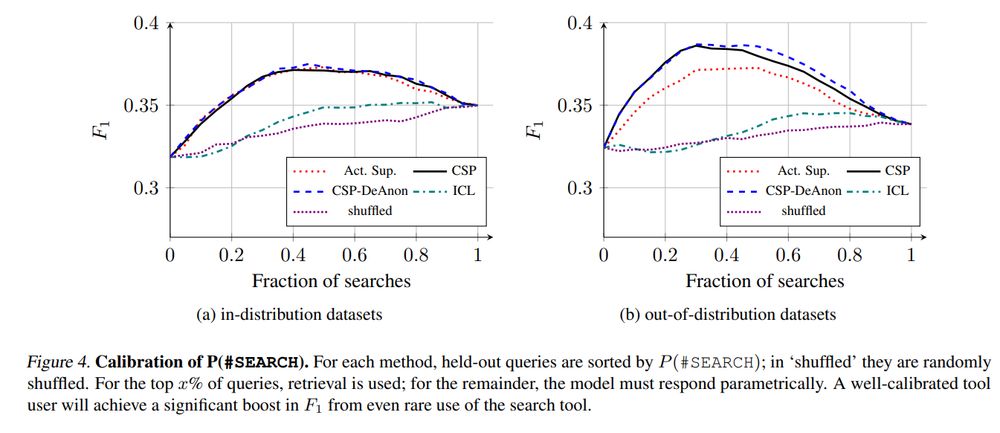
In practice, collaborative self-play + reinforced self-training (ReST) lead to improved task performance, better calibration of confidence markers, and more efficient tool use.
March 24, 2025 at 3:39 PM
In practice, collaborative self-play + reinforced self-training (ReST) lead to improved task performance, better calibration of confidence markers, and more efficient tool use.
Reposted by Jonathan Berant
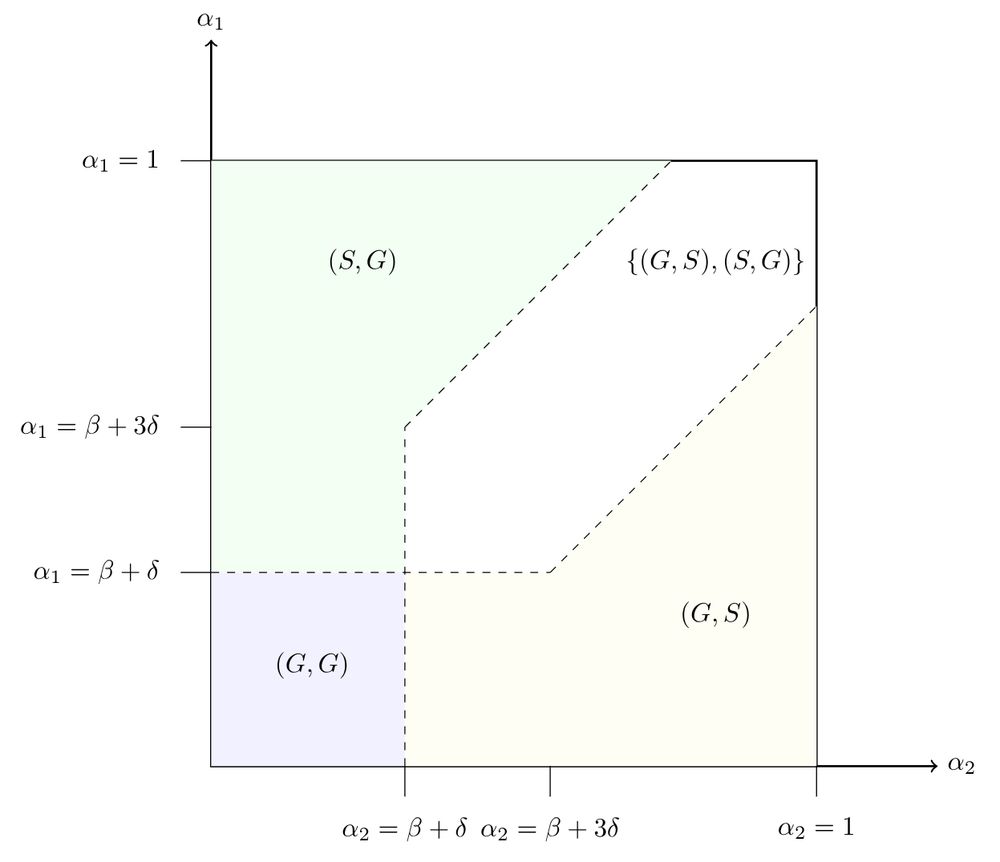
A bit of game theory can help explain when this can work: we model the setup as a game of public utility provision, where the public utility is the extra information provided by the costly retrieval action. The game has a unique equilibrium when the tools are sufficiently distinct (or both bad).
March 24, 2025 at 3:39 PM
A bit of game theory can help explain when this can work: we model the setup as a game of public utility provision, where the public utility is the extra information provided by the costly retrieval action. The game has a unique equilibrium when the tools are sufficiently distinct (or both bad).
Reposted by Jonathan Berant
Because the identity of each helper is hidden from the asker, it is forced to rely on confidence signals when faced with incompatible answers from the helpers. Maximizing effort-penalized accuracy of the full rollout can teach the LLM to use these confidence markers correctly.

March 24, 2025 at 3:39 PM
Because the identity of each helper is hidden from the asker, it is forced to rely on confidence signals when faced with incompatible answers from the helpers. Maximizing effort-penalized accuracy of the full rollout can teach the LLM to use these confidence markers correctly.
Reposted by Jonathan Berant
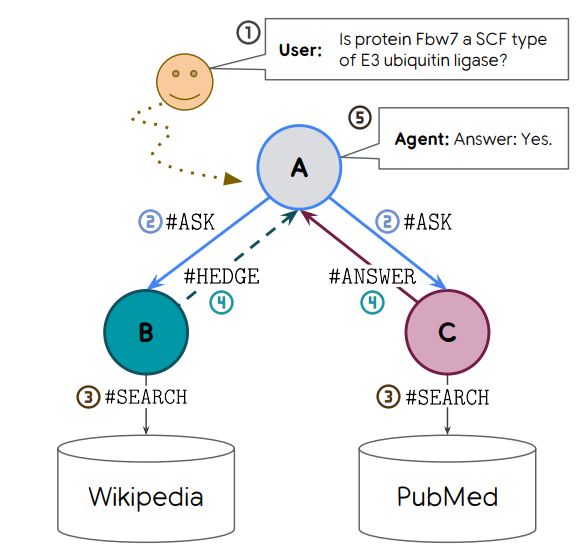
We focus on two capabilities: knowing when to use a costly retrieval tool, and hedging non-confident answers. To teach these capabilities, we create a small multi-agent society, in which two "helpers" can use specialized retrieval tools to pass information back to an "asker"
March 24, 2025 at 3:39 PM
We focus on two capabilities: knowing when to use a costly retrieval tool, and hedging non-confident answers. To teach these capabilities, we create a small multi-agent society, in which two "helpers" can use specialized retrieval tools to pass information back to an "asker"
Reposted by Jonathan Berant
We all want LLMs to collaborate with humans to help them achieve their goals. But LLMs are not trained to collaborate, they are trained to imitate. Can we teach LM agents to help humans by first making them help each other?
arxiv.org/abs/2503.14481
arxiv.org/abs/2503.14481
Don't lie to your friends: Learning what you know from collaborative self-play
To be helpful assistants, AI agents must be aware of their own capabilities and limitations. This includes knowing when to answer from parametric knowledge versus using tools, when to trust tool outpu...
arxiv.org
March 24, 2025 at 3:39 PM
We all want LLMs to collaborate with humans to help them achieve their goals. But LLMs are not trained to collaborate, they are trained to imitate. Can we teach LM agents to help humans by first making them help each other?
arxiv.org/abs/2503.14481
arxiv.org/abs/2503.14481
Reposted by Jonathan Berant

A way to help models "be aware of their own capabilities and limitations" from @jacobeisenstein.bsky.social et al: arxiv.org/abs/2503.14481 #MLSky

March 22, 2025 at 4:09 PM
A way to help models "be aware of their own capabilities and limitations" from @jacobeisenstein.bsky.social et al: arxiv.org/abs/2503.14481 #MLSky
Fun work led by @amouyalsamuel.bsky.social and with Aya. Coming in I didn't think LLMs should have difficulties with answering questions on some of the GP sentences we used, but turns out they had! See Samuel's thread for more info...
The old man the boat.
You probably had to read that sentence twice. It's because it's a garden path (GP) sentence. GP sentences are read slower and often misunderstood. This begs the questions:
1. Why are these sentences harder to process?
2. How do LLMs deal with them?
You probably had to read that sentence twice. It's because it's a garden path (GP) sentence. GP sentences are read slower and often misunderstood. This begs the questions:
1. Why are these sentences harder to process?
2. How do LLMs deal with them?
March 12, 2025 at 7:23 PM
Fun work led by @amouyalsamuel.bsky.social and with Aya. Coming in I didn't think LLMs should have difficulties with answering questions on some of the GP sentences we used, but turns out they had! See Samuel's thread for more info...
Reposted by Jonathan Berant

I had a lot of fun working on this with Aya Meltzer-Asscher and @jonathanberant.bsky.social .
We will soon release our materials, human results, LLM results and all the cool images the models produced on our sentences.
arxiv.org/abs/2502.09307
We will soon release our materials, human results, LLM results and all the cool images the models produced on our sentences.
arxiv.org/abs/2502.09307

When the LM misunderstood the human chuckled: Analyzing garden path effects in humans and language models
Modern Large Language Models (LLMs) have shown human-like abilities in many language tasks, sparking interest in comparing LLMs' and humans' language processing. In this paper, we conduct a detailed c...
arxiv.org
March 12, 2025 at 7:12 PM
I had a lot of fun working on this with Aya Meltzer-Asscher and @jonathanberant.bsky.social .
We will soon release our materials, human results, LLM results and all the cool images the models produced on our sentences.
arxiv.org/abs/2502.09307
We will soon release our materials, human results, LLM results and all the cool images the models produced on our sentences.
arxiv.org/abs/2502.09307
Reposted by Jonathan Berant
One intriguing follow-up: some component of the sentence understanding cognitive model fails on GP sentence. Is this component also present in LLMs? If not, then why so many LLMs are influenced by our manipulations in the same way humans are?

March 12, 2025 at 7:12 PM
One intriguing follow-up: some component of the sentence understanding cognitive model fails on GP sentence. Is this component also present in LLMs? If not, then why so many LLMs are influenced by our manipulations in the same way humans are?
Reposted by Jonathan Berant
There are many more cool insights you can find in our paper.
One takeaway from this paper for the psycholinguistics community: run your reading comprehension experiment on LLM first. You might get a general idea of the human results.
(Last image I swear)
One takeaway from this paper for the psycholinguistics community: run your reading comprehension experiment on LLM first. You might get a general idea of the human results.
(Last image I swear)

March 12, 2025 at 7:12 PM
There are many more cool insights you can find in our paper.
One takeaway from this paper for the psycholinguistics community: run your reading comprehension experiment on LLM first. You might get a general idea of the human results.
(Last image I swear)
One takeaway from this paper for the psycholinguistics community: run your reading comprehension experiment on LLM first. You might get a general idea of the human results.
(Last image I swear)
Reposted by Jonathan Berant
These experiments replicated the results from the sentence comprehension one: our manipulations had the same effect on the paraphrase or drawing correctness as they had on the sentence comprehension task.
In this image: While the teacher taught the puppies looked at the board.
In this image: While the teacher taught the puppies looked at the board.

March 12, 2025 at 7:12 PM
These experiments replicated the results from the sentence comprehension one: our manipulations had the same effect on the paraphrase or drawing correctness as they had on the sentence comprehension task.
In this image: While the teacher taught the puppies looked at the board.
In this image: While the teacher taught the puppies looked at the board.
Reposted by Jonathan Berant
We also ran two additional experiments with LLMs that are challenging to perform on humans.
1. We asked the LLM to paraphrase our sentence
2. We asked text-to-image models to draw the sentences
In this image: While the horse pulled the submarine moved silently.
1. We asked the LLM to paraphrase our sentence
2. We asked text-to-image models to draw the sentences
In this image: While the horse pulled the submarine moved silently.

March 12, 2025 at 7:12 PM
We also ran two additional experiments with LLMs that are challenging to perform on humans.
1. We asked the LLM to paraphrase our sentence
2. We asked text-to-image models to draw the sentences
In this image: While the horse pulled the submarine moved silently.
1. We asked the LLM to paraphrase our sentence
2. We asked text-to-image models to draw the sentences
In this image: While the horse pulled the submarine moved silently.
Reposted by Jonathan Berant
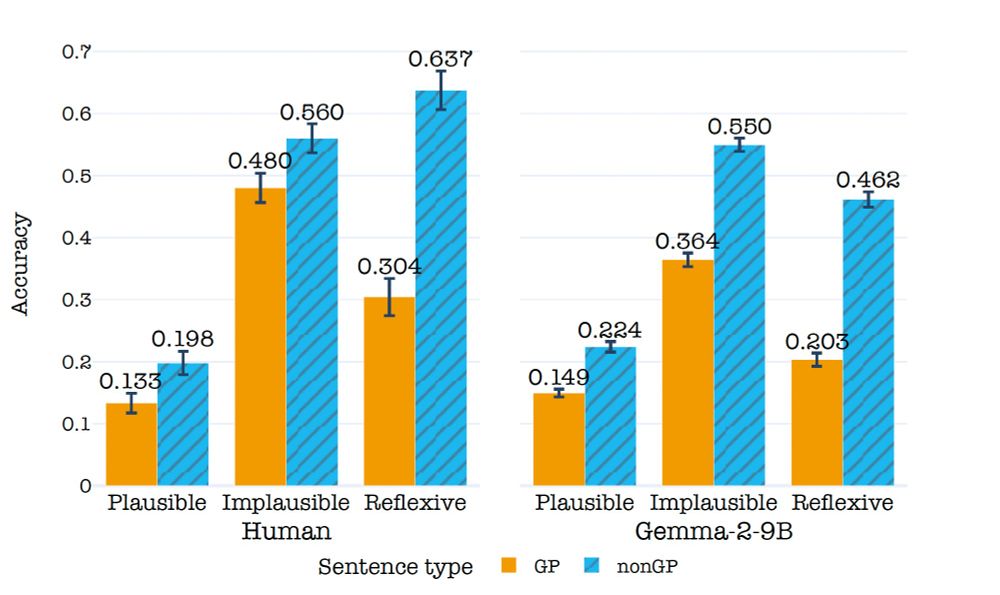
To answer our second question, we ran the same sentence comprehension experiment we ran on humans with over 60 LLMs.
We found that LLMs also struggle with GP sentences and that, interestingly, the manipulations we did to test our hypotheses impacted LLMs as they did with humans
We found that LLMs also struggle with GP sentences and that, interestingly, the manipulations we did to test our hypotheses impacted LLMs as they did with humans
March 12, 2025 at 7:12 PM
To answer our second question, we ran the same sentence comprehension experiment we ran on humans with over 60 LLMs.
We found that LLMs also struggle with GP sentences and that, interestingly, the manipulations we did to test our hypotheses impacted LLMs as they did with humans
We found that LLMs also struggle with GP sentences and that, interestingly, the manipulations we did to test our hypotheses impacted LLMs as they did with humans
Reposted by Jonathan Berant
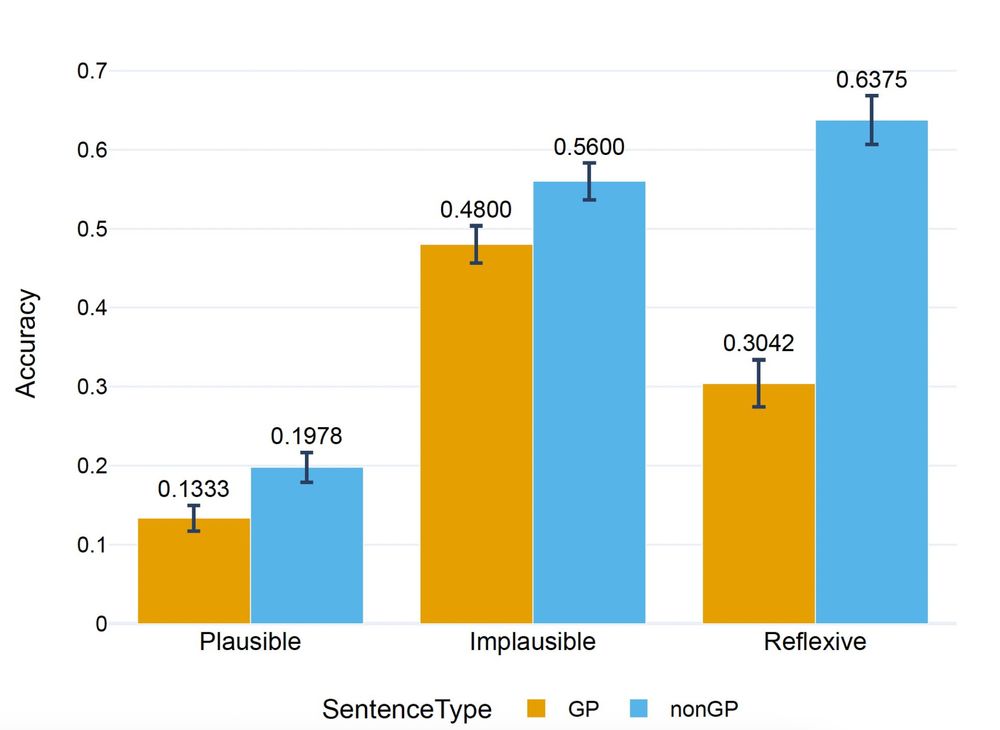
In our latest paper with Aya Meltzer-Asscher and @jonathanberant.bsky.social, we try to answer both these questions.
We devise hypotheses explaining why GP sentences are harder to process and test them. Human subjects answered a reading comprehension question about a sentence they read.
We devise hypotheses explaining why GP sentences are harder to process and test them. Human subjects answered a reading comprehension question about a sentence they read.
March 12, 2025 at 7:12 PM
In our latest paper with Aya Meltzer-Asscher and @jonathanberant.bsky.social, we try to answer both these questions.
We devise hypotheses explaining why GP sentences are harder to process and test them. Human subjects answered a reading comprehension question about a sentence they read.
We devise hypotheses explaining why GP sentences are harder to process and test them. Human subjects answered a reading comprehension question about a sentence they read.
Reposted by Jonathan Berant
The old man the boat.
You probably had to read that sentence twice. It's because it's a garden path (GP) sentence. GP sentences are read slower and often misunderstood. This begs the questions:
1. Why are these sentences harder to process?
2. How do LLMs deal with them?
You probably had to read that sentence twice. It's because it's a garden path (GP) sentence. GP sentences are read slower and often misunderstood. This begs the questions:
1. Why are these sentences harder to process?
2. How do LLMs deal with them?
March 12, 2025 at 7:12 PM
The old man the boat.
You probably had to read that sentence twice. It's because it's a garden path (GP) sentence. GP sentences are read slower and often misunderstood. This begs the questions:
1. Why are these sentences harder to process?
2. How do LLMs deal with them?
You probably had to read that sentence twice. It's because it's a garden path (GP) sentence. GP sentences are read slower and often misunderstood. This begs the questions:
1. Why are these sentences harder to process?
2. How do LLMs deal with them?
Reposted by Jonathan Berant

Inference-time procedures (e.g. Best-of-N, CoT) have been instrumental to recent development of LLMs. Standard RLHF focuses only on improving the trained model. This creates a train/inference mismatch.
𝘊𝘢𝘯 𝘸𝘦 𝘢𝘭𝘪𝘨𝘯 𝘰𝘶𝘳 𝘮𝘰𝘥𝘦𝘭 𝘵𝘰 𝘣𝘦𝘵𝘵𝘦𝘳 𝘴𝘶𝘪𝘵 𝘢 𝘨𝘪𝘷𝘦𝘯 𝘪𝘯𝘧𝘦𝘳𝘦𝘯𝘤𝘦-𝘵𝘪𝘮𝘦 𝘱𝘳𝘰𝘤𝘦𝘥𝘶𝘳𝘦?
Check out below.
𝘊𝘢𝘯 𝘸𝘦 𝘢𝘭𝘪𝘨𝘯 𝘰𝘶𝘳 𝘮𝘰𝘥𝘦𝘭 𝘵𝘰 𝘣𝘦𝘵𝘵𝘦𝘳 𝘴𝘶𝘪𝘵 𝘢 𝘨𝘪𝘷𝘦𝘯 𝘪𝘯𝘧𝘦𝘳𝘦𝘯𝘤𝘦-𝘵𝘪𝘮𝘦 𝘱𝘳𝘰𝘤𝘦𝘥𝘶𝘳𝘦?
Check out below.

February 11, 2025 at 4:27 PM
Inference-time procedures (e.g. Best-of-N, CoT) have been instrumental to recent development of LLMs. Standard RLHF focuses only on improving the trained model. This creates a train/inference mismatch.
𝘊𝘢𝘯 𝘸𝘦 𝘢𝘭𝘪𝘨𝘯 𝘰𝘶𝘳 𝘮𝘰𝘥𝘦𝘭 𝘵𝘰 𝘣𝘦𝘵𝘵𝘦𝘳 𝘴𝘶𝘪𝘵 𝘢 𝘨𝘪𝘷𝘦𝘯 𝘪𝘯𝘧𝘦𝘳𝘦𝘯𝘤𝘦-𝘵𝘪𝘮𝘦 𝘱𝘳𝘰𝘤𝘦𝘥𝘶𝘳𝘦?
Check out below.
𝘊𝘢𝘯 𝘸𝘦 𝘢𝘭𝘪𝘨𝘯 𝘰𝘶𝘳 𝘮𝘰𝘥𝘦𝘭 𝘵𝘰 𝘣𝘦𝘵𝘵𝘦𝘳 𝘴𝘶𝘪𝘵 𝘢 𝘨𝘪𝘷𝘦𝘯 𝘪𝘯𝘧𝘦𝘳𝘦𝘯𝘤𝘦-𝘵𝘪𝘮𝘦 𝘱𝘳𝘰𝘤𝘦𝘥𝘶𝘳𝘦?
Check out below.
Reposted by Jonathan Berant

Excited to share 𝐈𝐧𝐟𝐀𝐥𝐢𝐠𝐧!
Alignment optimization objective implicitly assumes 𝘴𝘢𝘮𝘱𝘭𝘪𝘯𝘨 from the resulting aligned model. But we are increasingly using different and sometimes sophisticated inference-time compute algorithms.
How to resolve this discrepancy?🧵
Alignment optimization objective implicitly assumes 𝘴𝘢𝘮𝘱𝘭𝘪𝘯𝘨 from the resulting aligned model. But we are increasingly using different and sometimes sophisticated inference-time compute algorithms.
How to resolve this discrepancy?🧵

January 1, 2025 at 7:59 PM
Excited to share 𝐈𝐧𝐟𝐀𝐥𝐢𝐠𝐧!
Alignment optimization objective implicitly assumes 𝘴𝘢𝘮𝘱𝘭𝘪𝘯𝘨 from the resulting aligned model. But we are increasingly using different and sometimes sophisticated inference-time compute algorithms.
How to resolve this discrepancy?🧵
Alignment optimization objective implicitly assumes 𝘴𝘢𝘮𝘱𝘭𝘪𝘯𝘨 from the resulting aligned model. But we are increasingly using different and sometimes sophisticated inference-time compute algorithms.
How to resolve this discrepancy?🧵
Reposted by Jonathan Berant

We’re really excited to release this large collaborative work for unifying web agent benchmarks under the same roof.
In this TMLR paper, we dive in-depth into #BrowserGym and #AgentLab. We also present some unexpected performances from Claude 3.5-Sonnet
In this TMLR paper, we dive in-depth into #BrowserGym and #AgentLab. We also present some unexpected performances from Claude 3.5-Sonnet

December 12, 2024 at 5:55 PM
We’re really excited to release this large collaborative work for unifying web agent benchmarks under the same roof.
In this TMLR paper, we dive in-depth into #BrowserGym and #AgentLab. We also present some unexpected performances from Claude 3.5-Sonnet
In this TMLR paper, we dive in-depth into #BrowserGym and #AgentLab. We also present some unexpected performances from Claude 3.5-Sonnet
I will also be at NeurIPS! Happy to chat about post-training, reasoning, and interesting ways you use multiple agents for things.
December 9, 2024 at 7:34 PM
I will also be at NeurIPS! Happy to chat about post-training, reasoning, and interesting ways you use multiple agents for things.
Reposted by Jonathan Berant
🧵-1
We are thrilled to release #AgentLab, a new open-source package for developing and evaluating web agents. This builds on the new #BrowserGym package which supports 10 different benchmarks, including #WebArena.
We are thrilled to release #AgentLab, a new open-source package for developing and evaluating web agents. This builds on the new #BrowserGym package which supports 10 different benchmarks, including #WebArena.

December 3, 2024 at 9:02 PM
🧵-1
We are thrilled to release #AgentLab, a new open-source package for developing and evaluating web agents. This builds on the new #BrowserGym package which supports 10 different benchmarks, including #WebArena.
We are thrilled to release #AgentLab, a new open-source package for developing and evaluating web agents. This builds on the new #BrowserGym package which supports 10 different benchmarks, including #WebArena.
Reposted by Jonathan Berant

I am seriously behind uploading Learning Machines videos, but I did want to get @jonathanberant.bsky.social's out sooner than later. It's not only a great talk, it also gives a remarkably broad overview and contextualization, so it's an excellent way to ramp up on post-training
youtu.be/2AthqCX3h8U
youtu.be/2AthqCX3h8U

Jonathan Berant (Tel Aviv University / Google) / Towards Robust Language Model Post-training
YouTube video by Yoav Artzi
youtu.be
December 2, 2024 at 3:45 AM
I am seriously behind uploading Learning Machines videos, but I did want to get @jonathanberant.bsky.social's out sooner than later. It's not only a great talk, it also gives a remarkably broad overview and contextualization, so it's an excellent way to ramp up on post-training
youtu.be/2AthqCX3h8U
youtu.be/2AthqCX3h8U