




Johann Brehmer
@johannbrehmer.bsky.social
Machine learner & physicist. At CuspAI, I teach machines to discover materials for carbon capture. Previously Qualcomm AI Research, NYU, Heidelberg U.
Thanks a lot, Guillaume!
December 16, 2024 at 5:28 PM
Thanks a lot, Guillaume!
If you're in Vancouver and want to chat about these papers, material discovery, or anything else, come by the posters or ping me!
6/6
6/6
December 11, 2024 at 5:15 AM
If you're in Vancouver and want to chat about these papers, material discovery, or anything else, come by the posters or ping me!
6/6
6/6
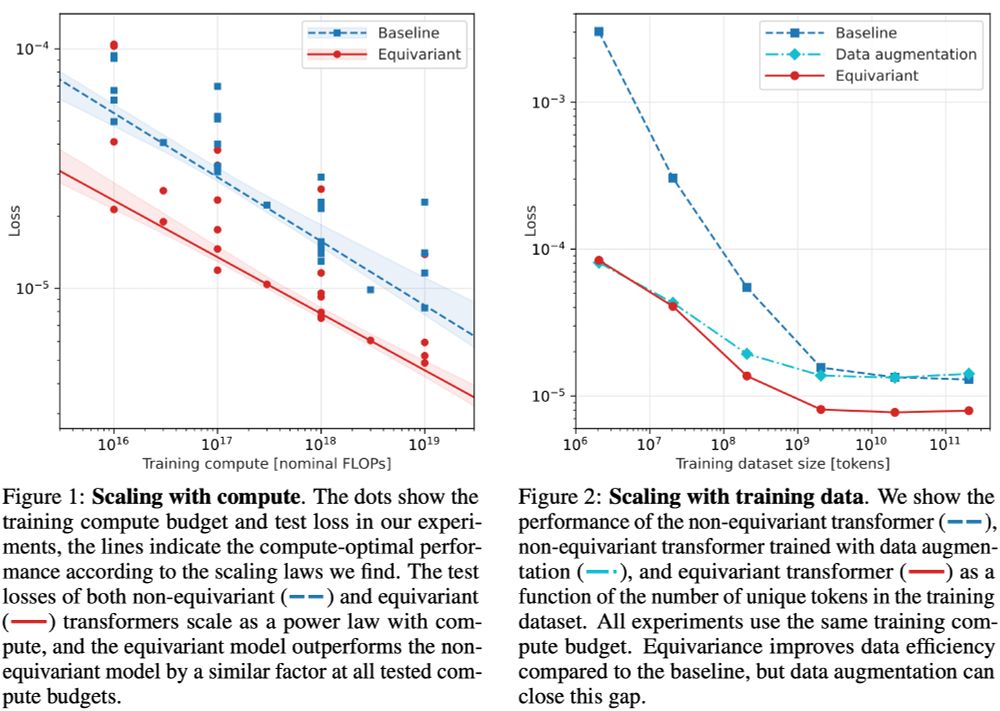
You might not be surprised to hear that equivariance improves data efficiency.
But did you expect equivariant models to also be more *compute*-efficient? Learning symmetries from data costs FLOPs!
arxiv.org/abs/2410.23179
With Sönke Behrends, @pimdh.bsky.social, and @taco-cohen.bsky.social.
5/6
But did you expect equivariant models to also be more *compute*-efficient? Learning symmetries from data costs FLOPs!
arxiv.org/abs/2410.23179
With Sönke Behrends, @pimdh.bsky.social, and @taco-cohen.bsky.social.
5/6
December 11, 2024 at 5:15 AM
You might not be surprised to hear that equivariance improves data efficiency.
But did you expect equivariant models to also be more *compute*-efficient? Learning symmetries from data costs FLOPs!
arxiv.org/abs/2410.23179
With Sönke Behrends, @pimdh.bsky.social, and @taco-cohen.bsky.social.
5/6
But did you expect equivariant models to also be more *compute*-efficient? Learning symmetries from data costs FLOPs!
arxiv.org/abs/2410.23179
With Sönke Behrends, @pimdh.bsky.social, and @taco-cohen.bsky.social.
5/6
On Saturday at 11:00 at the @neurreps.bsky.social workshop, I'll talk about our investigation into the relevance of equivariance at scale.
We studied empirically how equivariant and non-equivariant architectures scale as a function of training data, model size, and training steps.
4/6
We studied empirically how equivariant and non-equivariant architectures scale as a function of training data, model size, and training steps.
4/6
December 11, 2024 at 5:15 AM
On Saturday at 11:00 at the @neurreps.bsky.social workshop, I'll talk about our investigation into the relevance of equivariance at scale.
We studied empirically how equivariant and non-equivariant architectures scale as a function of training data, model size, and training steps.
4/6
We studied empirically how equivariant and non-equivariant architectures scale as a function of training data, model size, and training steps.
4/6
Combining L-GATr with Riemannian flow matching, they also constructed the first Lorentz-equivariant generative model.
arxiv.org/abs/2405.14806
With @jonasspinner.bsky.social, Victor Bresó, @pimdh.bsky.social, Tilman Plehn, and Jesse Thaler.
3/6
arxiv.org/abs/2405.14806
With @jonasspinner.bsky.social, Victor Bresó, @pimdh.bsky.social, Tilman Plehn, and Jesse Thaler.
3/6

December 11, 2024 at 5:15 AM
Combining L-GATr with Riemannian flow matching, they also constructed the first Lorentz-equivariant generative model.
arxiv.org/abs/2405.14806
With @jonasspinner.bsky.social, Victor Bresó, @pimdh.bsky.social, Tilman Plehn, and Jesse Thaler.
3/6
arxiv.org/abs/2405.14806
With @jonasspinner.bsky.social, Victor Bresó, @pimdh.bsky.social, Tilman Plehn, and Jesse Thaler.
3/6
On Thursday from 11:00 to 14:00, I'll be cheering on @jonasspinner.bsky.social and Victor Bresó at poster 3911.
They built L-GATr 🐊: a transformer that's equivariant to the Lorentz symmetry of special relativity. It performs remarkably well across different tasks in high-energy physics.
2/6
They built L-GATr 🐊: a transformer that's equivariant to the Lorentz symmetry of special relativity. It performs remarkably well across different tasks in high-energy physics.
2/6

December 11, 2024 at 5:15 AM
On Thursday from 11:00 to 14:00, I'll be cheering on @jonasspinner.bsky.social and Victor Bresó at poster 3911.
They built L-GATr 🐊: a transformer that's equivariant to the Lorentz symmetry of special relativity. It performs remarkably well across different tasks in high-energy physics.
2/6
They built L-GATr 🐊: a transformer that's equivariant to the Lorentz symmetry of special relativity. It performs remarkably well across different tasks in high-energy physics.
2/6
Would love to be on the list as well, thanks!
November 20, 2024 at 8:21 PM
Would love to be on the list as well, thanks!
Oops, sorry and thanks!
November 19, 2024 at 9:12 AM
Oops, sorry and thanks!
It's been a while, but I still like SBI — can you add me, too?
November 19, 2024 at 7:38 AM
It's been a while, but I still like SBI — can you add me, too?
Great list! Would love to join.
November 16, 2024 at 7:57 AM
Great list! Would love to join.