




Johann Brehmer
@johannbrehmer.bsky.social
Machine learner & physicist. At CuspAI, I teach machines to discover materials for carbon capture. Previously Qualcomm AI Research, NYU, Heidelberg U.
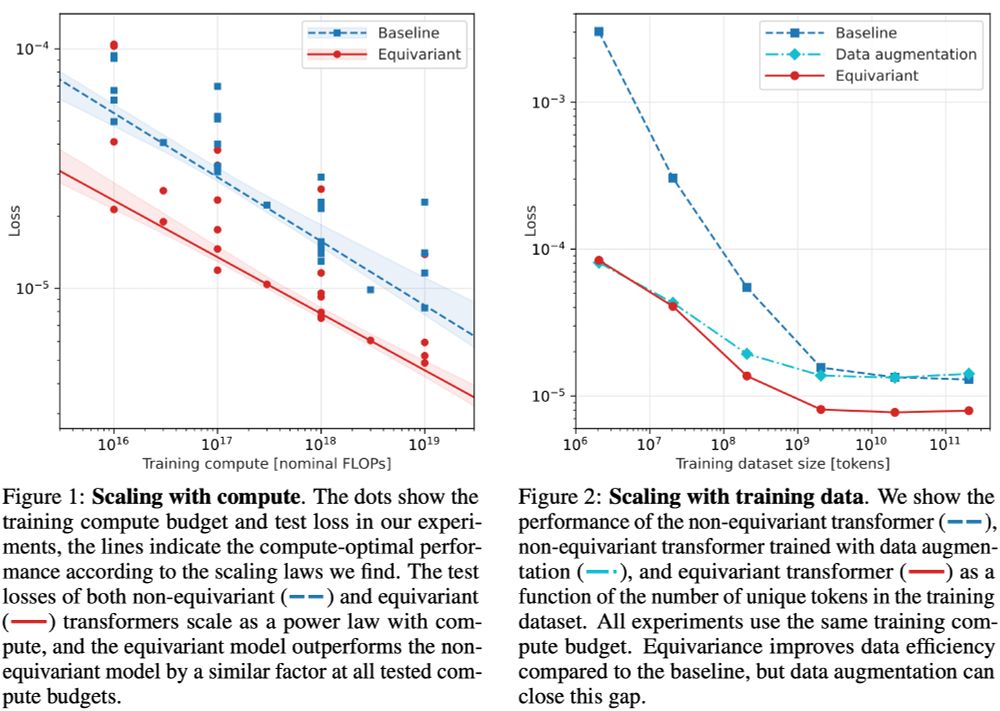
You might not be surprised to hear that equivariance improves data efficiency.
But did you expect equivariant models to also be more *compute*-efficient? Learning symmetries from data costs FLOPs!
arxiv.org/abs/2410.23179
With Sönke Behrends, @pimdh.bsky.social, and @taco-cohen.bsky.social.
5/6
But did you expect equivariant models to also be more *compute*-efficient? Learning symmetries from data costs FLOPs!
arxiv.org/abs/2410.23179
With Sönke Behrends, @pimdh.bsky.social, and @taco-cohen.bsky.social.
5/6
December 11, 2024 at 5:15 AM
You might not be surprised to hear that equivariance improves data efficiency.
But did you expect equivariant models to also be more *compute*-efficient? Learning symmetries from data costs FLOPs!
arxiv.org/abs/2410.23179
With Sönke Behrends, @pimdh.bsky.social, and @taco-cohen.bsky.social.
5/6
But did you expect equivariant models to also be more *compute*-efficient? Learning symmetries from data costs FLOPs!
arxiv.org/abs/2410.23179
With Sönke Behrends, @pimdh.bsky.social, and @taco-cohen.bsky.social.
5/6
Combining L-GATr with Riemannian flow matching, they also constructed the first Lorentz-equivariant generative model.
arxiv.org/abs/2405.14806
With @jonasspinner.bsky.social, Victor Bresó, @pimdh.bsky.social, Tilman Plehn, and Jesse Thaler.
3/6
arxiv.org/abs/2405.14806
With @jonasspinner.bsky.social, Victor Bresó, @pimdh.bsky.social, Tilman Plehn, and Jesse Thaler.
3/6

December 11, 2024 at 5:15 AM
Combining L-GATr with Riemannian flow matching, they also constructed the first Lorentz-equivariant generative model.
arxiv.org/abs/2405.14806
With @jonasspinner.bsky.social, Victor Bresó, @pimdh.bsky.social, Tilman Plehn, and Jesse Thaler.
3/6
arxiv.org/abs/2405.14806
With @jonasspinner.bsky.social, Victor Bresó, @pimdh.bsky.social, Tilman Plehn, and Jesse Thaler.
3/6
On Thursday from 11:00 to 14:00, I'll be cheering on @jonasspinner.bsky.social and Victor Bresó at poster 3911.
They built L-GATr 🐊: a transformer that's equivariant to the Lorentz symmetry of special relativity. It performs remarkably well across different tasks in high-energy physics.
2/6
They built L-GATr 🐊: a transformer that's equivariant to the Lorentz symmetry of special relativity. It performs remarkably well across different tasks in high-energy physics.
2/6

December 11, 2024 at 5:15 AM
On Thursday from 11:00 to 14:00, I'll be cheering on @jonasspinner.bsky.social and Victor Bresó at poster 3911.
They built L-GATr 🐊: a transformer that's equivariant to the Lorentz symmetry of special relativity. It performs remarkably well across different tasks in high-energy physics.
2/6
They built L-GATr 🐊: a transformer that's equivariant to the Lorentz symmetry of special relativity. It performs remarkably well across different tasks in high-energy physics.
2/6