



Jatin Ganhotra
@jatinganhotra.dev
Researcher at @IBMResearch #NLProc #ConvAI #Agents #SWE-Agent || RTs ≠ endorsements. Views personal, not of employers/institutions.
jatinganhotra.dev swebencharena.com
jatinganhotra.dev swebencharena.com
4/4 Ready to see how AI really stacks up against human developers?
Join researchers and developers already evaluating patches → swebencharena.com
#AI #SoftwareEngineering #CodeQuality #AIEvaluation #SWEBenchArena
Join researchers and developers already evaluating patches → swebencharena.com
#AI #SoftwareEngineering #CodeQuality #AIEvaluation #SWEBenchArena
September 15, 2025 at 4:06 AM
4/4 Ready to see how AI really stacks up against human developers?
Join researchers and developers already evaluating patches → swebencharena.com
#AI #SoftwareEngineering #CodeQuality #AIEvaluation #SWEBenchArena
Join researchers and developers already evaluating patches → swebencharena.com
#AI #SoftwareEngineering #CodeQuality #AIEvaluation #SWEBenchArena
3/4 Unlike other platforms:
🚫 PR Arena: Tracks merge rates, not code quality
🚫 Yupp AI: Known models, not blind
🚫 SWE Arena: General coding, not SWE tasks
✅ SWE-Bench-Arena: Blind quality evaluation of real bug fixes
🚫 PR Arena: Tracks merge rates, not code quality
🚫 Yupp AI: Known models, not blind
🚫 SWE Arena: General coding, not SWE tasks
✅ SWE-Bench-Arena: Blind quality evaluation of real bug fixes
September 15, 2025 at 4:06 AM
3/4 Unlike other platforms:
🚫 PR Arena: Tracks merge rates, not code quality
🚫 Yupp AI: Known models, not blind
🚫 SWE Arena: General coding, not SWE tasks
✅ SWE-Bench-Arena: Blind quality evaluation of real bug fixes
🚫 PR Arena: Tracks merge rates, not code quality
🚫 Yupp AI: Known models, not blind
🚫 SWE Arena: General coding, not SWE tasks
✅ SWE-Bench-Arena: Blind quality evaluation of real bug fixes
2/4 SWE-Bench-Arena fills this gap with blind evaluation across 5 dimensions:
• Simplicity
• Readability
• Performance
• Maintainability
• Correctness
No bias. Just quality assessment.
• Simplicity
• Readability
• Performance
• Maintainability
• Correctness
No bias. Just quality assessment.
September 15, 2025 at 4:06 AM
2/4 SWE-Bench-Arena fills this gap with blind evaluation across 5 dimensions:
• Simplicity
• Readability
• Performance
• Maintainability
• Correctness
No bias. Just quality assessment.
• Simplicity
• Readability
• Performance
• Maintainability
• Correctness
No bias. Just quality assessment.
Try evaluating patches → swebencharena.com
What quality issues have you noticed with AI-generated code?
#AIEvaluation #SWEBenchArena #CodeQuality #AI #SoftwareEngineering
What quality issues have you noticed with AI-generated code?
#AIEvaluation #SWEBenchArena #CodeQuality #AI #SoftwareEngineering
September 4, 2025 at 3:01 AM
Try evaluating patches → swebencharena.com
What quality issues have you noticed with AI-generated code?
#AIEvaluation #SWEBenchArena #CodeQuality #AI #SoftwareEngineering
What quality issues have you noticed with AI-generated code?
#AIEvaluation #SWEBenchArena #CodeQuality #AI #SoftwareEngineering
We need diverse perspectives from:
🎓 AI researchers
👩💻 Professional developers
📚 Academic teams
🚀 Startup engineers
Your input shapes the future of AI code evaluation standards.
🎓 AI researchers
👩💻 Professional developers
📚 Academic teams
🚀 Startup engineers
Your input shapes the future of AI code evaluation standards.
September 4, 2025 at 3:01 AM
We need diverse perspectives from:
🎓 AI researchers
👩💻 Professional developers
📚 Academic teams
🚀 Startup engineers
Your input shapes the future of AI code evaluation standards.
🎓 AI researchers
👩💻 Professional developers
📚 Academic teams
🚀 Startup engineers
Your input shapes the future of AI code evaluation standards.
How it works:
• Real GitHub issues from actual projects
• Side-by-side patch comparison
• Blind evaluation (you don't know which is AI vs human)
• Multi-dimensional quality assessment
Early results are fascinating - some AI solutions are surprisingly elegant, others create hidden technical debt 📊
• Real GitHub issues from actual projects
• Side-by-side patch comparison
• Blind evaluation (you don't know which is AI vs human)
• Multi-dimensional quality assessment
Early results are fascinating - some AI solutions are surprisingly elegant, others create hidden technical debt 📊
September 4, 2025 at 3:01 AM
How it works:
• Real GitHub issues from actual projects
• Side-by-side patch comparison
• Blind evaluation (you don't know which is AI vs human)
• Multi-dimensional quality assessment
Early results are fascinating - some AI solutions are surprisingly elegant, others create hidden technical debt 📊
• Real GitHub issues from actual projects
• Side-by-side patch comparison
• Blind evaluation (you don't know which is AI vs human)
• Multi-dimensional quality assessment
Early results are fascinating - some AI solutions are surprisingly elegant, others create hidden technical debt 📊
That's why we built SWE-Bench-Arena - the first blind evaluation platform for AI code quality.
Instead of just "does it work?", we ask:
✅ Is it maintainable?
✅ Will teams understand it?
✅ Does it follow best practices?
✅ Is it unnecessarily complex?
Instead of just "does it work?", we ask:
✅ Is it maintainable?
✅ Will teams understand it?
✅ Does it follow best practices?
✅ Is it unnecessarily complex?
September 4, 2025 at 3:01 AM
That's why we built SWE-Bench-Arena - the first blind evaluation platform for AI code quality.
Instead of just "does it work?", we ask:
✅ Is it maintainable?
✅ Will teams understand it?
✅ Does it follow best practices?
✅ Is it unnecessarily complex?
Instead of just "does it work?", we ask:
✅ Is it maintainable?
✅ Will teams understand it?
✅ Does it follow best practices?
✅ Is it unnecessarily complex?
5. I call it the Visual Complexity Penalty — and I break it down in detail in my latest post:
🔗 jatinganhotra.dev/blog/swe-age...
📊 Includes full leaderboard analysis, complexity breakdown, and takeaways.
RT if you're building SWE agents — or trying to understand their real limits.
🔗 jatinganhotra.dev/blog/swe-age...
📊 Includes full leaderboard analysis, complexity breakdown, and takeaways.
RT if you're building SWE agents — or trying to understand their real limits.
The Visual Complexity Penalty in Code Understanding - SWE-bench Multimodal Analysis | Jatin Ganhotra
Analyzing how visual content dramatically impacts AI agents' performance on SWE tasks
jatinganhotra.dev
July 27, 2025 at 11:00 PM
5. I call it the Visual Complexity Penalty — and I break it down in detail in my latest post:
🔗 jatinganhotra.dev/blog/swe-age...
📊 Includes full leaderboard analysis, complexity breakdown, and takeaways.
RT if you're building SWE agents — or trying to understand their real limits.
🔗 jatinganhotra.dev/blog/swe-age...
📊 Includes full leaderboard analysis, complexity breakdown, and takeaways.
RT if you're building SWE agents — or trying to understand their real limits.
4. This isn't a benchmark artifact.
It's a wake-up call.
🧠 Current AI systems cannot effectively combine visual + structural code understanding.
And that's a serious problem for real-world software workflows.
It's a wake-up call.
🧠 Current AI systems cannot effectively combine visual + structural code understanding.
And that's a serious problem for real-world software workflows.
July 27, 2025 at 11:00 PM
4. This isn't a benchmark artifact.
It's a wake-up call.
🧠 Current AI systems cannot effectively combine visual + structural code understanding.
And that's a serious problem for real-world software workflows.
It's a wake-up call.
🧠 Current AI systems cannot effectively combine visual + structural code understanding.
And that's a serious problem for real-world software workflows.
3. It's not just the images.
Multimodal tasks often require multi-file edits and focus on JavaScript-based, user-facing applications rather than Python backends.
The combination of visual reasoning + frontend complexity is devastating.
Multimodal tasks often require multi-file edits and focus on JavaScript-based, user-facing applications rather than Python backends.
The combination of visual reasoning + frontend complexity is devastating.
July 27, 2025 at 11:00 PM
3. It's not just the images.
Multimodal tasks often require multi-file edits and focus on JavaScript-based, user-facing applications rather than Python backends.
The combination of visual reasoning + frontend complexity is devastating.
Multimodal tasks often require multi-file edits and focus on JavaScript-based, user-facing applications rather than Python backends.
The combination of visual reasoning + frontend complexity is devastating.
2. Why the collapse?
📸 90.6% of instances in SWE-bench Multimodal contain visual content.
When images are present, solve rates drop from ~100% to ~25% across all top-performing agents.
📸 90.6% of instances in SWE-bench Multimodal contain visual content.
When images are present, solve rates drop from ~100% to ~25% across all top-performing agents.
July 27, 2025 at 11:00 PM
2. Why the collapse?
📸 90.6% of instances in SWE-bench Multimodal contain visual content.
When images are present, solve rates drop from ~100% to ~25% across all top-performing agents.
📸 90.6% of instances in SWE-bench Multimodal contain visual content.
When images are present, solve rates drop from ~100% to ~25% across all top-performing agents.
1. SWE agents are getting better. Some achieve 70-75% accuracy on code-only benchmarks like SWE-bench Verified.
But when the same models are tested on SWE-bench Multimodal, scores fall to ~30%.
But when the same models are tested on SWE-bench Multimodal, scores fall to ~30%.
July 27, 2025 at 11:00 PM
1. SWE agents are getting better. Some achieve 70-75% accuracy on code-only benchmarks like SWE-bench Verified.
But when the same models are tested on SWE-bench Multimodal, scores fall to ~30%.
But when the same models are tested on SWE-bench Multimodal, scores fall to ~30%.

Full analysis: jatinganhotra.dev/blog/swe-age...
From 73% to 11%: Revealing True SWE-Agent Capabilities with Discriminative Subsets | Jatin Ganhotra
jatinganhotra.dev
June 6, 2025 at 8:05 PM
Full analysis: jatinganhotra.dev/blog/swe-age...
6/ Ready to benchmark YOUR agent properly?
Dataset available now:
🤗 huggingface.co/datasets/jatinganhotra/SWE-bench_Verified-discriminative
Stop optimizing for saturated benchmarks. Start measuring real progress.
Dataset available now:
🤗 huggingface.co/datasets/jatinganhotra/SWE-bench_Verified-discriminative
Stop optimizing for saturated benchmarks. Start measuring real progress.

jatinganhotra/SWE-bench_Verified-discriminative · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
June 6, 2025 at 8:05 PM
6/ Ready to benchmark YOUR agent properly?
Dataset available now:
🤗 huggingface.co/datasets/jatinganhotra/SWE-bench_Verified-discriminative
Stop optimizing for saturated benchmarks. Start measuring real progress.
Dataset available now:
🤗 huggingface.co/datasets/jatinganhotra/SWE-bench_Verified-discriminative
Stop optimizing for saturated benchmarks. Start measuring real progress.
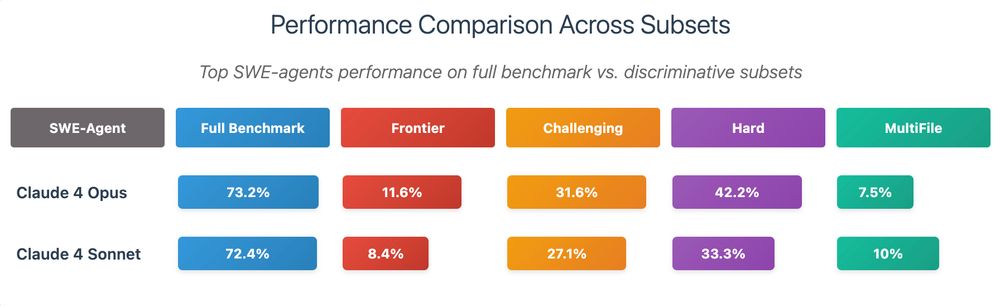
5/ The results are eye-opening:
Claude 4 Opus on full benchmark: 73.2% ✅
Claude 4 Opus on Frontier subset: 11.6% 😬
This isn't just harder - it's revealing what agents ACTUALLY can't do
Claude 4 Opus on full benchmark: 73.2% ✅
Claude 4 Opus on Frontier subset: 11.6% 😬
This isn't just harder - it's revealing what agents ACTUALLY can't do
June 6, 2025 at 8:05 PM
5/ The results are eye-opening:
Claude 4 Opus on full benchmark: 73.2% ✅
Claude 4 Opus on Frontier subset: 11.6% 😬
This isn't just harder - it's revealing what agents ACTUALLY can't do
Claude 4 Opus on full benchmark: 73.2% ✅
Claude 4 Opus on Frontier subset: 11.6% 😬
This isn't just harder - it's revealing what agents ACTUALLY can't do
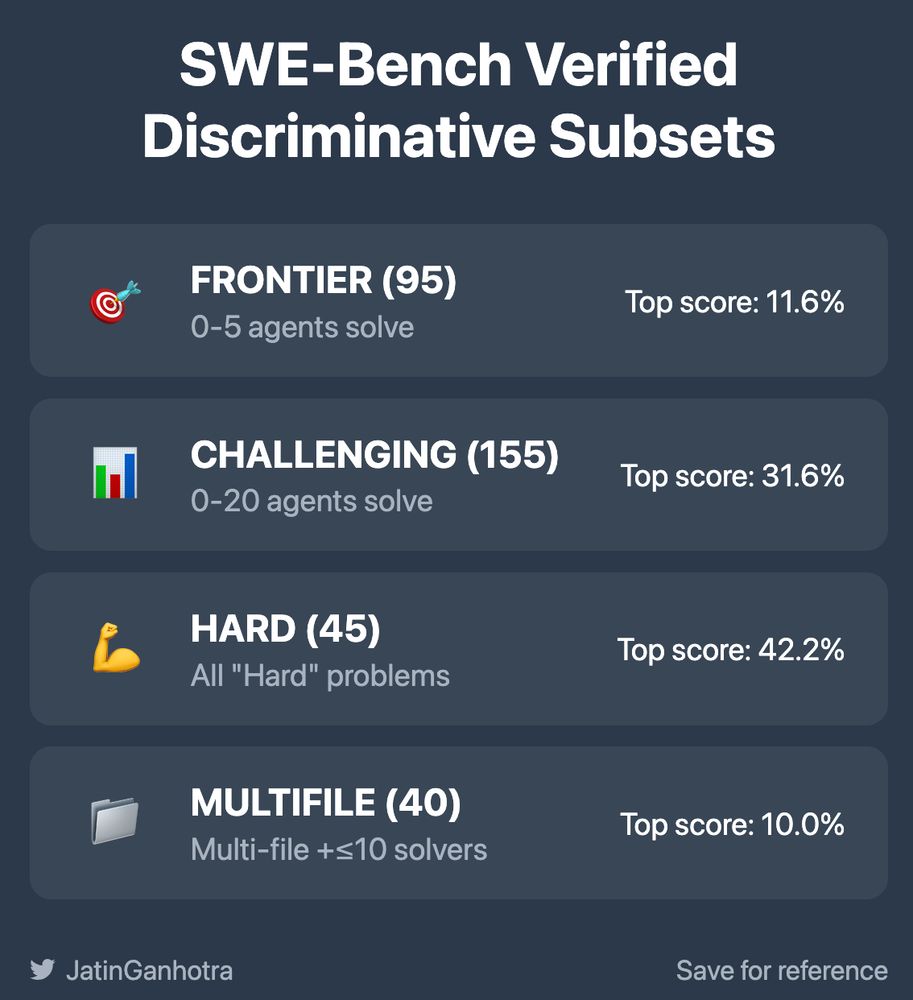
4/ Solution: 4 targeted subsets that reveal true agent capabilities
Each subset targets different evaluation needs - from maximum sensitivity (Frontier) to real-world complexity (MultiFile)
Performance drops from 73% to as low as 10%!
Each subset targets different evaluation needs - from maximum sensitivity (Frontier) to real-world complexity (MultiFile)
Performance drops from 73% to as low as 10%!
June 6, 2025 at 8:05 PM
4/ Solution: 4 targeted subsets that reveal true agent capabilities
Each subset targets different evaluation needs - from maximum sensitivity (Frontier) to real-world complexity (MultiFile)
Performance drops from 73% to as low as 10%!
Each subset targets different evaluation needs - from maximum sensitivity (Frontier) to real-world complexity (MultiFile)
Performance drops from 73% to as low as 10%!
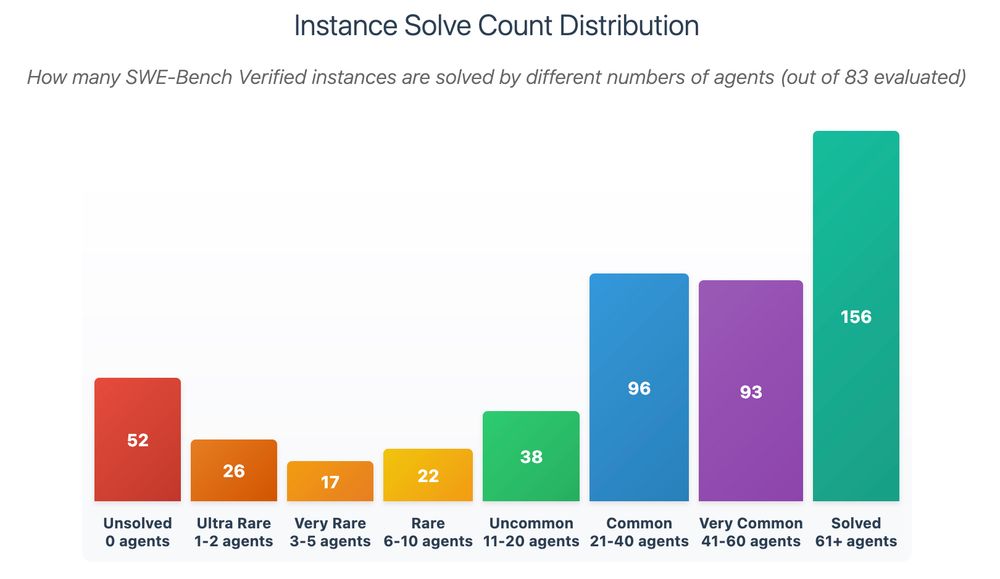
3/ I analyzed all 500 problems against 83 different SWE-agents
The distribution is shocking:
- 52 problems: ZERO agents can solve
- 26 problems: Only 1-2 agents succeed
- 156 problems: 61+ agents solve easily
The distribution is shocking:
- 52 problems: ZERO agents can solve
- 26 problems: Only 1-2 agents succeed
- 156 problems: 61+ agents solve easily
June 6, 2025 at 8:05 PM
3/ I analyzed all 500 problems against 83 different SWE-agents
The distribution is shocking:
- 52 problems: ZERO agents can solve
- 26 problems: Only 1-2 agents succeed
- 156 problems: 61+ agents solve easily
The distribution is shocking:
- 52 problems: ZERO agents can solve
- 26 problems: Only 1-2 agents succeed
- 156 problems: 61+ agents solve easily
2/ The problem: 156/500 problems are solved by 61+ agents
When everyone gets the same questions right, you can't tell who's actually better @anthropic.com
It's like ranking students when everyone scores 95%+ on the easy questions
When everyone gets the same questions right, you can't tell who's actually better @anthropic.com
It's like ranking students when everyone scores 95%+ on the easy questions
June 6, 2025 at 8:05 PM
2/ The problem: 156/500 problems are solved by 61+ agents
When everyone gets the same questions right, you can't tell who's actually better @anthropic.com
It's like ranking students when everyone scores 95%+ on the easy questions
When everyone gets the same questions right, you can't tell who's actually better @anthropic.com
It's like ranking students when everyone scores 95%+ on the easy questions