



Jatin Ganhotra
@jatinganhotra.dev
Researcher at @IBMResearch #NLProc #ConvAI #Agents #SWE-Agent || RTs ≠ endorsements. Views personal, not of employers/institutions.
jatinganhotra.dev swebencharena.com
jatinganhotra.dev swebencharena.com
Fascinating finding: When you remove the 156 problems that 61+ agents solve, performance drops dramatically
Top agents: 73% → 11%
This isn't about making things harder - it's about measuring what matters 🎯
jatinganhotra.dev/blog/swe-age...
Top agents: 73% → 11%
This isn't about making things harder - it's about measuring what matters 🎯
jatinganhotra.dev/blog/swe-age...
June 17, 2025 at 7:47 PM
Fascinating finding: When you remove the 156 problems that 61+ agents solve, performance drops dramatically
Top agents: 73% → 11%
This isn't about making things harder - it's about measuring what matters 🎯
jatinganhotra.dev/blog/swe-age...
Top agents: 73% → 11%
This isn't about making things harder - it's about measuring what matters 🎯
jatinganhotra.dev/blog/swe-age...
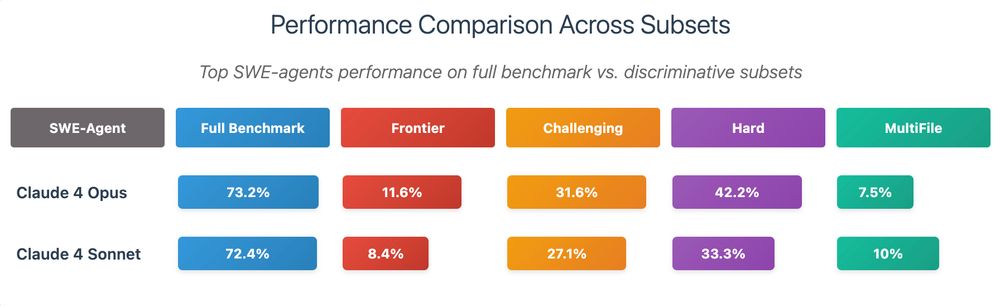
5/ The results are eye-opening:
Claude 4 Opus on full benchmark: 73.2% ✅
Claude 4 Opus on Frontier subset: 11.6% 😬
This isn't just harder - it's revealing what agents ACTUALLY can't do
Claude 4 Opus on full benchmark: 73.2% ✅
Claude 4 Opus on Frontier subset: 11.6% 😬
This isn't just harder - it's revealing what agents ACTUALLY can't do
June 6, 2025 at 8:05 PM
5/ The results are eye-opening:
Claude 4 Opus on full benchmark: 73.2% ✅
Claude 4 Opus on Frontier subset: 11.6% 😬
This isn't just harder - it's revealing what agents ACTUALLY can't do
Claude 4 Opus on full benchmark: 73.2% ✅
Claude 4 Opus on Frontier subset: 11.6% 😬
This isn't just harder - it's revealing what agents ACTUALLY can't do
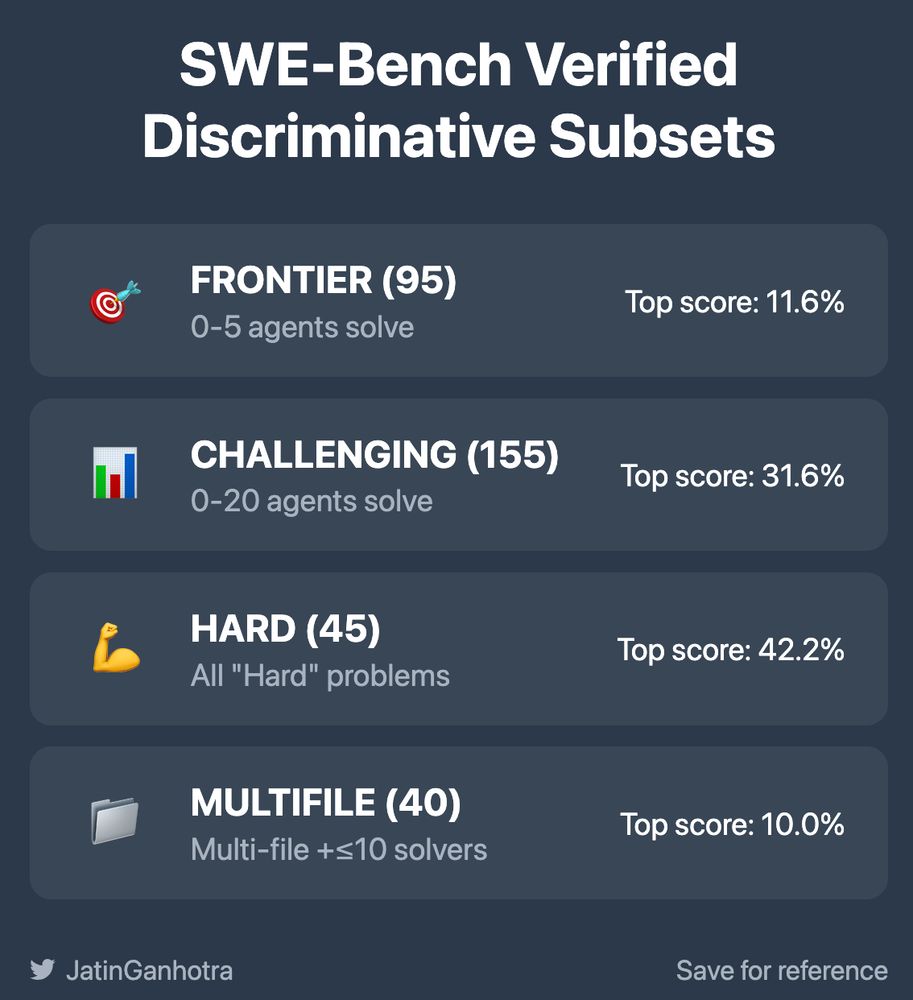
4/ Solution: 4 targeted subsets that reveal true agent capabilities
Each subset targets different evaluation needs - from maximum sensitivity (Frontier) to real-world complexity (MultiFile)
Performance drops from 73% to as low as 10%!
Each subset targets different evaluation needs - from maximum sensitivity (Frontier) to real-world complexity (MultiFile)
Performance drops from 73% to as low as 10%!
June 6, 2025 at 8:05 PM
4/ Solution: 4 targeted subsets that reveal true agent capabilities
Each subset targets different evaluation needs - from maximum sensitivity (Frontier) to real-world complexity (MultiFile)
Performance drops from 73% to as low as 10%!
Each subset targets different evaluation needs - from maximum sensitivity (Frontier) to real-world complexity (MultiFile)
Performance drops from 73% to as low as 10%!
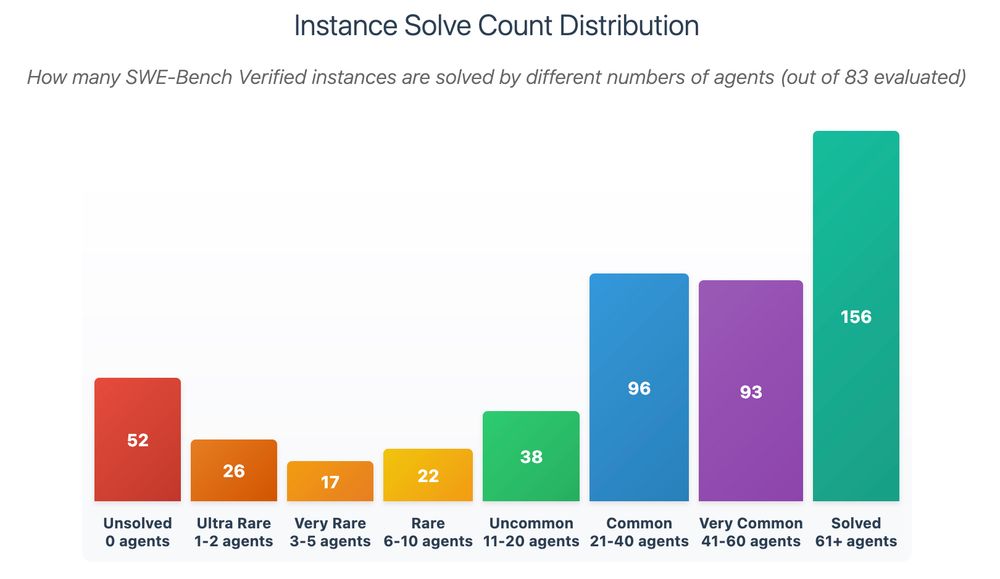
3/ I analyzed all 500 problems against 83 different SWE-agents
The distribution is shocking:
- 52 problems: ZERO agents can solve
- 26 problems: Only 1-2 agents succeed
- 156 problems: 61+ agents solve easily
The distribution is shocking:
- 52 problems: ZERO agents can solve
- 26 problems: Only 1-2 agents succeed
- 156 problems: 61+ agents solve easily
June 6, 2025 at 8:05 PM
3/ I analyzed all 500 problems against 83 different SWE-agents
The distribution is shocking:
- 52 problems: ZERO agents can solve
- 26 problems: Only 1-2 agents succeed
- 156 problems: 61+ agents solve easily
The distribution is shocking:
- 52 problems: ZERO agents can solve
- 26 problems: Only 1-2 agents succeed
- 156 problems: 61+ agents solve easily