



Jatin Ganhotra
@jatinganhotra.dev
Researcher at @IBMResearch #NLProc #ConvAI #Agents #SWE-Agent || RTs ≠ endorsements. Views personal, not of employers/institutions.
jatinganhotra.dev swebencharena.com
jatinganhotra.dev swebencharena.com
Reposted by Jatin Ganhotra

(repost welcome) The Generative Model Alignment team at IBM Research is looking for next summer interns! Two candidates for two topics
🍰Reinforcement Learning environments for LLMs
🐎Speculative and non-auto regressive generation for LLMs
interested/curious? DM or email ramon.astudillo@ibm.com
🍰Reinforcement Learning environments for LLMs
🐎Speculative and non-auto regressive generation for LLMs
interested/curious? DM or email ramon.astudillo@ibm.com
October 7, 2025 at 8:19 PM
(repost welcome) The Generative Model Alignment team at IBM Research is looking for next summer interns! Two candidates for two topics
🍰Reinforcement Learning environments for LLMs
🐎Speculative and non-auto regressive generation for LLMs
interested/curious? DM or email ramon.astudillo@ibm.com
🍰Reinforcement Learning environments for LLMs
🐎Speculative and non-auto regressive generation for LLMs
interested/curious? DM or email ramon.astudillo@ibm.com
🧵 1/4 Current AI coding benchmarks miss the mark.
Claude 4 Sonnet hits 72.7% on SWE-Bench, but industry data shows code clones rose 48% (8.3% to 12.3%) and refactoring rates dropped from 25% to 10% since AI adoption.
(GitClear: gitclear.com/ai_assistant_code_quality_2025_research)
Claude 4 Sonnet hits 72.7% on SWE-Bench, but industry data shows code clones rose 48% (8.3% to 12.3%) and refactoring rates dropped from 25% to 10% since AI adoption.
(GitClear: gitclear.com/ai_assistant_code_quality_2025_research)
AI Copilot Code Quality: 2025 Data Suggests 4x Growth in Code Clones - GitClear
gitclear.com
September 15, 2025 at 4:06 AM
🧵 1/4 Current AI coding benchmarks miss the mark.
Claude 4 Sonnet hits 72.7% on SWE-Bench, but industry data shows code clones rose 48% (8.3% to 12.3%) and refactoring rates dropped from 25% to 10% since AI adoption.
(GitClear: gitclear.com/ai_assistant_code_quality_2025_research)
Claude 4 Sonnet hits 72.7% on SWE-Bench, but industry data shows code clones rose 48% (8.3% to 12.3%) and refactoring rates dropped from 25% to 10% since AI adoption.
(GitClear: gitclear.com/ai_assistant_code_quality_2025_research)
🔍 AI models hit 72%+ on coding benchmarks, but there's a hidden problem...
Recent data shows concerning trends since AI adoption:
• 48% increase in code cloning
• Refactoring dropped from 25% to 10%
• Developers report "missing context" as #1 issue
Are we optimizing for the wrong metrics? 🧵
Recent data shows concerning trends since AI adoption:
• 48% increase in code cloning
• Refactoring dropped from 25% to 10%
• Developers report "missing context" as #1 issue
Are we optimizing for the wrong metrics? 🧵
September 4, 2025 at 3:01 AM
🔍 AI models hit 72%+ on coding benchmarks, but there's a hidden problem...
Recent data shows concerning trends since AI adoption:
• 48% increase in code cloning
• Refactoring dropped from 25% to 10%
• Developers report "missing context" as #1 issue
Are we optimizing for the wrong metrics? 🧵
Recent data shows concerning trends since AI adoption:
• 48% increase in code cloning
• Refactoring dropped from 25% to 10%
• Developers report "missing context" as #1 issue
Are we optimizing for the wrong metrics? 🧵
🚨 New Blog Post:
AI agents collapse under visual complexity.
A 73.2% performance drop when images are introduced in SWE-bench Multimodal.
Here's why this matters — and what it tells us about the future of AI in software engineering:
🧵👇
AI agents collapse under visual complexity.
A 73.2% performance drop when images are introduced in SWE-bench Multimodal.
Here's why this matters — and what it tells us about the future of AI in software engineering:
🧵👇
July 27, 2025 at 11:00 PM
🚨 New Blog Post:
AI agents collapse under visual complexity.
A 73.2% performance drop when images are introduced in SWE-bench Multimodal.
Here's why this matters — and what it tells us about the future of AI in software engineering:
🧵👇
AI agents collapse under visual complexity.
A 73.2% performance drop when images are introduced in SWE-bench Multimodal.
Here's why this matters — and what it tells us about the future of AI in software engineering:
🧵👇
Like the tale of the Emperor's new clothes, sometimes we need fresh eyes on familiar benchmarks.
SWE-Bench Verified shows 73% success rates, but focusing on discriminative subsets reveals a different story: 11%
What really challenges AI agents? Analysis: jatinganhotra.dev/blog/swe-age...
SWE-Bench Verified shows 73% success rates, but focusing on discriminative subsets reveals a different story: 11%
What really challenges AI agents? Analysis: jatinganhotra.dev/blog/swe-age...
From 73% to 11%: Revealing True SWE-Agent Capabilities with Discriminative Subsets | Jatin Ganhotra
jatinganhotra.dev
July 21, 2025 at 7:24 PM
Like the tale of the Emperor's new clothes, sometimes we need fresh eyes on familiar benchmarks.
SWE-Bench Verified shows 73% success rates, but focusing on discriminative subsets reveals a different story: 11%
What really challenges AI agents? Analysis: jatinganhotra.dev/blog/swe-age...
SWE-Bench Verified shows 73% success rates, but focusing on discriminative subsets reveals a different story: 11%
What really challenges AI agents? Analysis: jatinganhotra.dev/blog/swe-age...
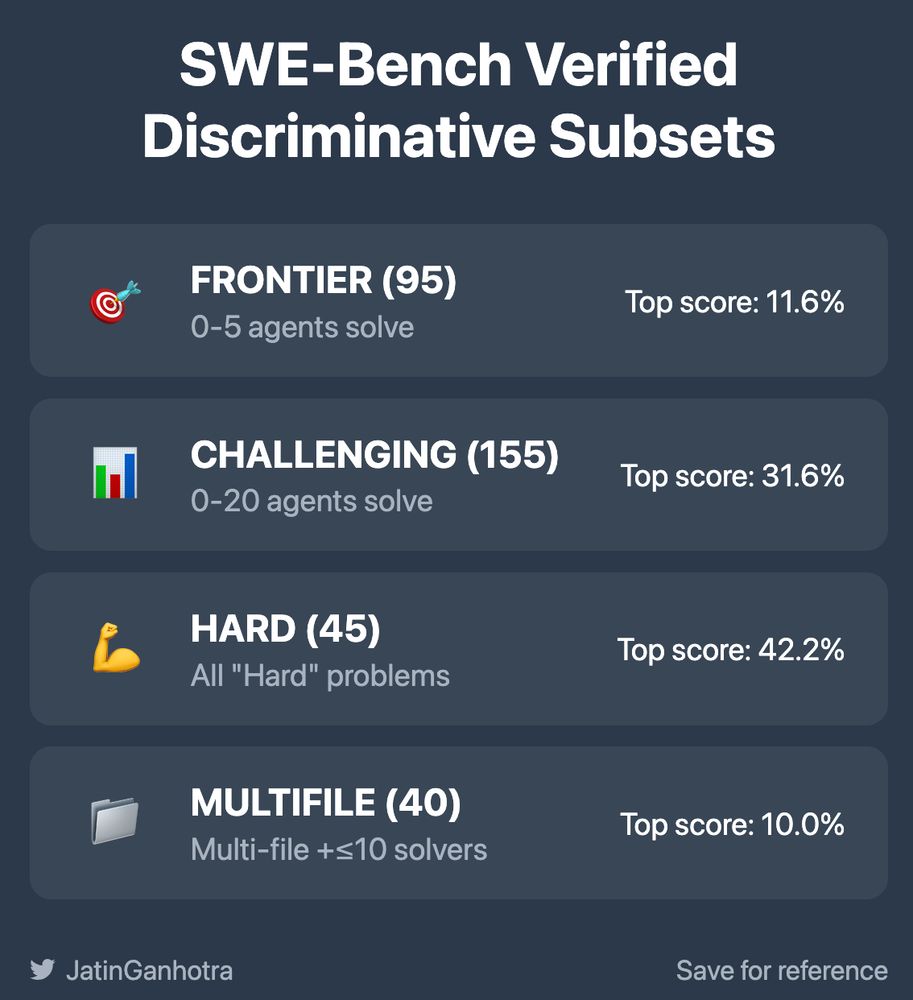
Fascinating finding: When you remove the 156 problems that 61+ agents solve, performance drops dramatically
Top agents: 73% → 11%
This isn't about making things harder - it's about measuring what matters 🎯
jatinganhotra.dev/blog/swe-age...
Top agents: 73% → 11%
This isn't about making things harder - it's about measuring what matters 🎯
jatinganhotra.dev/blog/swe-age...
June 17, 2025 at 7:47 PM
Fascinating finding: When you remove the 156 problems that 61+ agents solve, performance drops dramatically
Top agents: 73% → 11%
This isn't about making things harder - it's about measuring what matters 🎯
jatinganhotra.dev/blog/swe-age...
Top agents: 73% → 11%
This isn't about making things harder - it's about measuring what matters 🎯
jatinganhotra.dev/blog/swe-age...
1/ "What gets measured gets improved" - but are we measuring the right things?
SWE-Bench Verified has driven amazing progress, but with most agents solving 350+ same problems, we need new targets @ofirpress.bsky.social
Enter: discriminative subsets that highlight genuine challenges 🧵
SWE-Bench Verified has driven amazing progress, but with most agents solving 350+ same problems, we need new targets @ofirpress.bsky.social
Enter: discriminative subsets that highlight genuine challenges 🧵
June 6, 2025 at 8:05 PM
1/ "What gets measured gets improved" - but are we measuring the right things?
SWE-Bench Verified has driven amazing progress, but with most agents solving 350+ same problems, we need new targets @ofirpress.bsky.social
Enter: discriminative subsets that highlight genuine challenges 🧵
SWE-Bench Verified has driven amazing progress, but with most agents solving 350+ same problems, we need new targets @ofirpress.bsky.social
Enter: discriminative subsets that highlight genuine challenges 🧵
With OpenAI releasing Codex, a SWE agent openai.com/index/introd... and evaluating on both "SWE-Bench-Verified" AND "OpenAI Internal SWE tasks", I thought it's important to once again highlight issues with SWE-Bench-Verified.
I've compiled all my analysis here: 🧵
I've compiled all my analysis here: 🧵
Introducing Codex
Introducing Codex: a cloud-based software engineering agent that can work on many tasks in parallel, powered by codex-1. With Codex, developers can simultaneously deploy multiple agents to independent...
openai.com
May 18, 2025 at 5:32 PM
With OpenAI releasing Codex, a SWE agent openai.com/index/introd... and evaluating on both "SWE-Bench-Verified" AND "OpenAI Internal SWE tasks", I thought it's important to once again highlight issues with SWE-Bench-Verified.
I've compiled all my analysis here: 🧵
I've compiled all my analysis here: 🧵
🚀 Advancing AI-Powered Software Testing! 🚀
SWE-Agents can now generate code to resolve GitHub issues—but how do we ensure these fixes are robust and reliable? Introducing **Otter & Otter++**, two innovative test generation approaches leveraging LLMs with self-reflective action planning. 🦦🔍
SWE-Agents can now generate code to resolve GitHub issues—but how do we ensure these fixes are robust and reliable? Introducing **Otter & Otter++**, two innovative test generation approaches leveraging LLMs with self-reflective action planning. 🦦🔍
March 12, 2025 at 8:04 PM
🚀 Advancing AI-Powered Software Testing! 🚀
SWE-Agents can now generate code to resolve GitHub issues—but how do we ensure these fixes are robust and reliable? Introducing **Otter & Otter++**, two innovative test generation approaches leveraging LLMs with self-reflective action planning. 🦦🔍
SWE-Agents can now generate code to resolve GitHub issues—but how do we ensure these fixes are robust and reliable? Introducing **Otter & Otter++**, two innovative test generation approaches leveraging LLMs with self-reflective action planning. 🦦🔍
Reposted by Jatin Ganhotra

🌟 New Benchmark! 🌟
Do you work on RAG? Are you interested in Multi-Turn conversations? Very excited to share the new MTRAG benchmark we have released!
Data: github.com/ibm/mt-rag-b...
Paper: arxiv.org/abs/2501.03468
Do you work on RAG? Are you interested in Multi-Turn conversations? Very excited to share the new MTRAG benchmark we have released!
Data: github.com/ibm/mt-rag-b...
Paper: arxiv.org/abs/2501.03468

GitHub - IBM/mt-rag-benchmark: Multi-Turn RAG Benchmark
Multi-Turn RAG Benchmark. Contribute to IBM/mt-rag-benchmark development by creating an account on GitHub.
github.com
January 8, 2025 at 8:08 PM
🌟 New Benchmark! 🌟
Do you work on RAG? Are you interested in Multi-Turn conversations? Very excited to share the new MTRAG benchmark we have released!
Data: github.com/ibm/mt-rag-b...
Paper: arxiv.org/abs/2501.03468
Do you work on RAG? Are you interested in Multi-Turn conversations? Very excited to share the new MTRAG benchmark we have released!
Data: github.com/ibm/mt-rag-b...
Paper: arxiv.org/abs/2501.03468
Can AI handle multi-file coding challenges like humans? This post dives deep into SWE-Agents vs. human engineers on SWE-Bench Verified. With 14.2% of tasks needing cross-file changes, are AI systems taking shortcuts or truly solving the problem?
jatinganhotra.github.io/blog/swe-age...
jatinganhotra.github.io/blog/swe-age...
January 6, 2025 at 4:58 PM
Can AI handle multi-file coding challenges like humans? This post dives deep into SWE-Agents vs. human engineers on SWE-Bench Verified. With 14.2% of tasks needing cross-file changes, are AI systems taking shortcuts or truly solving the problem?
jatinganhotra.github.io/blog/swe-age...
jatinganhotra.github.io/blog/swe-age...