



Justin Silverman
@inschool4life.bsky.social
Assistant Professor of Informatics, Statistics, and Medicine at Penn State University
https://jsilve24.github.io/SilvermanLab/
https://jsilve24.github.io/SilvermanLab/
Our analysis is the largest to date, we used our newly created MUTT database which consists of over 15,000 samples, from over 30 studies, each with paired sequence counts and microbial load measurements.
Core takeaway, its important to accurately model uncertainty and error.
@ggloor.bsky.social
Core takeaway, its important to accurately model uncertainty and error.
@ggloor.bsky.social
September 17, 2025 at 5:41 PM
Our analysis is the largest to date, we used our newly created MUTT database which consists of over 15,000 samples, from over 30 studies, each with paired sequence counts and microbial load measurements.
Core takeaway, its important to accurately model uncertainty and error.
@ggloor.bsky.social
Core takeaway, its important to accurately model uncertainty and error.
@ggloor.bsky.social
Thanks! We think so. I think this will help enhance the cost-effectiveness and efficiency of biomarker discovery, our methods grealy enhance positive predictive value of analyses -reducing false signals that cost money to validate and detecting true signals that would otherwise be missed.
August 1, 2025 at 1:53 PM
Thanks! We think so. I think this will help enhance the cost-effectiveness and efficiency of biomarker discovery, our methods grealy enhance positive predictive value of analyses -reducing false signals that cost money to validate and detecting true signals that would otherwise be missed.
May 22, 2025 at 4:44 PM
Scale models are not just heuristics but have a rich theoretical foundation based on Bayesian Partially Identified Models. That theory is presented here:
arxiv.org/abs/2201.03616
arxiv.org/abs/2201.03616

Scale Reliant Inference
Many scientific fields, including human gut microbiome science, collect multivariate count data where the sum of the counts is unrelated to the scale of the underlying system being measured (e.g., tot...
arxiv.org
May 22, 2025 at 4:43 PM
Scale models are not just heuristics but have a rich theoretical foundation based on Bayesian Partially Identified Models. That theory is presented here:
arxiv.org/abs/2201.03616
arxiv.org/abs/2201.03616
We are also developing a new ALDEx3 library that is about 1000 times faster than ALDEx2 with a streamlined user interface (although its still in beta I am using it regularly)
github.com/jsilve24/ALD...
github.com/jsilve24/ALD...
GitHub - jsilve24/ALDEx3
Contribute to jsilve24/ALDEx3 development by creating an account on GitHub.
github.com
May 22, 2025 at 4:43 PM
We are also developing a new ALDEx3 library that is about 1000 times faster than ALDEx2 with a streamlined user interface (although its still in beta I am using it regularly)
github.com/jsilve24/ALD...
github.com/jsilve24/ALD...
To facilitate adoption, we've update the popular ALDEx2 software package on Bioconductor to support scale model analysis.
GitHub - jsilve24/ALDEx3
Contribute to jsilve24/ALDEx3 development by creating an account on GitHub.
github.com
May 22, 2025 at 4:43 PM
To facilitate adoption, we've update the popular ALDEx2 software package on Bioconductor to support scale model analysis.
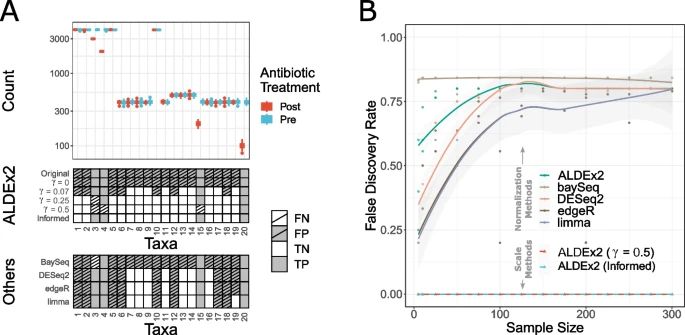
In real data analysesd simulation studies we find our methods often lead to dramatic decreases in false positves (FDR can drop from >75% to a nominal 5%) while simultaneously maintaining or improving statistical power.
May 22, 2025 at 4:43 PM
In real data analysesd simulation studies we find our methods often lead to dramatic decreases in false positves (FDR can drop from >75% to a nominal 5%) while simultaneously maintaining or improving statistical power.
We present scale mdoels, which extend normalization by modeling potential errors in these assumptions (reducing false positives), or by allowing researchers to make more biologically plausible assumptions (reducing false negatives).
May 22, 2025 at 4:43 PM
We present scale mdoels, which extend normalization by modeling potential errors in these assumptions (reducing false positives), or by allowing researchers to make more biologically plausible assumptions (reducing false negatives).
Traditional normalization methods often make implicit assumptions abou thte biological system's scale, such as microbial load or total RNA content. These assumptions can lead to false positives and negatives.
May 22, 2025 at 4:43 PM
Traditional normalization methods often make implicit assumptions abou thte biological system's scale, such as microbial load or total RNA content. These assumptions can lead to false positives and negatives.
Our whole point is that there is information missing from the data -- overcoming that requires additional thought and a careful consideration of what assumptions are biologically plausible in a particular study. e.g., studying antibiotics Microbial load likely decreases post-treatment etc...
February 19, 2025 at 3:57 PM
Our whole point is that there is information missing from the data -- overcoming that requires additional thought and a careful consideration of what assumptions are biologically plausible in a particular study. e.g., studying antibiotics Microbial load likely decreases post-treatment etc...
An important point if you look to benchmark our methods. Normalizations are kinda "point and click", no additional thought needed by user. We can generalize normalilzations and it helps reduce false positives. But the real advances -- when we see the massive FN/FP decreases is when care is taken.
February 19, 2025 at 3:57 PM
An important point if you look to benchmark our methods. Normalizations are kinda "point and click", no additional thought needed by user. We can generalize normalilzations and it helps reduce false positives. But the real advances -- when we see the massive FN/FP decreases is when care is taken.
Love it! Will deffinetly check that out as it would be super helpful for us. An yes, our methods are not yet common (thought they are available in ALDEx2 now!). Reviewers have been resistant as they love normalizations and our methods seem foreign.
February 19, 2025 at 3:57 PM
Love it! Will deffinetly check that out as it would be super helpful for us. An yes, our methods are not yet common (thought they are available in ALDEx2 now!). Reviewers have been resistant as they love normalizations and our methods seem foreign.
This builds on our prior work
jmlr.org/papers/v23/1...
where we introduced the CU Sampler for Bayesian MLN models. This is even 1-2 orders of magnitude faster than those methods while still be extreemly accurate.
jmlr.org/papers/v23/1...
where we introduced the CU Sampler for Bayesian MLN models. This is even 1-2 orders of magnitude faster than those methods while still be extreemly accurate.
jmlr.org
February 19, 2025 at 2:47 PM
This builds on our prior work
jmlr.org/papers/v23/1...
where we introduced the CU Sampler for Bayesian MLN models. This is even 1-2 orders of magnitude faster than those methods while still be extreemly accurate.
jmlr.org/papers/v23/1...
where we introduced the CU Sampler for Bayesian MLN models. This is even 1-2 orders of magnitude faster than those methods while still be extreemly accurate.