




Hazel Doughty
@hazeldoughty.bsky.social
Assistant Professor at Leiden University, NL. Computer Vision, Video Understanding.
https://hazeldoughty.github.io
https://hazeldoughty.github.io
VQA Benchmark
Our benchmark tests understanding in recipes, ingredients, nutrition, fine-grained actions, 3D perception, object movement and gaze. Current models have a long way to go with a best performance of 38% vs. 90% human baseline.
Our benchmark tests understanding in recipes, ingredients, nutrition, fine-grained actions, 3D perception, object movement and gaze. Current models have a long way to go with a best performance of 38% vs. 90% human baseline.

February 7, 2025 at 12:27 PM
VQA Benchmark
Our benchmark tests understanding in recipes, ingredients, nutrition, fine-grained actions, 3D perception, object movement and gaze. Current models have a long way to go with a best performance of 38% vs. 90% human baseline.
Our benchmark tests understanding in recipes, ingredients, nutrition, fine-grained actions, 3D perception, object movement and gaze. Current models have a long way to go with a best performance of 38% vs. 90% human baseline.
Scene & Object Movements
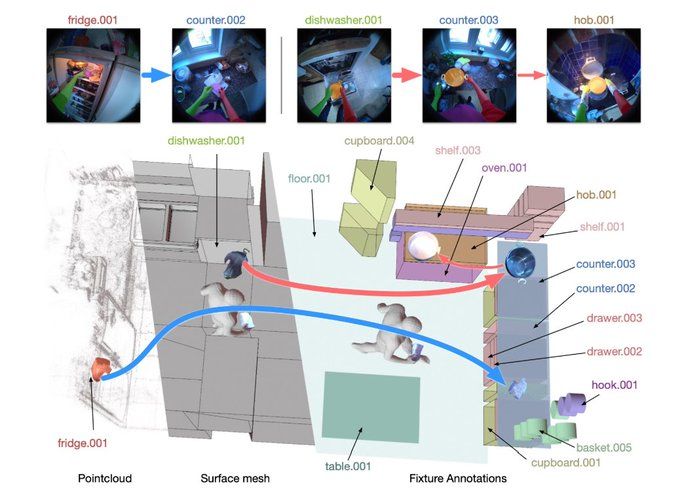
We reconstruct participants kitchens and annotate every time an object is moved.
We reconstruct participants kitchens and annotate every time an object is moved.
February 7, 2025 at 12:27 PM
Scene & Object Movements
We reconstruct participants kitchens and annotate every time an object is moved.
We reconstruct participants kitchens and annotate every time an object is moved.
Fine-grained Actions
Every action has a dense description not only describing what happens in detail, but also how and why it happens.
Every action has a dense description not only describing what happens in detail, but also how and why it happens.


February 7, 2025 at 12:27 PM
Fine-grained Actions
Every action has a dense description not only describing what happens in detail, but also how and why it happens.
Every action has a dense description not only describing what happens in detail, but also how and why it happens.
As well as annotating temporal segments corresponding to each step we also annotate all the preparation needed to complete each step.

February 7, 2025 at 12:27 PM
As well as annotating temporal segments corresponding to each step we also annotate all the preparation needed to complete each step.
Recipe & Nutrition
We collect details of all the recipes participants chose to perform over 3 days in their own kitchen. Alongside ingredient weights and nutrition.
We collect details of all the recipes participants chose to perform over 3 days in their own kitchen. Alongside ingredient weights and nutrition.

February 7, 2025 at 12:27 PM
Recipe & Nutrition
We collect details of all the recipes participants chose to perform over 3 days in their own kitchen. Alongside ingredient weights and nutrition.
We collect details of all the recipes participants chose to perform over 3 days in their own kitchen. Alongside ingredient weights and nutrition.
📢 Today we're releasing a new highly detailed dataset for video understanding: HD-EPIC
arxiv.org/abs/2502.04144
hd-epic.github.io
What makes the dataset unique is the vast detail contained in the annotations with 263 annotations per minute over 41 hours of video.
arxiv.org/abs/2502.04144
hd-epic.github.io
What makes the dataset unique is the vast detail contained in the annotations with 263 annotations per minute over 41 hours of video.
February 7, 2025 at 12:27 PM
📢 Today we're releasing a new highly detailed dataset for video understanding: HD-EPIC
arxiv.org/abs/2502.04144
hd-epic.github.io
What makes the dataset unique is the vast detail contained in the annotations with 263 annotations per minute over 41 hours of video.
arxiv.org/abs/2502.04144
hd-epic.github.io
What makes the dataset unique is the vast detail contained in the annotations with 263 annotations per minute over 41 hours of video.
Incorporating fine-grained negatives into training does improve fine-grained performance, however it comes at the cost of coarse-grained performance.

December 10, 2024 at 6:46 AM
Incorporating fine-grained negatives into training does improve fine-grained performance, however it comes at the cost of coarse-grained performance.
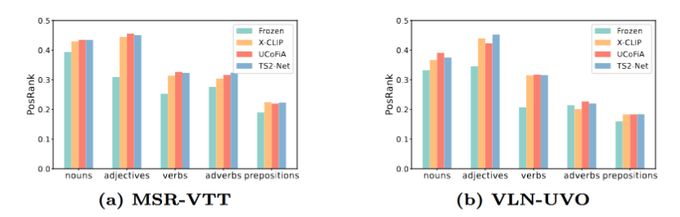
We use this evaluation to investigate current models and find they lack fine-grained understanding, particularly for adverbs and prepositions.
We also see that good coarse-grained performance does not necessarily indicate good fine-grained performance.
We also see that good coarse-grained performance does not necessarily indicate good fine-grained performance.
December 10, 2024 at 6:46 AM
We use this evaluation to investigate current models and find they lack fine-grained understanding, particularly for adverbs and prepositions.
We also see that good coarse-grained performance does not necessarily indicate good fine-grained performance.
We also see that good coarse-grained performance does not necessarily indicate good fine-grained performance.
We propose a new fine-grained evaluation approach which analyses a model's sensitivity to individual word variations in different parts-of-speech.
Our approach automatically creates new fine-grained negative captions and can be applied to any existing dataset.
Our approach automatically creates new fine-grained negative captions and can be applied to any existing dataset.

December 10, 2024 at 6:46 AM
We propose a new fine-grained evaluation approach which analyses a model's sensitivity to individual word variations in different parts-of-speech.
Our approach automatically creates new fine-grained negative captions and can be applied to any existing dataset.
Our approach automatically creates new fine-grained negative captions and can be applied to any existing dataset.
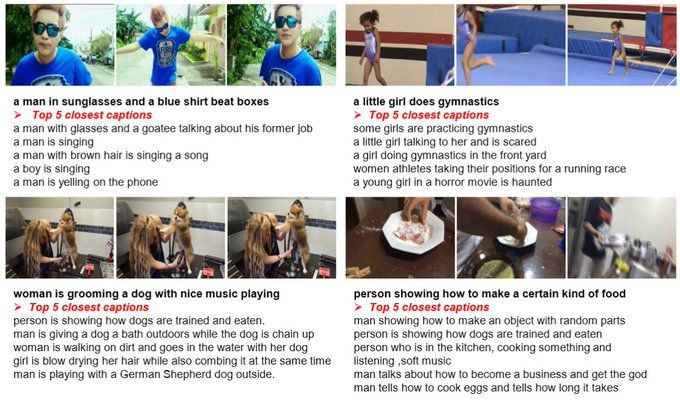
Current video-text retrieval benchmarks focus on coarse-grained differences as they focus on distinguishing the correct caption from captions of other, often irrelevant videos.
Captions thus rarely differ by a single word or concept.
Captions thus rarely differ by a single word or concept.
December 10, 2024 at 6:46 AM
Current video-text retrieval benchmarks focus on coarse-grained differences as they focus on distinguishing the correct caption from captions of other, often irrelevant videos.
Captions thus rarely differ by a single word or concept.
Captions thus rarely differ by a single word or concept.
Our second #ACCV2024 oral: "Beyond Coarse-Grained Matching in Video-Text Retrieval" is also being presented today.
ArXiv: arxiv.org/abs/2410.12407
We go beyond coarse-grained retrieval and explore whether models can discern subtle single-word differences in captions.
ArXiv: arxiv.org/abs/2410.12407
We go beyond coarse-grained retrieval and explore whether models can discern subtle single-word differences in captions.

December 10, 2024 at 6:46 AM
Our second #ACCV2024 oral: "Beyond Coarse-Grained Matching in Video-Text Retrieval" is also being presented today.
ArXiv: arxiv.org/abs/2410.12407
We go beyond coarse-grained retrieval and explore whether models can discern subtle single-word differences in captions.
ArXiv: arxiv.org/abs/2410.12407
We go beyond coarse-grained retrieval and explore whether models can discern subtle single-word differences in captions.
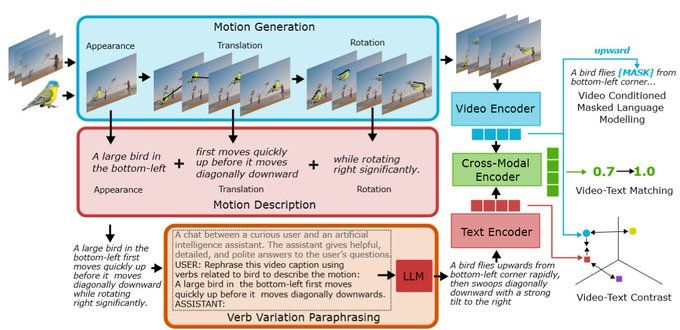
Since we know how our synthetic motions have been generated we can also generate captions to describe them using pre-defined phrases. We then diversify the vocabulary and structure of our descriptions with our verb-variation paraphrasing.

December 10, 2024 at 6:42 AM
Since we know how our synthetic motions have been generated we can also generate captions to describe them using pre-defined phrases. We then diversify the vocabulary and structure of our descriptions with our verb-variation paraphrasing.
We address this by proposing a method to learn motion-focused representations with available spatial-focused data. We first generate synthetic local object motions and inject this into training videos.
December 10, 2024 at 6:42 AM
We address this by proposing a method to learn motion-focused representations with available spatial-focused data. We first generate synthetic local object motions and inject this into training videos.
Moreover, large proportion of captions are uniquely identifiable by the nouns alone, meaning a caption can be matched to the correct video clip by only recognizing the correct nouns.
December 10, 2024 at 6:42 AM
Moreover, large proportion of captions are uniquely identifiable by the nouns alone, meaning a caption can be matched to the correct video clip by only recognizing the correct nouns.
Captions in current video-language pre-training and downstream datasets are spatially focused, with nouns being far more prevalent than verbs or adjectives.
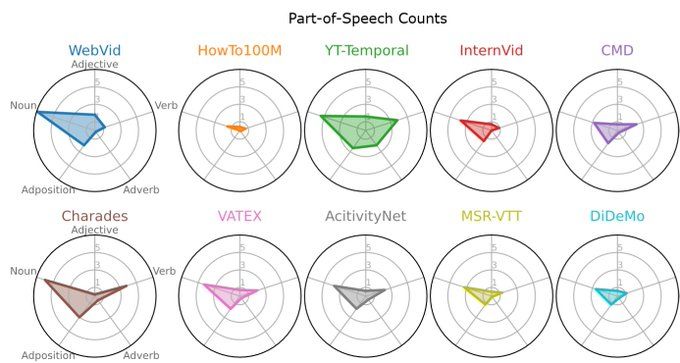
December 10, 2024 at 6:42 AM
Captions in current video-language pre-training and downstream datasets are spatially focused, with nouns being far more prevalent than verbs or adjectives.
Today we're presenting out #ACCV2024 Oral "LocoMotion: Learning Motion-Focused Video-Language Representations".
We remove the spatial focus of video-language representations and instead train representations to have a motion focus.
We remove the spatial focus of video-language representations and instead train representations to have a motion focus.

December 10, 2024 at 6:42 AM
Today we're presenting out #ACCV2024 Oral "LocoMotion: Learning Motion-Focused Video-Language Representations".
We remove the spatial focus of video-language representations and instead train representations to have a motion focus.
We remove the spatial focus of video-language representations and instead train representations to have a motion focus.