




Hazel Doughty
@hazeldoughty.bsky.social
Assistant Professor at Leiden University, NL. Computer Vision, Video Understanding.
https://hazeldoughty.github.io
https://hazeldoughty.github.io
Reposted by Hazel Doughty

Tomorrow, I’ll give a talk about future predictions in egocentric vision at the #CVPR2025 precognition workshop, in room 107A at 4pm.
I’ll retrace some history and show how precognition enables assistive downstream tasks and representation learning for procedural understanding.
I’ll retrace some history and show how precognition enables assistive downstream tasks and representation learning for procedural understanding.
June 11, 2025 at 7:35 PM
Tomorrow, I’ll give a talk about future predictions in egocentric vision at the #CVPR2025 precognition workshop, in room 107A at 4pm.
I’ll retrace some history and show how precognition enables assistive downstream tasks and representation learning for procedural understanding.
I’ll retrace some history and show how precognition enables assistive downstream tasks and representation learning for procedural understanding.
Excited to be giving a keynote at the #CVPR2025 Workshop on Interactive Video Search and Exploration (IViSE) tomorrow. I'll be sharing our efforts working towards detailed video understanding.
📅 09:45 Thursday 12th June
📍 208 A
👉 sites.google.com/view/ivise2025
📅 09:45 Thursday 12th June
📍 208 A
👉 sites.google.com/view/ivise2025
ivise-workshop.github.io
June 11, 2025 at 4:36 PM
Excited to be giving a keynote at the #CVPR2025 Workshop on Interactive Video Search and Exploration (IViSE) tomorrow. I'll be sharing our efforts working towards detailed video understanding.
📅 09:45 Thursday 12th June
📍 208 A
👉 sites.google.com/view/ivise2025
📅 09:45 Thursday 12th June
📍 208 A
👉 sites.google.com/view/ivise2025
Reposted by Hazel Doughty

Have you heard about HD-EPIC?
Attending #CVPR2025
Multiple opportunities to know about the most highly-detailed video dataset with a digital twin, long-term object tracks, VQA,…
hd-epic.github.io
1. Find any of the 10 authors attending @cvprconference.bsky.social
– identified by this badge.
🧵
Attending #CVPR2025
Multiple opportunities to know about the most highly-detailed video dataset with a digital twin, long-term object tracks, VQA,…
hd-epic.github.io
1. Find any of the 10 authors attending @cvprconference.bsky.social
– identified by this badge.
🧵

June 10, 2025 at 9:48 PM
Have you heard about HD-EPIC?
Attending #CVPR2025
Multiple opportunities to know about the most highly-detailed video dataset with a digital twin, long-term object tracks, VQA,…
hd-epic.github.io
1. Find any of the 10 authors attending @cvprconference.bsky.social
– identified by this badge.
🧵
Attending #CVPR2025
Multiple opportunities to know about the most highly-detailed video dataset with a digital twin, long-term object tracks, VQA,…
hd-epic.github.io
1. Find any of the 10 authors attending @cvprconference.bsky.social
– identified by this badge.
🧵
Reposted by Hazel Doughty
Do you want to prove your Video-Language Model understands fine-grained, long-video, 3D world or anticipates interactions?
Be the 🥇st to win HD-EPIC VQA challenge
hd-epic.github.io/index#vqa-be...
DL 19 May
Winners announced @cvprconference.bsky.social #EgoVis workshop
Be the 🥇st to win HD-EPIC VQA challenge
hd-epic.github.io/index#vqa-be...
DL 19 May
Winners announced @cvprconference.bsky.social #EgoVis workshop
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
A Highly-Detailed Egocentric Video Dataset
hd-epic.github.io
May 6, 2025 at 10:27 AM
Do you want to prove your Video-Language Model understands fine-grained, long-video, 3D world or anticipates interactions?
Be the 🥇st to win HD-EPIC VQA challenge
hd-epic.github.io/index#vqa-be...
DL 19 May
Winners announced @cvprconference.bsky.social #EgoVis workshop
Be the 🥇st to win HD-EPIC VQA challenge
hd-epic.github.io/index#vqa-be...
DL 19 May
Winners announced @cvprconference.bsky.social #EgoVis workshop
Reposted by Hazel Doughty
Object masks &tracks for HD-EPIC have been released.. This completes our highly-detailed annotations.
Also, HD-EPIC VQA challenge is open [Leaderboard closes 19 May]... can you be 1st winner?
codalab.lisn.upsaclay.fr/competitions...
Btw, HD-EPIC was accepted @cvprconference.bsky.social #CVPR2025
Also, HD-EPIC VQA challenge is open [Leaderboard closes 19 May]... can you be 1st winner?
codalab.lisn.upsaclay.fr/competitions...
Btw, HD-EPIC was accepted @cvprconference.bsky.social #CVPR2025
🛑📢
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
hd-epic.github.io
arxiv.org/abs/2502.04144
New collected videos
263 annotations/min: recipe, nutrition, actions, sounds, 3D object movement &fixture associations, masks.
26K VQA benchmark to challenge current VLMs
1/N
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
hd-epic.github.io
arxiv.org/abs/2502.04144
New collected videos
263 annotations/min: recipe, nutrition, actions, sounds, 3D object movement &fixture associations, masks.
26K VQA benchmark to challenge current VLMs
1/N
April 3, 2025 at 7:06 PM
Object masks &tracks for HD-EPIC have been released.. This completes our highly-detailed annotations.
Also, HD-EPIC VQA challenge is open [Leaderboard closes 19 May]... can you be 1st winner?
codalab.lisn.upsaclay.fr/competitions...
Btw, HD-EPIC was accepted @cvprconference.bsky.social #CVPR2025
Also, HD-EPIC VQA challenge is open [Leaderboard closes 19 May]... can you be 1st winner?
codalab.lisn.upsaclay.fr/competitions...
Btw, HD-EPIC was accepted @cvprconference.bsky.social #CVPR2025
The HD-EPIC VQA challenge for CVPR 2025 is now live: codalab.lisn.upsaclay.fr/competitions...
See how your model stacks up against Gemini and LLaVA Video on a wide range of video understanding tasks.
See how your model stacks up against Gemini and LLaVA Video on a wide range of video understanding tasks.
March 5, 2025 at 3:55 PM
The HD-EPIC VQA challenge for CVPR 2025 is now live: codalab.lisn.upsaclay.fr/competitions...
See how your model stacks up against Gemini and LLaVA Video on a wide range of video understanding tasks.
See how your model stacks up against Gemini and LLaVA Video on a wide range of video understanding tasks.
Reposted by Hazel Doughty

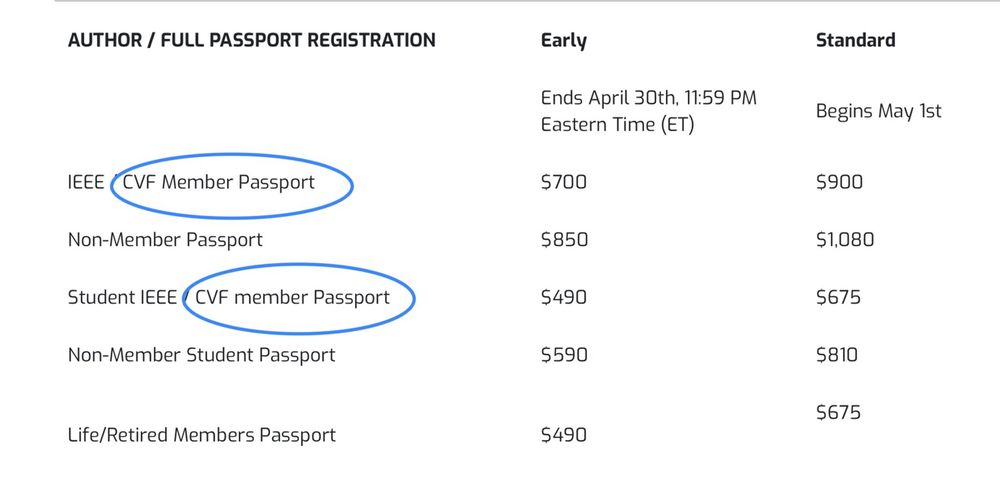
#CVPR2025 PRO TIP: To get a discount on your registration, join the Computer Vision Foundation (CVF). It’s FREE and makes @wjscheirer smile 😉
CVF: thecvf.com
CVF: thecvf.com
February 28, 2025 at 1:50 AM
#CVPR2025 PRO TIP: To get a discount on your registration, join the Computer Vision Foundation (CVF). It’s FREE and makes @wjscheirer smile 😉
CVF: thecvf.com
CVF: thecvf.com
Reposted by Hazel Doughty

HD-EPIC - hd-epic.github.io
Egocentric videos 👩🍳 with very rich annotations: the perfect testbed for many egocentric vision tasks 👌
Egocentric videos 👩🍳 with very rich annotations: the perfect testbed for many egocentric vision tasks 👌
📢 Today we're releasing a new highly detailed dataset for video understanding: HD-EPIC
arxiv.org/abs/2502.04144
hd-epic.github.io
What makes the dataset unique is the vast detail contained in the annotations with 263 annotations per minute over 41 hours of video.
arxiv.org/abs/2502.04144
hd-epic.github.io
What makes the dataset unique is the vast detail contained in the annotations with 263 annotations per minute over 41 hours of video.
February 7, 2025 at 3:26 PM
HD-EPIC - hd-epic.github.io
Egocentric videos 👩🍳 with very rich annotations: the perfect testbed for many egocentric vision tasks 👌
Egocentric videos 👩🍳 with very rich annotations: the perfect testbed for many egocentric vision tasks 👌
📢 Today we're releasing a new highly detailed dataset for video understanding: HD-EPIC
arxiv.org/abs/2502.04144
hd-epic.github.io
What makes the dataset unique is the vast detail contained in the annotations with 263 annotations per minute over 41 hours of video.
arxiv.org/abs/2502.04144
hd-epic.github.io
What makes the dataset unique is the vast detail contained in the annotations with 263 annotations per minute over 41 hours of video.
February 7, 2025 at 12:27 PM
📢 Today we're releasing a new highly detailed dataset for video understanding: HD-EPIC
arxiv.org/abs/2502.04144
hd-epic.github.io
What makes the dataset unique is the vast detail contained in the annotations with 263 annotations per minute over 41 hours of video.
arxiv.org/abs/2502.04144
hd-epic.github.io
What makes the dataset unique is the vast detail contained in the annotations with 263 annotations per minute over 41 hours of video.
Reposted by Hazel Doughty
🛑📢
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
hd-epic.github.io
arxiv.org/abs/2502.04144
New collected videos
263 annotations/min: recipe, nutrition, actions, sounds, 3D object movement &fixture associations, masks.
26K VQA benchmark to challenge current VLMs
1/N
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
hd-epic.github.io
arxiv.org/abs/2502.04144
New collected videos
263 annotations/min: recipe, nutrition, actions, sounds, 3D object movement &fixture associations, masks.
26K VQA benchmark to challenge current VLMs
1/N
February 7, 2025 at 11:45 AM
🛑📢
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
hd-epic.github.io
arxiv.org/abs/2502.04144
New collected videos
263 annotations/min: recipe, nutrition, actions, sounds, 3D object movement &fixture associations, masks.
26K VQA benchmark to challenge current VLMs
1/N
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
hd-epic.github.io
arxiv.org/abs/2502.04144
New collected videos
263 annotations/min: recipe, nutrition, actions, sounds, 3D object movement &fixture associations, masks.
26K VQA benchmark to challenge current VLMs
1/N
Our second #ACCV2024 oral: "Beyond Coarse-Grained Matching in Video-Text Retrieval" is also being presented today.
ArXiv: arxiv.org/abs/2410.12407
We go beyond coarse-grained retrieval and explore whether models can discern subtle single-word differences in captions.
ArXiv: arxiv.org/abs/2410.12407
We go beyond coarse-grained retrieval and explore whether models can discern subtle single-word differences in captions.

December 10, 2024 at 6:46 AM
Our second #ACCV2024 oral: "Beyond Coarse-Grained Matching in Video-Text Retrieval" is also being presented today.
ArXiv: arxiv.org/abs/2410.12407
We go beyond coarse-grained retrieval and explore whether models can discern subtle single-word differences in captions.
ArXiv: arxiv.org/abs/2410.12407
We go beyond coarse-grained retrieval and explore whether models can discern subtle single-word differences in captions.
Today we're presenting out #ACCV2024 Oral "LocoMotion: Learning Motion-Focused Video-Language Representations".
We remove the spatial focus of video-language representations and instead train representations to have a motion focus.
We remove the spatial focus of video-language representations and instead train representations to have a motion focus.

December 10, 2024 at 6:42 AM
Today we're presenting out #ACCV2024 Oral "LocoMotion: Learning Motion-Focused Video-Language Representations".
We remove the spatial focus of video-language representations and instead train representations to have a motion focus.
We remove the spatial focus of video-language representations and instead train representations to have a motion focus.
Reposted by Hazel Doughty
Pls RT
Permanent Assistant Professor (Lecturer) position in Computer Vision @bristoluni.bsky.social [DL 6 Jan 2025]
This is a research+teaching permanent post within MaVi group uob-mavi.github.io in Computer Science. Suitable for strong postdocs or exceptional PhD graduates.
t.co/k7sRRyfx9o
1/2
Permanent Assistant Professor (Lecturer) position in Computer Vision @bristoluni.bsky.social [DL 6 Jan 2025]
This is a research+teaching permanent post within MaVi group uob-mavi.github.io in Computer Science. Suitable for strong postdocs or exceptional PhD graduates.
t.co/k7sRRyfx9o
1/2
https://tinyurl.com/BristolCVLectureship
t.co
December 4, 2024 at 5:22 PM
Pls RT
Permanent Assistant Professor (Lecturer) position in Computer Vision @bristoluni.bsky.social [DL 6 Jan 2025]
This is a research+teaching permanent post within MaVi group uob-mavi.github.io in Computer Science. Suitable for strong postdocs or exceptional PhD graduates.
t.co/k7sRRyfx9o
1/2
Permanent Assistant Professor (Lecturer) position in Computer Vision @bristoluni.bsky.social [DL 6 Jan 2025]
This is a research+teaching permanent post within MaVi group uob-mavi.github.io in Computer Science. Suitable for strong postdocs or exceptional PhD graduates.
t.co/k7sRRyfx9o
1/2