



Xi Fu
@fuxialexander.bsky.social
Transcription regulation; deep learning; (bad) developer
My friend tried to ask what are some well known gene in Chr10/etc and guess what…
May 5, 2025 at 10:47 PM
My friend tried to ask what are some well known gene in Chr10/etc and guess what…
much better with GPT

March 26, 2025 at 11:51 PM
much better with GPT
Looks like a Tesla logo 😈 (I'm sorry...)
March 18, 2025 at 5:48 PM
Looks like a Tesla logo 😈 (I'm sorry...)
Sorry for missing the final part of the first sentence:
...explained by known motifs of its own (increased overall affinity) or other TF (thus representing TF-TF interaction/cooperation), *or some other unknown factors*
...explained by known motifs of its own (increased overall affinity) or other TF (thus representing TF-TF interaction/cooperation), *or some other unknown factors*
February 12, 2025 at 11:04 PM
Sorry for missing the final part of the first sentence:
...explained by known motifs of its own (increased overall affinity) or other TF (thus representing TF-TF interaction/cooperation), *or some other unknown factors*
...explained by known motifs of its own (increased overall affinity) or other TF (thus representing TF-TF interaction/cooperation), *or some other unknown factors*
can't fit it in tweet and sorry for the formatting...

February 12, 2025 at 11:01 PM
can't fit it in tweet and sorry for the formatting...
The rest of the GC tracks might be more related to the 1D search/hopping hypothesis of TF binding as they seems to be less similar to the motif (unless those are for KLF/SP)
February 12, 2025 at 10:38 PM
The rest of the GC tracks might be more related to the 1D search/hopping hypothesis of TF binding as they seems to be less similar to the motif (unless those are for KLF/SP)
it seems in this case, part of the context (~52-57) is a reverse complement of CAGC, resembles part of the less informative flanking (40-45) of the core GATAA/TTATC motif. I guess I would consider this still a “known motif” as probably it’s from some weaker DBD-DNA interaction
February 12, 2025 at 10:38 PM
it seems in this case, part of the context (~52-57) is a reverse complement of CAGC, resembles part of the less informative flanking (40-45) of the core GATAA/TTATC motif. I guess I would consider this still a “known motif” as probably it’s from some weaker DBD-DNA interaction
How many information on the ledidi edit matrix can be explained by known motifs (of the TF itself or other TF)? Kind of confused right now on the role of context region in determine binding activities…
February 12, 2025 at 9:33 PM
How many information on the ledidi edit matrix can be explained by known motifs (of the TF itself or other TF)? Kind of confused right now on the role of context region in determine binding activities…
Reposted by Xi Fu

Deep learning models (@chromozz.bsky.social) trained only on yeast chromosomes predict nucleosome positioning, RNA Poll II and cohesin tracks along foreign DNA, based on the sequence alone. This implies that the behavior of any DNA in a host cell follows deterministic sequence-based rules.

February 7, 2025 at 10:22 AM
Deep learning models (@chromozz.bsky.social) trained only on yeast chromosomes predict nucleosome positioning, RNA Poll II and cohesin tracks along foreign DNA, based on the sequence alone. This implies that the behavior of any DNA in a host cell follows deterministic sequence-based rules.
One probably one can also do that with MSA or even dig into bowtie-index file though 😂
February 5, 2025 at 2:04 PM
One probably one can also do that with MSA or even dig into bowtie-index file though 😂
I believe one usage of the gLMs that truly align with it's training goal is discovery of DNA-binding proteins: train on many species, ideally jointly with (compressed) protein embeddings; identify overrepresented kmers specifically in certain clade; followed by massive oligomer-pulldown screening
February 5, 2025 at 2:00 PM
I believe one usage of the gLMs that truly align with it's training goal is discovery of DNA-binding proteins: train on many species, ideally jointly with (compressed) protein embeddings; identify overrepresented kmers specifically in certain clade; followed by massive oligomer-pulldown screening
This looks like a python/scipy numerical lower bond. Sometimes I see R-based methods give much more floating digits. Has been curious what's the implementation difference.
February 1, 2025 at 4:31 PM
This looks like a python/scipy numerical lower bond. Sometimes I see R-based methods give much more floating digits. Has been curious what's the implementation difference.
Reposted by Xi Fu

Lars Steinmetz and @seczmarta.bsky.social put together a wonderful perspective on these two studies. www.science.org/doi/10.1126/...
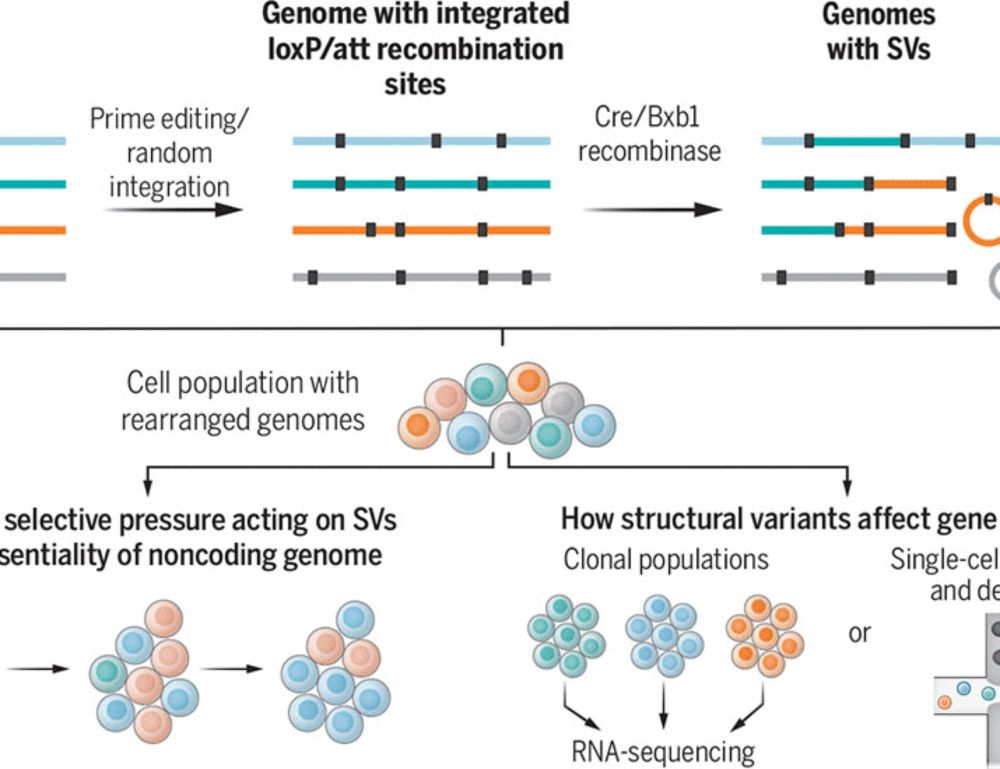
Genome recombination on demand
Large genome rearrangements in mammalian cells can be generated at scale
www.science.org
January 31, 2025 at 1:49 PM
Lars Steinmetz and @seczmarta.bsky.social put together a wonderful perspective on these two studies. www.science.org/doi/10.1126/...