



Filippo Stocco
@filippostocco.bsky.social
Reposted by Filippo Stocco

🧬🧬🧬 New review from the lab:
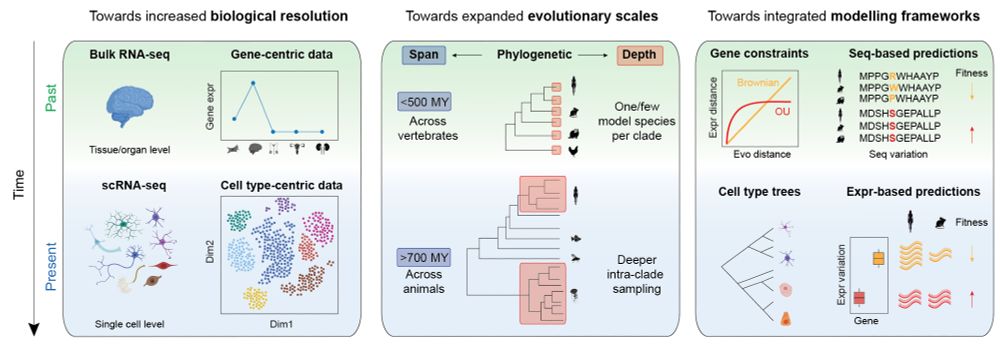
Evolution of comparative transcriptomics: biological scales, phylogenetic spans, and modeling frameworks
authors.elsevier.com/sd/article/S...
By @mattezambon.bsky.social & @fedemantica.bsky.social, together with @jonnyfrazer.bsky.social & Mafalda Dias.
Evolution of comparative transcriptomics: biological scales, phylogenetic spans, and modeling frameworks
authors.elsevier.com/sd/article/S...
By @mattezambon.bsky.social & @fedemantica.bsky.social, together with @jonnyfrazer.bsky.social & Mafalda Dias.
August 6, 2025 at 9:16 AM
🧬🧬🧬 New review from the lab:
Evolution of comparative transcriptomics: biological scales, phylogenetic spans, and modeling frameworks
authors.elsevier.com/sd/article/S...
By @mattezambon.bsky.social & @fedemantica.bsky.social, together with @jonnyfrazer.bsky.social & Mafalda Dias.
Evolution of comparative transcriptomics: biological scales, phylogenetic spans, and modeling frameworks
authors.elsevier.com/sd/article/S...
By @mattezambon.bsky.social & @fedemantica.bsky.social, together with @jonnyfrazer.bsky.social & Mafalda Dias.
Reposted by Filippo Stocco

MMseqs2 v18 is out
- SIMD FW/BW alignment (preprint soon!)
- Sub. Mat. λ calculator by Eric Dawson
- Faster ARM SW by Alexander Nesterovskiy
- MSA-Pairformer’s proximity-based pairing for multimer prediction (www.biorxiv.org/content/10.1...; avail. in ColabFold API)
💾 github.com/soedinglab/M... & 🐍
- SIMD FW/BW alignment (preprint soon!)
- Sub. Mat. λ calculator by Eric Dawson
- Faster ARM SW by Alexander Nesterovskiy
- MSA-Pairformer’s proximity-based pairing for multimer prediction (www.biorxiv.org/content/10.1...; avail. in ColabFold API)
💾 github.com/soedinglab/M... & 🐍

August 5, 2025 at 8:25 AM
MMseqs2 v18 is out
- SIMD FW/BW alignment (preprint soon!)
- Sub. Mat. λ calculator by Eric Dawson
- Faster ARM SW by Alexander Nesterovskiy
- MSA-Pairformer’s proximity-based pairing for multimer prediction (www.biorxiv.org/content/10.1...; avail. in ColabFold API)
💾 github.com/soedinglab/M... & 🐍
- SIMD FW/BW alignment (preprint soon!)
- Sub. Mat. λ calculator by Eric Dawson
- Faster ARM SW by Alexander Nesterovskiy
- MSA-Pairformer’s proximity-based pairing for multimer prediction (www.biorxiv.org/content/10.1...; avail. in ColabFold API)
💾 github.com/soedinglab/M... & 🐍
Reposted by Filippo Stocco
Stay tuned for details on the 6th edition of MLSB, officially happening this December in downtown San Diego, CA!

The MLSB workshop will be in San Diego, CA (co-located with NeurIPS) this year for its 6th edition in December 🧬🔬
Stay tuned @workshopmlsb.bsky.social as we share details about the stellar lineup of speakers, the official call for papers, and other announcements!🌟
Stay tuned @workshopmlsb.bsky.social as we share details about the stellar lineup of speakers, the official call for papers, and other announcements!🌟

July 28, 2025 at 3:41 PM
Stay tuned for details on the 6th edition of MLSB, officially happening this December in downtown San Diego, CA!
Reposted by Filippo Stocco

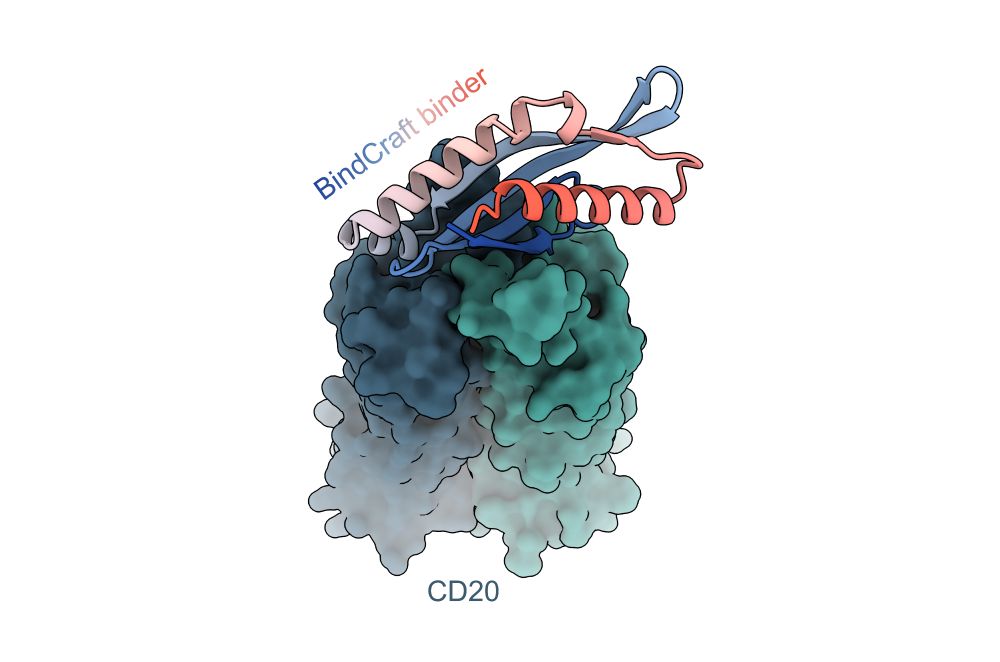
We have written up a tutorial on how to run BindCraft, how to prepare your input PDB, how to select hotspots, and various other tips and tricks to get the most out of binder design!
github.com/martinpacesa...
github.com/martinpacesa...
June 30, 2025 at 7:45 PM
We have written up a tutorial on how to run BindCraft, how to prepare your input PDB, how to select hotspots, and various other tips and tricks to get the most out of binder design!
github.com/martinpacesa...
github.com/martinpacesa...
It’s never been easier to align your protein language model (pLM)!
We’ve released a major update to our ProtRL repo:
✅ GRPO via Hugging Face Trainer
✅ New support for weighted DPO
Built for flexible, scalable RL with HF trainer base!
Check here: github.com/AI4PDLab/Pro...
We’ve released a major update to our ProtRL repo:
✅ GRPO via Hugging Face Trainer
✅ New support for weighted DPO
Built for flexible, scalable RL with HF trainer base!
Check here: github.com/AI4PDLab/Pro...

June 25, 2025 at 3:30 PM
It’s never been easier to align your protein language model (pLM)!
We’ve released a major update to our ProtRL repo:
✅ GRPO via Hugging Face Trainer
✅ New support for weighted DPO
Built for flexible, scalable RL with HF trainer base!
Check here: github.com/AI4PDLab/Pro...
We’ve released a major update to our ProtRL repo:
✅ GRPO via Hugging Face Trainer
✅ New support for weighted DPO
Built for flexible, scalable RL with HF trainer base!
Check here: github.com/AI4PDLab/Pro...
Reposted by Filippo Stocco

In our newest preprint, we discuss current explainable AI (XAI) methods. We divided the workflow of a generative decoder-only model into four information contexts for XAI: training dataset, input query, model components, and output sequence. See here: arxiv.org/abs/2506.19532
@aichemist.bsky.social
@aichemist.bsky.social

June 25, 2025 at 11:37 AM
In our newest preprint, we discuss current explainable AI (XAI) methods. We divided the workflow of a generative decoder-only model into four information contexts for XAI: training dataset, input query, model components, and output sequence. See here: arxiv.org/abs/2506.19532
@aichemist.bsky.social
@aichemist.bsky.social
Reposted by Filippo Stocco

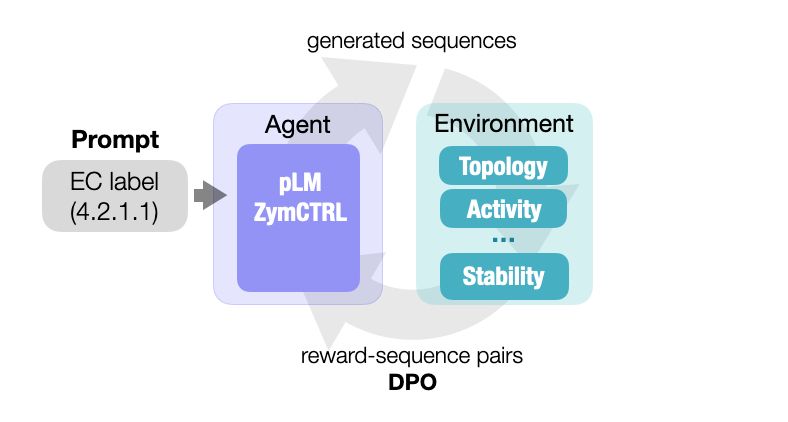
Protein language models excel at generating functional yet remarkably diverse artificial sequences.
They however fail to naturally sample rare datapoints, like very high activities.
In our new preprint, we show that RL can solve this without the need for additional data:
arxiv.org/abs/2412.12979
They however fail to naturally sample rare datapoints, like very high activities.
In our new preprint, we show that RL can solve this without the need for additional data:
arxiv.org/abs/2412.12979
December 18, 2024 at 9:06 PM
Protein language models excel at generating functional yet remarkably diverse artificial sequences.
They however fail to naturally sample rare datapoints, like very high activities.
In our new preprint, we show that RL can solve this without the need for additional data:
arxiv.org/abs/2412.12979
They however fail to naturally sample rare datapoints, like very high activities.
In our new preprint, we show that RL can solve this without the need for additional data:
arxiv.org/abs/2412.12979