




Claudio Fanconi
@fanconic.bsky.social
Please insert pretentious things about myself here:
PhD student in Machine Learning @ University of Cambridge | Previously MSc & Bsc @ ETH Zürich
fanconic.github.io
PhD student in Machine Learning @ University of Cambridge | Previously MSc & Bsc @ ETH Zürich
fanconic.github.io
Our paper from the ICML 2025 workshop on Multi-Agent Systems explores a cascaded LLM framework for cost-effective decision-making. Small models defer to larger ones—or abstain for human input—based on uncertainty.
Paper: arxiv.org/abs/2506.11887
#LLM #MultiAgent #ICML2025
Paper: arxiv.org/abs/2506.11887
#LLM #MultiAgent #ICML2025

July 21, 2025 at 12:05 PM
Our paper from the ICML 2025 workshop on Multi-Agent Systems explores a cascaded LLM framework for cost-effective decision-making. Small models defer to larger ones—or abstain for human input—based on uncertainty.
Paper: arxiv.org/abs/2506.11887
#LLM #MultiAgent #ICML2025
Paper: arxiv.org/abs/2506.11887
#LLM #MultiAgent #ICML2025
Our paper from the ICML 2025 workshop on Models of Human Feedback (Oral presentation) proposes few-shot steerable alignment for LLMs, utilising neural processes to handle conflicting and unobserved preferences.
Paper: arxiv.org/abs/2412.13998
#LLM #AIAlignment #ICML2025
Paper: arxiv.org/abs/2412.13998
#LLM #AIAlignment #ICML2025

July 21, 2025 at 12:02 PM
Our paper from the ICML 2025 workshop on Models of Human Feedback (Oral presentation) proposes few-shot steerable alignment for LLMs, utilising neural processes to handle conflicting and unobserved preferences.
Paper: arxiv.org/abs/2412.13998
#LLM #AIAlignment #ICML2025
Paper: arxiv.org/abs/2412.13998
#LLM #AIAlignment #ICML2025
To all NeurIPS warriors out there, good luck with the final sprint. Just one more day, we got this! :)
May 15, 2025 at 8:37 AM
To all NeurIPS warriors out there, good luck with the final sprint. Just one more day, we got this! :)
Reposted by Claudio Fanconi

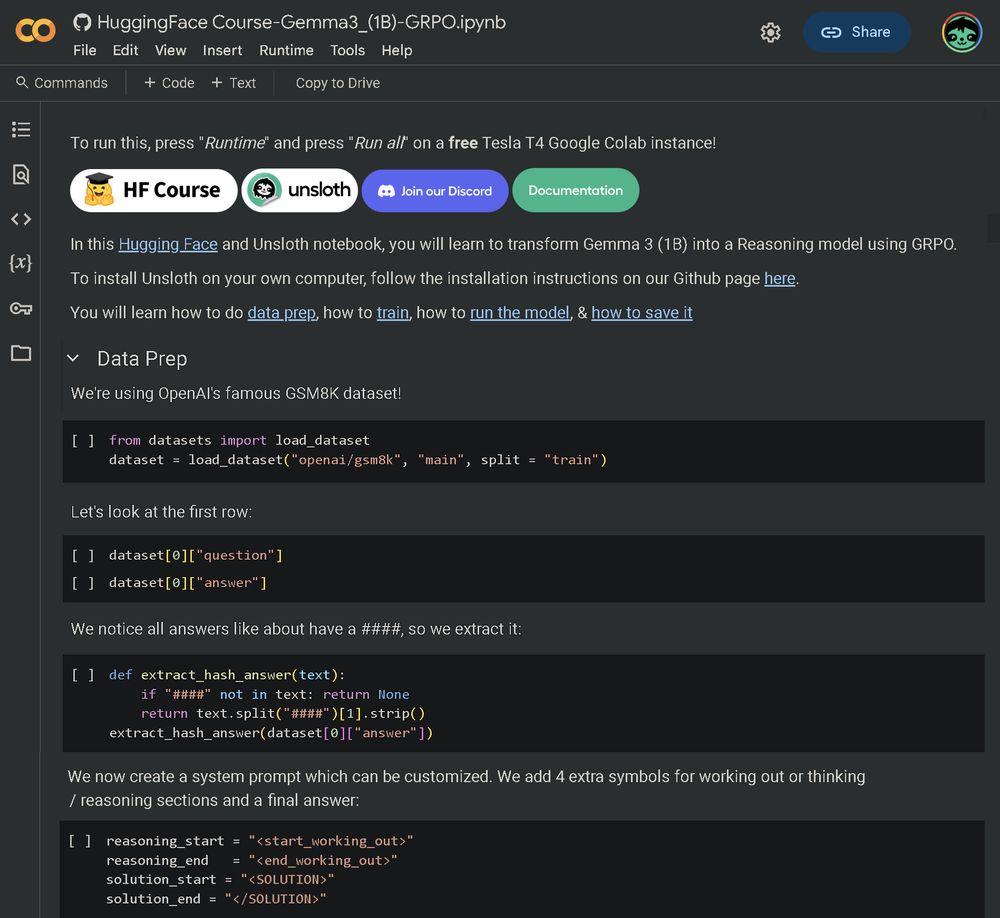
We teamed up with 🤗Hugging Face to release a free notebook for fine-tuning Gemma 3 with GRPO
Learn to:
• Enable reasoning in Gemma 3 (1B)
• Prepare/understand reward functions
• Make GRPO work for tiny LLMs
Notebook: colab.research.google.com/github/unslo...
Details: huggingface.co/reasoning-co...
Learn to:
• Enable reasoning in Gemma 3 (1B)
• Prepare/understand reward functions
• Make GRPO work for tiny LLMs
Notebook: colab.research.google.com/github/unslo...
Details: huggingface.co/reasoning-co...
March 19, 2025 at 4:31 PM
We teamed up with 🤗Hugging Face to release a free notebook for fine-tuning Gemma 3 with GRPO
Learn to:
• Enable reasoning in Gemma 3 (1B)
• Prepare/understand reward functions
• Make GRPO work for tiny LLMs
Notebook: colab.research.google.com/github/unslo...
Details: huggingface.co/reasoning-co...
Learn to:
• Enable reasoning in Gemma 3 (1B)
• Prepare/understand reward functions
• Make GRPO work for tiny LLMs
Notebook: colab.research.google.com/github/unslo...
Details: huggingface.co/reasoning-co...
Have a listen to Chris and Robert speak about our DiscoPOP paper (arxiv.org/abs/2406.08414) in the Machine Learning Street Talk (MLST) Podcast:
youtube.com/watch?v=1kwb...
youtube.com/watch?v=1kwb...

Can AI Improve Itself?
YouTube video by Machine Learning Street Talk
youtube.com
March 9, 2025 at 12:33 PM
Have a listen to Chris and Robert speak about our DiscoPOP paper (arxiv.org/abs/2406.08414) in the Machine Learning Street Talk (MLST) Podcast:
youtube.com/watch?v=1kwb...
youtube.com/watch?v=1kwb...
Reposted by Claudio Fanconi

dolphin-r1: a dataset for training R1-style models
- 800k total samples dataset similar in composition to the data used to train DeepSeek-R1 Distill models.
- 300k from DeepSeek-R1
- 300k from Gemini 2.0 flash thinking
- 200k from Dolphin chat
huggingface.co/datasets/cog...
- 800k total samples dataset similar in composition to the data used to train DeepSeek-R1 Distill models.
- 300k from DeepSeek-R1
- 300k from Gemini 2.0 flash thinking
- 200k from Dolphin chat
huggingface.co/datasets/cog...

cognitivecomputations/dolphin-r1 · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
January 30, 2025 at 9:21 AM
dolphin-r1: a dataset for training R1-style models
- 800k total samples dataset similar in composition to the data used to train DeepSeek-R1 Distill models.
- 300k from DeepSeek-R1
- 300k from Gemini 2.0 flash thinking
- 200k from Dolphin chat
huggingface.co/datasets/cog...
- 800k total samples dataset similar in composition to the data used to train DeepSeek-R1 Distill models.
- 300k from DeepSeek-R1
- 300k from Gemini 2.0 flash thinking
- 200k from Dolphin chat
huggingface.co/datasets/cog...
Hot take: High-Flyer (the quant shop behind DeepSeek) orchestrated the release and hype of DeepSeek-R1 carefully, and made the big bugs today with shorts on NVDA🤑
January 27, 2025 at 9:09 PM
Hot take: High-Flyer (the quant shop behind DeepSeek) orchestrated the release and hype of DeepSeek-R1 carefully, and made the big bugs today with shorts on NVDA🤑
Reposted by Claudio Fanconi

huggingface is doing a fully open source replication of R1 github.com/huggingface/...

GitHub - huggingface/open-r1: Fully open reproduction of DeepSeek-R1
Fully open reproduction of DeepSeek-R1. Contribute to huggingface/open-r1 development by creating an account on GitHub.
github.com
January 25, 2025 at 2:31 PM
huggingface is doing a fully open source replication of R1 github.com/huggingface/...
Reposted by Claudio Fanconi

LM agents today primarily aim to automate tasks. Can we turn them into collaborative teammates? 🤖➕👤
Introducing Collaborative Gym (Co-Gym), a framework for enabling & evaluating human-agent collaboration! I now get used to agents proactively seeking confirmations or my deep thinking.(🧵 with video)
Introducing Collaborative Gym (Co-Gym), a framework for enabling & evaluating human-agent collaboration! I now get used to agents proactively seeking confirmations or my deep thinking.(🧵 with video)

January 17, 2025 at 5:44 PM
LM agents today primarily aim to automate tasks. Can we turn them into collaborative teammates? 🤖➕👤
Introducing Collaborative Gym (Co-Gym), a framework for enabling & evaluating human-agent collaboration! I now get used to agents proactively seeking confirmations or my deep thinking.(🧵 with video)
Introducing Collaborative Gym (Co-Gym), a framework for enabling & evaluating human-agent collaboration! I now get used to agents proactively seeking confirmations or my deep thinking.(🧵 with video)
Reposted by Claudio Fanconi

Qwen released a 72B process reward model (PRM) on their recent math model. A good chance it's the best PRM openly available for reasoning research. We like Qwen.
https://buff.ly/4gQV9wt
https://buff.ly/4gQV9wt

January 14, 2025 at 3:56 AM
Qwen released a 72B process reward model (PRM) on their recent math model. A good chance it's the best PRM openly available for reasoning research. We like Qwen.
https://buff.ly/4gQV9wt
https://buff.ly/4gQV9wt
Reposted by Claudio Fanconi


Reposted by Claudio Fanconi
Here are the slides for our language modeling tutorial with @kylelo.bsky.social and @akshitab.bsky.social in west ballroom b (ongoing).
docs.google.com/presentation...
docs.google.com/presentation...

[10 December 2024, NeurIPs] Tutorial on Language Modeling
Language Modeling Kyle Lo – Akshita Bhagia – Nathan Lambert Allen Institute of AI olmo@allenai.org Neural Information Processing Systems (NeurIPS) 10 December 2024 1
docs.google.com
December 10, 2024 at 6:29 PM
Here are the slides for our language modeling tutorial with @kylelo.bsky.social and @akshitab.bsky.social in west ballroom b (ongoing).
docs.google.com/presentation...
docs.google.com/presentation...
I am at #NeurIPS this week, and presenting our poster "Discovering Preference Optimization Algorithms with and for Large Language Models" on Thursday at East Exhibit Hall A-C #3304.
Let me know if you want to chat about alignment, LLMs, and AI applications in medicine!
arxiv.org/abs/2406.08414
Let me know if you want to chat about alignment, LLMs, and AI applications in medicine!
arxiv.org/abs/2406.08414

Discovering Preference Optimization Algorithms with and for Large Language Models
Offline preference optimization is a key method for enhancing and controlling the quality of Large Language Model (LLM) outputs. Typically, preference optimization is approached as an offline supervis...
arxiv.org
December 10, 2024 at 4:23 PM
I am at #NeurIPS this week, and presenting our poster "Discovering Preference Optimization Algorithms with and for Large Language Models" on Thursday at East Exhibit Hall A-C #3304.
Let me know if you want to chat about alignment, LLMs, and AI applications in medicine!
arxiv.org/abs/2406.08414
Let me know if you want to chat about alignment, LLMs, and AI applications in medicine!
arxiv.org/abs/2406.08414
Reposted by Claudio Fanconi

Ok, it is yesterdays news already, but good night sleep is important.
After 7 amazing years at Google Brain/DM, I am joining OpenAI. Together with @xzhai.bsky.social and @giffmana.ai, we will establish OpenAI Zurich office. Proud of our past work and looking forward to the future.
After 7 amazing years at Google Brain/DM, I am joining OpenAI. Together with @xzhai.bsky.social and @giffmana.ai, we will establish OpenAI Zurich office. Proud of our past work and looking forward to the future.
December 4, 2024 at 9:14 AM
Ok, it is yesterdays news already, but good night sleep is important.
After 7 amazing years at Google Brain/DM, I am joining OpenAI. Together with @xzhai.bsky.social and @giffmana.ai, we will establish OpenAI Zurich office. Proud of our past work and looking forward to the future.
After 7 amazing years at Google Brain/DM, I am joining OpenAI. Together with @xzhai.bsky.social and @giffmana.ai, we will establish OpenAI Zurich office. Proud of our past work and looking forward to the future.
Reposted by Claudio Fanconi

How do LLMs learn to reason from data? Are they ~retrieving the answers from parametric knowledge🦜? In our new preprint, we look at the pretraining data and find evidence against this:
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
November 20, 2024 at 4:35 PM
How do LLMs learn to reason from data? Are they ~retrieving the answers from parametric knowledge🦜? In our new preprint, we look at the pretraining data and find evidence against this:
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
Reposted by Claudio Fanconi

Excited to share our #NeurIPS 2024 Oral, Convolutional Differentiable Logic Gate Networks, leading to a range of inference efficiency records, including inference in only 4 nanoseconds 🏎️. We reduce model sizes by factors of 29x-61x over the SOTA. Paper: arxiv.org/abs/2411.04732
November 17, 2024 at 4:34 PM
Excited to share our #NeurIPS 2024 Oral, Convolutional Differentiable Logic Gate Networks, leading to a range of inference efficiency records, including inference in only 4 nanoseconds 🏎️. We reduce model sizes by factors of 29x-61x over the SOTA. Paper: arxiv.org/abs/2411.04732
🎉First #NeurIPS paper: We used LLMs to discover new preference optimization algorithms through evolution - they propose code, train a separate LLM & use the performance feedback to improve. After some generations, it found multiple novel, high-performing objective functions! arxiv.org/pdf/2406.08414
November 25, 2024 at 2:05 PM
🎉First #NeurIPS paper: We used LLMs to discover new preference optimization algorithms through evolution - they propose code, train a separate LLM & use the performance feedback to improve. After some generations, it found multiple novel, high-performing objective functions! arxiv.org/pdf/2406.08414
Reposted by Claudio Fanconi

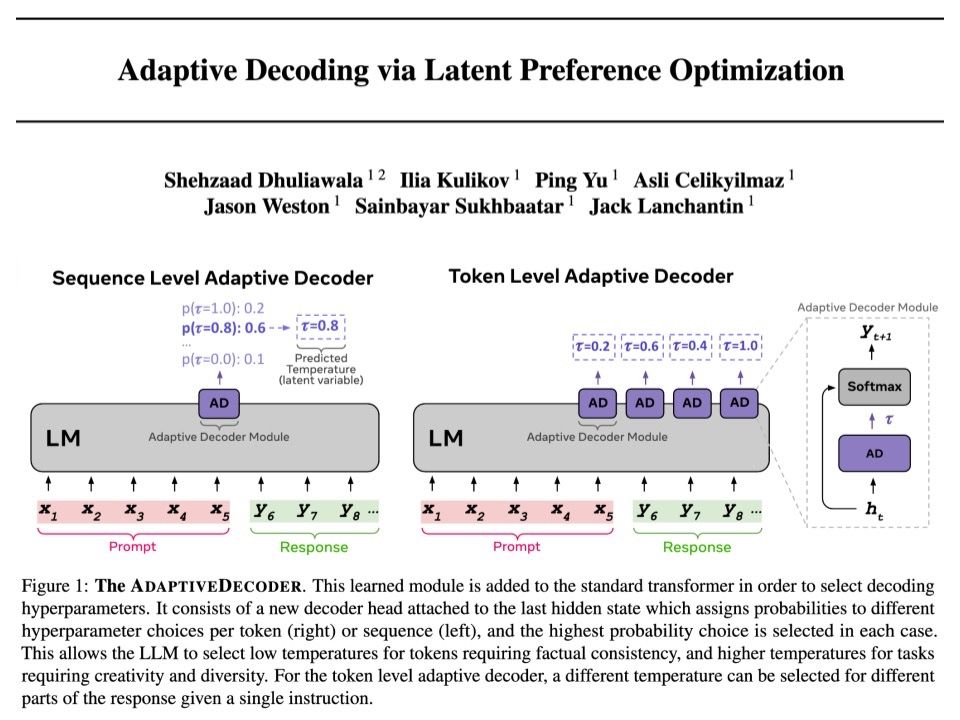
🚨 Adaptive Decoding via Latent Preference Optimization 🚨
- New layer for Transformer, selects decoding params automatically *per token*
- Learnt via new method Latent Preference Optimization
- Outperforms any fixed temperature decoding, choosing creativity or factuality
arxiv.org/abs/2411.09661
🧵1/4
- New layer for Transformer, selects decoding params automatically *per token*
- Learnt via new method Latent Preference Optimization
- Outperforms any fixed temperature decoding, choosing creativity or factuality
arxiv.org/abs/2411.09661
🧵1/4
November 22, 2024 at 1:06 PM
🚨 Adaptive Decoding via Latent Preference Optimization 🚨
- New layer for Transformer, selects decoding params automatically *per token*
- Learnt via new method Latent Preference Optimization
- Outperforms any fixed temperature decoding, choosing creativity or factuality
arxiv.org/abs/2411.09661
🧵1/4
- New layer for Transformer, selects decoding params automatically *per token*
- Learnt via new method Latent Preference Optimization
- Outperforms any fixed temperature decoding, choosing creativity or factuality
arxiv.org/abs/2411.09661
🧵1/4
Reposted by Claudio Fanconi

LLMs generate novel word sequences not contained in their pretraining data. However, compared to humans, models generate significantly fewer novel n-grams.
RLHF = 30% *more* copying than base!
Awesome work from the awesome Ximing Lu (gloriaximinglu.github.io) et al. 🤩
arxiv.org/pdf/2410.04265
RLHF = 30% *more* copying than base!
Awesome work from the awesome Ximing Lu (gloriaximinglu.github.io) et al. 🤩
arxiv.org/pdf/2410.04265

November 22, 2024 at 6:14 AM
LLMs generate novel word sequences not contained in their pretraining data. However, compared to humans, models generate significantly fewer novel n-grams.
RLHF = 30% *more* copying than base!
Awesome work from the awesome Ximing Lu (gloriaximinglu.github.io) et al. 🤩
arxiv.org/pdf/2410.04265
RLHF = 30% *more* copying than base!
Awesome work from the awesome Ximing Lu (gloriaximinglu.github.io) et al. 🤩
arxiv.org/pdf/2410.04265