



Daniel Vila
@dvilasuero.hf.co
Everything datasets and human feedback for AI at Hugging Face.
Prev: co-founder and CEO of Argilla (acquired by Hugging Face)
Prev: co-founder and CEO of Argilla (acquired by Hugging Face)
Reposted by Daniel Vila

🚀 The open source community is unstoppable: 4M total downloads for DeepSeek models on @hf.co , with 3.2M coming from the +600 models created by the community. That's 30% more than yesterday!

January 28, 2025 at 5:55 PM
🚀 The open source community is unstoppable: 4M total downloads for DeepSeek models on @hf.co , with 3.2M coming from the +600 models created by the community. That's 30% more than yesterday!
Reposted by Daniel Vila

💫 Generate RAG data with the Synthetic Data Generator to improve your RAG system!
1️⃣ Generate from your documents, dataset, or dataset description.
2️⃣ Configure it.
3️⃣ Generate the synthetic dataset.
4️⃣ Fine-tune the retrieval and reranking models.
5️⃣ Build a RAG pipeline.
1️⃣ Generate from your documents, dataset, or dataset description.
2️⃣ Configure it.
3️⃣ Generate the synthetic dataset.
4️⃣ Fine-tune the retrieval and reranking models.
5️⃣ Build a RAG pipeline.
January 20, 2025 at 4:42 PM
💫 Generate RAG data with the Synthetic Data Generator to improve your RAG system!
1️⃣ Generate from your documents, dataset, or dataset description.
2️⃣ Configure it.
3️⃣ Generate the synthetic dataset.
4️⃣ Fine-tune the retrieval and reranking models.
5️⃣ Build a RAG pipeline.
1️⃣ Generate from your documents, dataset, or dataset description.
2️⃣ Configure it.
3️⃣ Generate the synthetic dataset.
4️⃣ Fine-tune the retrieval and reranking models.
5️⃣ Build a RAG pipeline.
Reposted by Daniel Vila

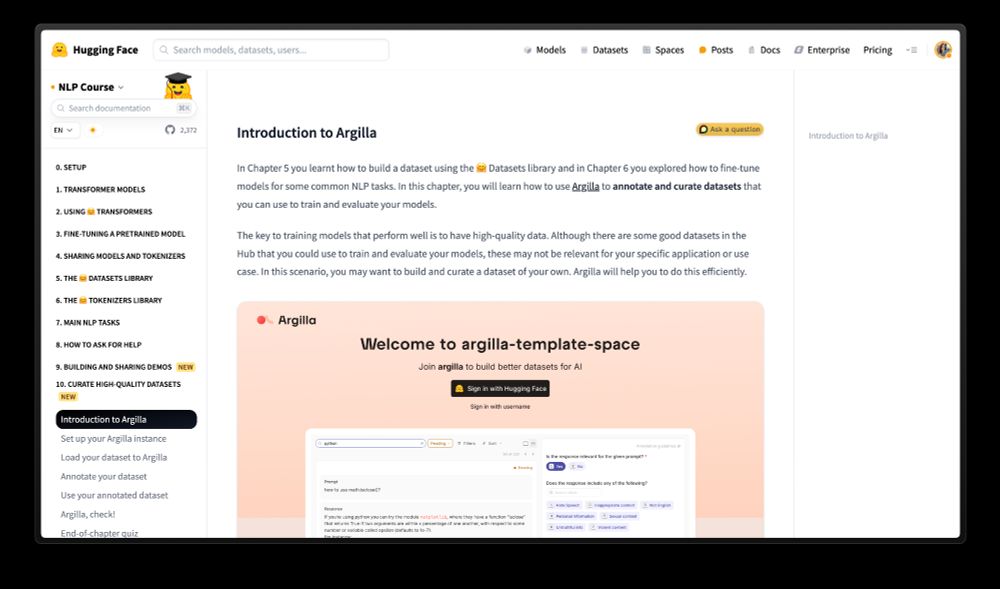
New chapter in the Hugging Face NLP course! 🤗 🚀
We've added a new chapter about the very basics of Argilla to the Hugging Face NLP course. Learn how to set up an Argilla instance, load & annotate datasets, and export them to the Hub.
Any feedback for improvements welcome!
We've added a new chapter about the very basics of Argilla to the Hugging Face NLP course. Learn how to set up an Argilla instance, load & annotate datasets, and export them to the Hub.
Any feedback for improvements welcome!
January 17, 2025 at 10:02 AM
New chapter in the Hugging Face NLP course! 🤗 🚀
We've added a new chapter about the very basics of Argilla to the Hugging Face NLP course. Learn how to set up an Argilla instance, load & annotate datasets, and export them to the Hub.
Any feedback for improvements welcome!
We've added a new chapter about the very basics of Argilla to the Hugging Face NLP course. Learn how to set up an Argilla instance, load & annotate datasets, and export them to the Hub.
Any feedback for improvements welcome!
Reposted by Daniel Vila

🎉 50,000+ annotations reached! The FineWeb2-C community is helping build better language models on annotation at a time.
📊 Current stats:
- 115 languages represented
- 419 amazing contributors
- 24 languages with complete datasets
But we're not done yet! 🧵
📊 Current stats:
- 115 languages represented
- 419 amazing contributors
- 24 languages with complete datasets
But we're not done yet! 🧵

January 16, 2025 at 5:32 PM
🎉 50,000+ annotations reached! The FineWeb2-C community is helping build better language models on annotation at a time.
📊 Current stats:
- 115 languages represented
- 419 amazing contributors
- 24 languages with complete datasets
But we're not done yet! 🧵
📊 Current stats:
- 115 languages represented
- 419 amazing contributors
- 24 languages with complete datasets
But we're not done yet! 🧵
Reposted by Daniel Vila

High-quality data for fine-tuning language models for free and at the click of a button!
Prompt and wait for your dataset to push to Argilla or the Hub
Evaluate, review and fine-tune a model.
Blog:
Prompt and wait for your dataset to push to Argilla or the Hub
Evaluate, review and fine-tune a model.
Blog:

Fine-tune a SmolLM on domain-specific synthetic data from a LLM
A Blog post by David Berenstein on Hugging Face
buff.ly
January 7, 2025 at 1:00 PM
High-quality data for fine-tuning language models for free and at the click of a button!
Prompt and wait for your dataset to push to Argilla or the Hub
Evaluate, review and fine-tune a model.
Blog:
Prompt and wait for your dataset to push to Argilla or the Hub
Evaluate, review and fine-tune a model.
Blog:
Reposted by Daniel Vila
Was 2024 the year of datasets? Is 2025 the year for community-built datasets?
It's exciting to see the progress of many languages in FineWeb-C:
- Total annotations submitted: 41,577
- Languages with annotations: 106
- Total contributors: 363
It's exciting to see the progress of many languages in FineWeb-C:
- Total annotations submitted: 41,577
- Languages with annotations: 106
- Total contributors: 363
January 3, 2025 at 12:00 PM
Was 2024 the year of datasets? Is 2025 the year for community-built datasets?
It's exciting to see the progress of many languages in FineWeb-C:
- Total annotations submitted: 41,577
- Languages with annotations: 106
- Total contributors: 363
It's exciting to see the progress of many languages in FineWeb-C:
- Total annotations submitted: 41,577
- Languages with annotations: 106
- Total contributors: 363
Reposted by Daniel Vila
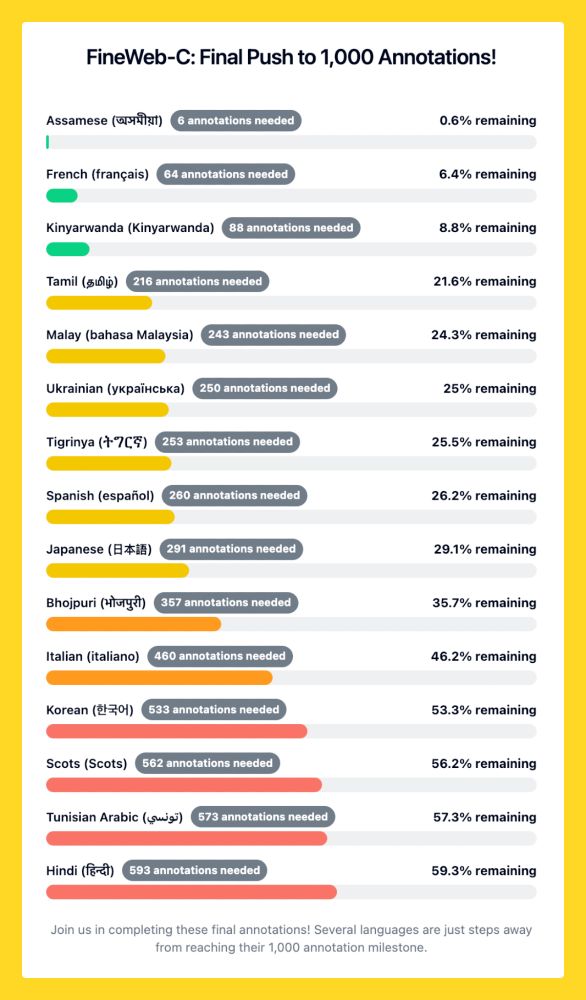
The finish line is near! We're building FineWeb-Edu for many languages and need your help 🤗
Many FineWeb-C languages are close to 1,000 annotations!
Assamese is 99.4% done, French needs 64 more annotations, Tamil: 216.
Please help us reach the goal: huggingface.co/spaces/data-...
Many FineWeb-C languages are close to 1,000 annotations!
Assamese is 99.4% done, French needs 64 more annotations, Tamil: 216.
Please help us reach the goal: huggingface.co/spaces/data-...
January 6, 2025 at 2:32 PM
The finish line is near! We're building FineWeb-Edu for many languages and need your help 🤗
Many FineWeb-C languages are close to 1,000 annotations!
Assamese is 99.4% done, French needs 64 more annotations, Tamil: 216.
Please help us reach the goal: huggingface.co/spaces/data-...
Many FineWeb-C languages are close to 1,000 annotations!
Assamese is 99.4% done, French needs 64 more annotations, Tamil: 216.
Please help us reach the goal: huggingface.co/spaces/data-...
💥 Ending 2024: A full data annotation journey on the Hugging Face Hub—from raw data to training-ready datasets!
With Argilla 2.6.0, push your data to the Hub from the UI
Let’s make 2025 the year anyone can build more transparent and accountable AI—no coding or model skills needed.
With Argilla 2.6.0, push your data to the Hub from the UI
Let’s make 2025 the year anyone can build more transparent and accountable AI—no coding or model skills needed.
December 20, 2024 at 11:14 AM
💥 Ending 2024: A full data annotation journey on the Hugging Face Hub—from raw data to training-ready datasets!
With Argilla 2.6.0, push your data to the Hub from the UI
Let’s make 2025 the year anyone can build more transparent and accountable AI—no coding or model skills needed.
With Argilla 2.6.0, push your data to the Hub from the UI
Let’s make 2025 the year anyone can build more transparent and accountable AI—no coding or model skills needed.
Reposted by Daniel Vila

🚀 Argilla v2.6.0 is here! 🎉
Let me show you how EASY it is to export your annotated datasets from Argilla to the Hugging Face Hub. 🤩
Take a look to this quick demo 👇
💁♂️ More info about the release at github.com/argilla-io/a...
#AI #MachineLearning #OpenSource #DataScience #HuggingFace #Argilla
Let me show you how EASY it is to export your annotated datasets from Argilla to the Hugging Face Hub. 🤩
Take a look to this quick demo 👇
💁♂️ More info about the release at github.com/argilla-io/a...
#AI #MachineLearning #OpenSource #DataScience #HuggingFace #Argilla
December 19, 2024 at 12:39 PM
🚀 Argilla v2.6.0 is here! 🎉
Let me show you how EASY it is to export your annotated datasets from Argilla to the Hugging Face Hub. 🤩
Take a look to this quick demo 👇
💁♂️ More info about the release at github.com/argilla-io/a...
#AI #MachineLearning #OpenSource #DataScience #HuggingFace #Argilla
Let me show you how EASY it is to export your annotated datasets from Argilla to the Hugging Face Hub. 🤩
Take a look to this quick demo 👇
💁♂️ More info about the release at github.com/argilla-io/a...
#AI #MachineLearning #OpenSource #DataScience #HuggingFace #Argilla
Reposted by Daniel Vila
🔥 We got great feedback on this: "Synthetic Data Generator"
A no-code tool to create datasets with LLMs, making it a breeze, allowing ANYONE to create datasets and models in minutes and without any code.
Blog: https://buff.ly/4gybyoT
GitHub: https://buff.ly/49IDSmd
Space: https://buff.ly/3Y1S99z
A no-code tool to create datasets with LLMs, making it a breeze, allowing ANYONE to create datasets and models in minutes and without any code.
Blog: https://buff.ly/4gybyoT
GitHub: https://buff.ly/49IDSmd
Space: https://buff.ly/3Y1S99z

Introducing the Synthetic Data Generator - Build Datasets with Natural Language
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
buff.ly
December 17, 2024 at 7:18 AM
🔥 We got great feedback on this: "Synthetic Data Generator"
A no-code tool to create datasets with LLMs, making it a breeze, allowing ANYONE to create datasets and models in minutes and without any code.
Blog: https://buff.ly/4gybyoT
GitHub: https://buff.ly/49IDSmd
Space: https://buff.ly/3Y1S99z
A no-code tool to create datasets with LLMs, making it a breeze, allowing ANYONE to create datasets and models in minutes and without any code.
Blog: https://buff.ly/4gybyoT
GitHub: https://buff.ly/49IDSmd
Space: https://buff.ly/3Y1S99z
Reposted by Daniel Vila

Well, around 10 percent of the initial goal is complete, and so far, it's been quite a one-man army effort. We're still in the hunt for more people to join and contribute to this open-source initiative.
@hf.co
data-is-better-together-fineweb-c.hf.space/share-your-p...
@hf.co
data-is-better-together-fineweb-c.hf.space/share-your-p...

tam - தமிழ் - Tamil
Join and contribute to the dataset tam - தமிழ் - Tamil
data-is-better-together-fineweb-c.hf.space
December 14, 2024 at 7:33 AM
Well, around 10 percent of the initial goal is complete, and so far, it's been quite a one-man army effort. We're still in the hunt for more people to join and contribute to this open-source initiative.
@hf.co
data-is-better-together-fineweb-c.hf.space/share-your-p...
@hf.co
data-is-better-together-fineweb-c.hf.space/share-your-p...
Reposted by Daniel Vila

The sprint for crowd sourced annotations with argilla is in full swing over at data-is-better-together-fineweb-c.hf.space
I've just contributed 100 examples to this dataset:
data-is-better-together-fineweb-c.hf.space/share-your-p...
Big thanks to @dvilasuero.hf.co, @nataliaelv.hf.co and team 🙌
I've just contributed 100 examples to this dataset:
data-is-better-together-fineweb-c.hf.space/share-your-p...
Big thanks to @dvilasuero.hf.co, @nataliaelv.hf.co and team 🙌

nds - Neddersass’sch - Low German
Join and contribute to the dataset nds - Neddersass’sch - Low German
data-is-better-together-fineweb-c.hf.space
December 13, 2024 at 7:38 AM
The sprint for crowd sourced annotations with argilla is in full swing over at data-is-better-together-fineweb-c.hf.space
I've just contributed 100 examples to this dataset:
data-is-better-together-fineweb-c.hf.space/share-your-p...
Big thanks to @dvilasuero.hf.co, @nataliaelv.hf.co and team 🙌
I've just contributed 100 examples to this dataset:
data-is-better-together-fineweb-c.hf.space/share-your-p...
Big thanks to @dvilasuero.hf.co, @nataliaelv.hf.co and team 🙌
Reposted by Daniel Vila

I've been building a small library for working with prompt templates on the @huggingface.bsky.social Hub: `pip install prompt-templates`. Motivation:
The community currently shares prompt templates in a wide variety of formats: in datasets, in model cards, as strings in .py files, as .txt/... 🧵
The community currently shares prompt templates in a wide variety of formats: in datasets, in model cards, as strings in .py files, as .txt/... 🧵
December 12, 2024 at 3:58 PM
I've been building a small library for working with prompt templates on the @huggingface.bsky.social Hub: `pip install prompt-templates`. Motivation:
The community currently shares prompt templates in a wide variety of formats: in datasets, in model cards, as strings in .py files, as .txt/... 🧵
The community currently shares prompt templates in a wide variety of formats: in datasets, in model cards, as strings in .py files, as .txt/... 🧵
Reposted by Daniel Vila

Desperate to contribute to the development of Scots language AI. I've just contributed 16 examples to this dataset:
data-is-better-together-fineweb-c.hf.space/share-your-p...
data-is-better-together-fineweb-c.hf.space/share-your-p...
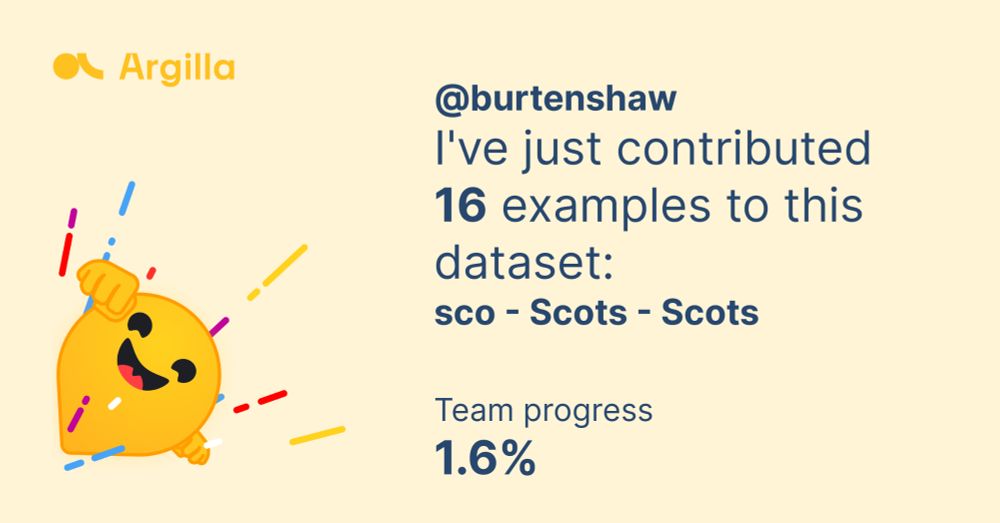
sco - Scots - Scots
Join and contribute to the dataset sco - Scots - Scots
data-is-better-together-fineweb-c.hf.space
December 12, 2024 at 1:44 PM
Desperate to contribute to the development of Scots language AI. I've just contributed 16 examples to this dataset:
data-is-better-together-fineweb-c.hf.space/share-your-p...
data-is-better-together-fineweb-c.hf.space/share-your-p...
I've just contributed 156 examples to the FineWeb 2 Spanish dataset:
data-is-better-together-fineweb-c.hf.space/share-your-p...
If you want to contribute, sign in with @hf.co and find your language
data-is-better-together-fineweb-c.hf.space/share-your-p...
If you want to contribute, sign in with @hf.co and find your language

spa - español - Spanish
Join and contribute to the dataset spa - español - Spanish
data-is-better-together-fineweb-c.hf.space
December 12, 2024 at 1:24 PM
I've just contributed 156 examples to the FineWeb 2 Spanish dataset:
data-is-better-together-fineweb-c.hf.space/share-your-p...
If you want to contribute, sign in with @hf.co and find your language
data-is-better-together-fineweb-c.hf.space/share-your-p...
If you want to contribute, sign in with @hf.co and find your language
Help shape the future of multilingual Open Source AI!
Join the FineWeb 2 Community Annotation Sprint to create an open training dataset with full transparency and human validation in many languages.
Review datasets in your language and help identify the best sources for training.
Join the FineWeb 2 Community Annotation Sprint to create an open training dataset with full transparency and human validation in many languages.
Review datasets in your language and help identify the best sources for training.

December 10, 2024 at 2:12 PM
Help shape the future of multilingual Open Source AI!
Join the FineWeb 2 Community Annotation Sprint to create an open training dataset with full transparency and human validation in many languages.
Review datasets in your language and help identify the best sources for training.
Join the FineWeb 2 Community Annotation Sprint to create an open training dataset with full transparency and human validation in many languages.
Review datasets in your language and help identify the best sources for training.
Reposted by Daniel Vila

✨ Argilla 2.5.0 is live and it comes with webhook listener support to supercharge your workflows! 🚀
#AI #MachineLearning #Webhooks #TechUpdate
#AI #MachineLearning #Webhooks #TechUpdate

December 3, 2024 at 10:46 AM
✨ Argilla 2.5.0 is live and it comes with webhook listener support to supercharge your workflows! 🚀
#AI #MachineLearning #Webhooks #TechUpdate
#AI #MachineLearning #Webhooks #TechUpdate
Reposted by Daniel Vila
👐 Open Image Preferences is an Apache 2.0 licensed dataset for text-to-image generation by the @hf.co community. This dataset contains 10K text-to-image preference pairs across image generation categories, using different model families and prompt complexities.
Blog: huggingface.co/blog/image-p...
Blog: huggingface.co/blog/image-p...

Open Preference Dataset for Text-to-Image Generation by the 🤗 Community
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
December 9, 2024 at 3:30 PM
👐 Open Image Preferences is an Apache 2.0 licensed dataset for text-to-image generation by the @hf.co community. This dataset contains 10K text-to-image preference pairs across image generation categories, using different model families and prompt complexities.
Blog: huggingface.co/blog/image-p...
Blog: huggingface.co/blog/image-p...
Reposted by Daniel Vila
Open Image Preferences released! 🚀
- Open-source dataset for text2image
- 10K samples manually evaluated by the HF community.
- Binarized format for SFT, DPO, or ORPO.
It comes with a nice blog post explaining the steps to pre-process and generate the data, along with the results.
- Open-source dataset for text2image
- 10K samples manually evaluated by the HF community.
- Binarized format for SFT, DPO, or ORPO.
It comes with a nice blog post explaining the steps to pre-process and generate the data, along with the results.

December 9, 2024 at 4:26 PM
Open Image Preferences released! 🚀
- Open-source dataset for text2image
- 10K samples manually evaluated by the HF community.
- Binarized format for SFT, DPO, or ORPO.
It comes with a nice blog post explaining the steps to pre-process and generate the data, along with the results.
- Open-source dataset for text2image
- 10K samples manually evaluated by the HF community.
- Binarized format for SFT, DPO, or ORPO.
It comes with a nice blog post explaining the steps to pre-process and generate the data, along with the results.
Announcing Global-MMLU - an improved MMLU Open dataset with evaluation coverage across 42 languages.
The result of months of work with the goal of advancing Multilingual LLM evaluation.
Built together with the community and amazing collaborators at Cohere4AI, MILA, MIT, and many more.
The result of months of work with the goal of advancing Multilingual LLM evaluation.
Built together with the community and amazing collaborators at Cohere4AI, MILA, MIT, and many more.

December 6, 2024 at 8:59 AM
Announcing Global-MMLU - an improved MMLU Open dataset with evaluation coverage across 42 languages.
The result of months of work with the goal of advancing Multilingual LLM evaluation.
Built together with the community and amazing collaborators at Cohere4AI, MILA, MIT, and many more.
The result of months of work with the goal of advancing Multilingual LLM evaluation.
Built together with the community and amazing collaborators at Cohere4AI, MILA, MIT, and many more.
We're about to launch the biggest collaboration effort since the Open Assistant.
Let's get the highest quality data for open foundation models with all the nuances & diversity of each language, all with data provenance and transparency
Join us as language lead:
docs.google.com/forms/d/10XI...
Let's get the highest quality data for open foundation models with all the nuances & diversity of each language, all with data provenance and transparency
Join us as language lead:
docs.google.com/forms/d/10XI...

Language Lead sign-up
At Hugging Face 🤗, we're launching a big community initiative to improve LLM training for many languages. We're looking for Language Leads to help us cultivate specific languages during this initiativ...
docs.google.com
December 3, 2024 at 4:53 PM
We're about to launch the biggest collaboration effort since the Open Assistant.
Let's get the highest quality data for open foundation models with all the nuances & diversity of each language, all with data provenance and transparency
Join us as language lead:
docs.google.com/forms/d/10XI...
Let's get the highest quality data for open foundation models with all the nuances & diversity of each language, all with data provenance and transparency
Join us as language lead:
docs.google.com/forms/d/10XI...
Reposted by Daniel Vila
Next week we're launching a collaborative annotation effort to build a big multilingual dataset, so you can have high-quality data in your language.
We are really close to getting leads for 100 languages! Can you help us cover the remaining 200?
We are really close to getting leads for 100 languages! Can you help us cover the remaining 200?

December 3, 2024 at 12:45 PM
Next week we're launching a collaborative annotation effort to build a big multilingual dataset, so you can have high-quality data in your language.
We are really close to getting leads for 100 languages! Can you help us cover the remaining 200?
We are really close to getting leads for 100 languages! Can you help us cover the remaining 200?
Reposted by Daniel Vila
For anyone interested in fine-tuning or aligning LLMs, I’m running this free and open course called smol course. It’s not a big deal, it’s just smol.
🧵>>
🧵>>
December 3, 2024 at 9:21 AM
For anyone interested in fine-tuning or aligning LLMs, I’m running this free and open course called smol course. It’s not a big deal, it’s just smol.
🧵>>
🧵>>
Reposted by Daniel Vila
🙌 I just wanted to share a few thoughts about the latest Argilla release, 2.5.0, as it's a pretty big one!
Argilla now has full support for webhooks, which means you can do some pretty cool stuff, like model training on the fly as annotations are created. 🤯
#MachineLearning #NLP #DataLabeling
Argilla now has full support for webhooks, which means you can do some pretty cool stuff, like model training on the fly as annotations are created. 🤯
#MachineLearning #NLP #DataLabeling
December 2, 2024 at 11:14 AM
🙌 I just wanted to share a few thoughts about the latest Argilla release, 2.5.0, as it's a pretty big one!
Argilla now has full support for webhooks, which means you can do some pretty cool stuff, like model training on the fly as annotations are created. 🤯
#MachineLearning #NLP #DataLabeling
Argilla now has full support for webhooks, which means you can do some pretty cool stuff, like model training on the fly as annotations are created. 🤯
#MachineLearning #NLP #DataLabeling
Reposted by Daniel Vila
[SATURDAY THREAD] ☕️ 🧑🎓
In case you spent the week reading GDPR legislation and missed everything. It’s all about vision language models and image preference datasets.
>> 🧵 Here are the models and datasets you can use in your projects.
In case you spent the week reading GDPR legislation and missed everything. It’s all about vision language models and image preference datasets.
>> 🧵 Here are the models and datasets you can use in your projects.
November 30, 2024 at 7:40 AM
[SATURDAY THREAD] ☕️ 🧑🎓
In case you spent the week reading GDPR legislation and missed everything. It’s all about vision language models and image preference datasets.
>> 🧵 Here are the models and datasets you can use in your projects.
In case you spent the week reading GDPR legislation and missed everything. It’s all about vision language models and image preference datasets.
>> 🧵 Here are the models and datasets you can use in your projects.