




Pinned
Sara Han
@sdiazlor.hf.co
· Nov 21
✨ Time to introduce myself to the new followers!
I'm working on ML and advocacy. Till now, I have focused on building Argilla and distilabel. But I'll also share updates and cool stuff from the AI community, tools, or notebooks.
P.S. Maybe a bit of my 🐕 and 🎮 too!
I'm working on ML and advocacy. Till now, I have focused on building Argilla and distilabel. But I'll also share updates and cool stuff from the AI community, tools, or notebooks.
P.S. Maybe a bit of my 🐕 and 🎮 too!
💫 Generate RAG data with the Synthetic Data Generator to improve your RAG system!
1️⃣ Generate from your documents, dataset, or dataset description.
2️⃣ Configure it.
3️⃣ Generate the synthetic dataset.
4️⃣ Fine-tune the retrieval and reranking models.
5️⃣ Build a RAG pipeline.
1️⃣ Generate from your documents, dataset, or dataset description.
2️⃣ Configure it.
3️⃣ Generate the synthetic dataset.
4️⃣ Fine-tune the retrieval and reranking models.
5️⃣ Build a RAG pipeline.
January 20, 2025 at 4:42 PM
💫 Generate RAG data with the Synthetic Data Generator to improve your RAG system!
1️⃣ Generate from your documents, dataset, or dataset description.
2️⃣ Configure it.
3️⃣ Generate the synthetic dataset.
4️⃣ Fine-tune the retrieval and reranking models.
5️⃣ Build a RAG pipeline.
1️⃣ Generate from your documents, dataset, or dataset description.
2️⃣ Configure it.
3️⃣ Generate the synthetic dataset.
4️⃣ Fine-tune the retrieval and reranking models.
5️⃣ Build a RAG pipeline.
Reposted by Sara Han

🚀 Argilla v2.6.0 is here! 🎉
Let me show you how EASY it is to export your annotated datasets from Argilla to the Hugging Face Hub. 🤩
Take a look to this quick demo 👇
💁♂️ More info about the release at github.com/argilla-io/a...
#AI #MachineLearning #OpenSource #DataScience #HuggingFace #Argilla
Let me show you how EASY it is to export your annotated datasets from Argilla to the Hugging Face Hub. 🤩
Take a look to this quick demo 👇
💁♂️ More info about the release at github.com/argilla-io/a...
#AI #MachineLearning #OpenSource #DataScience #HuggingFace #Argilla
December 19, 2024 at 12:39 PM
🚀 Argilla v2.6.0 is here! 🎉
Let me show you how EASY it is to export your annotated datasets from Argilla to the Hugging Face Hub. 🤩
Take a look to this quick demo 👇
💁♂️ More info about the release at github.com/argilla-io/a...
#AI #MachineLearning #OpenSource #DataScience #HuggingFace #Argilla
Let me show you how EASY it is to export your annotated datasets from Argilla to the Hugging Face Hub. 🤩
Take a look to this quick demo 👇
💁♂️ More info about the release at github.com/argilla-io/a...
#AI #MachineLearning #OpenSource #DataScience #HuggingFace #Argilla
🙅♀️ No-code end-to-end example to train your model
1️⃣ Use the Synthetic Data Generator to create your custom dataset
2️⃣ Use AutoTrain to use the generated dataset and train your model
Check it here: huggingface.co/blog/synthet...
1️⃣ Use the Synthetic Data Generator to create your custom dataset
2️⃣ Use AutoTrain to use the generated dataset and train your model
Check it here: huggingface.co/blog/synthet...

December 18, 2024 at 11:28 AM
🙅♀️ No-code end-to-end example to train your model
1️⃣ Use the Synthetic Data Generator to create your custom dataset
2️⃣ Use AutoTrain to use the generated dataset and train your model
Check it here: huggingface.co/blog/synthet...
1️⃣ Use the Synthetic Data Generator to create your custom dataset
2️⃣ Use AutoTrain to use the generated dataset and train your model
Check it here: huggingface.co/blog/synthet...
Where do I get quality data from? We often need to fine-tune models for very specific scenarios. And that’s where the Synthetic Data Generator comes in!
Want to see how it works? Watch this quick video (www.youtube.com/watch?v=nXjV...) and get started here: t.co/hJ1b2TsMq0
Want to see how it works? Watch this quick video (www.youtube.com/watch?v=nXjV...) and get started here: t.co/hJ1b2TsMq0

Synthetic Data Generator - Build Datasets Using Natural Language
YouTube video by Argilla
www.youtube.com
December 16, 2024 at 4:14 PM
Where do I get quality data from? We often need to fine-tune models for very specific scenarios. And that’s where the Synthetic Data Generator comes in!
Want to see how it works? Watch this quick video (www.youtube.com/watch?v=nXjV...) and get started here: t.co/hJ1b2TsMq0
Want to see how it works? Watch this quick video (www.youtube.com/watch?v=nXjV...) and get started here: t.co/hJ1b2TsMq0
Pouco a pouco avanzamos! 🚀 Anímovos a contribuir, tan só tedes que entrar na ligazón, ler as instrucións e comezar a anotar ✍
data-is-better-together-fineweb-c.hf.space/share-your-p...
data-is-better-together-fineweb-c.hf.space/share-your-p...

glg - galego - Galician
Join and contribute to the dataset glg - galego - Galician
data-is-better-together-fineweb-c.hf.space
December 12, 2024 at 3:30 PM
Pouco a pouco avanzamos! 🚀 Anímovos a contribuir, tan só tedes que entrar na ligazón, ler as instrucións e comezar a anotar ✍
data-is-better-together-fineweb-c.hf.space/share-your-p...
data-is-better-together-fineweb-c.hf.space/share-your-p...
Spanish, Filipino, Amharic, French, German, Basque, Catalan, Galician, Guarani, Telugu, Italian, Pashto, Romanian, Tamil, Urdu, Danish... and many more! All included in the FineWeb2 Community Annotation Sprint! 🔥
💫 Join to build an impactful dataset for your language!
💫 Join to build an impactful dataset for your language!
December 10, 2024 at 12:35 PM
Spanish, Filipino, Amharic, French, German, Basque, Catalan, Galician, Guarani, Telugu, Italian, Pashto, Romanian, Tamil, Urdu, Danish... and many more! All included in the FineWeb2 Community Annotation Sprint! 🔥
💫 Join to build an impactful dataset for your language!
💫 Join to build an impactful dataset for your language!
Open Image Preferences released! 🚀
- Open-source dataset for text2image
- 10K samples manually evaluated by the HF community.
- Binarized format for SFT, DPO, or ORPO.
It comes with a nice blog post explaining the steps to pre-process and generate the data, along with the results.
- Open-source dataset for text2image
- 10K samples manually evaluated by the HF community.
- Binarized format for SFT, DPO, or ORPO.
It comes with a nice blog post explaining the steps to pre-process and generate the data, along with the results.

December 9, 2024 at 4:26 PM
Open Image Preferences released! 🚀
- Open-source dataset for text2image
- 10K samples manually evaluated by the HF community.
- Binarized format for SFT, DPO, or ORPO.
It comes with a nice blog post explaining the steps to pre-process and generate the data, along with the results.
- Open-source dataset for text2image
- 10K samples manually evaluated by the HF community.
- Binarized format for SFT, DPO, or ORPO.
It comes with a nice blog post explaining the steps to pre-process and generate the data, along with the results.
This is crazy! Were you right in your predictions?
December 5, 2024 at 10:11 AM
This is crazy! Were you right in your predictions?
Language is power! A multilingual annotation sprint for hundreds of languages is starting soon! Step up as a Language Lead and help drive this effort for your language.
If there's already a Language Lead, stay tuned! Is this the start of a nice community?
docs.google.com/forms/d/e/1F...
If there's already a Language Lead, stay tuned! Is this the start of a nice community?
docs.google.com/forms/d/e/1F...

Language Lead sign-up
At Hugging Face 🤗, we're launching a big community initiative to improve LLM training for many languages. We're looking for Language Leads to help us cultivate specific languages during this initiativ...
docs.google.com
December 3, 2024 at 11:57 AM
Language is power! A multilingual annotation sprint for hundreds of languages is starting soon! Step up as a Language Lead and help drive this effort for your language.
If there's already a Language Lead, stay tuned! Is this the start of a nice community?
docs.google.com/forms/d/e/1F...
If there's already a Language Lead, stay tuned! Is this the start of a nice community?
docs.google.com/forms/d/e/1F...
To end the week on a high note, my furry friend ⭐

December 1, 2024 at 12:16 PM
To end the week on a high note, my furry friend ⭐
Want to improve your model quality? Implement the data annotation stage in your MLOps effortlessly thanks to the enhanced integration of Argilla with ZenML.
✨Use the latest Argilla features
✨Improve human-in-the-loop workflows
✨Manage datasets, track progress, and coordinate your annotation team
✨Use the latest Argilla features
✨Improve human-in-the-loop workflows
✨Manage datasets, track progress, and coordinate your annotation team

November 29, 2024 at 11:47 AM
Want to improve your model quality? Implement the data annotation stage in your MLOps effortlessly thanks to the enhanced integration of Argilla with ZenML.
✨Use the latest Argilla features
✨Improve human-in-the-loop workflows
✨Manage datasets, track progress, and coordinate your annotation team
✨Use the latest Argilla features
✨Improve human-in-the-loop workflows
✨Manage datasets, track progress, and coordinate your annotation team
🚀 QwQ-32B-Preview is available on the Hub!
> The results are very promising, beating o1-mini.
> However, they also have several limitations you might notice even in the demo (I found endless reasoning trying to find out the number of 'r' in 🍓). So, let's see how they deal with them.
> The results are very promising, beating o1-mini.
> However, they also have several limitations you might notice even in the demo (I found endless reasoning trying to find out the number of 'r' in 🍓). So, let's see how they deal with them.

November 28, 2024 at 10:42 AM
🚀 QwQ-32B-Preview is available on the Hub!
> The results are very promising, beating o1-mini.
> However, they also have several limitations you might notice even in the demo (I found endless reasoning trying to find out the number of 'r' in 🍓). So, let's see how they deal with them.
> The results are very promising, beating o1-mini.
> However, they also have several limitations you might notice even in the demo (I found endless reasoning trying to find out the number of 'r' in 🍓). So, let's see how they deal with them.
Reposted by Sara Han

It's pretty sad to see the negative sentiment towards Hugging Face on this platform due to a dataset put by one of the employees. I want to write a small piece. 🧵
Hugging Face empowers everyone to use AI to create value and is against monopolization of AI it's a hosting platform above all.
Hugging Face empowers everyone to use AI to create value and is against monopolization of AI it's a hosting platform above all.
November 27, 2024 at 3:23 PM
It's pretty sad to see the negative sentiment towards Hugging Face on this platform due to a dataset put by one of the employees. I want to write a small piece. 🧵
Hugging Face empowers everyone to use AI to create value and is against monopolization of AI it's a hosting platform above all.
Hugging Face empowers everyone to use AI to create value and is against monopolization of AI it's a hosting platform above all.
Reposted by Sara Han

Hugging Face inference endpoints now support CPU deployment for llama.cpp 🚀 🚀
Why this is a huge deal? Llama.cpp is well-known for running very well on CPU. If you're running small models like Llama 1B or embedding models, this will definitely save tons of money 💰 💰
Why this is a huge deal? Llama.cpp is well-known for running very well on CPU. If you're running small models like Llama 1B or embedding models, this will definitely save tons of money 💰 💰
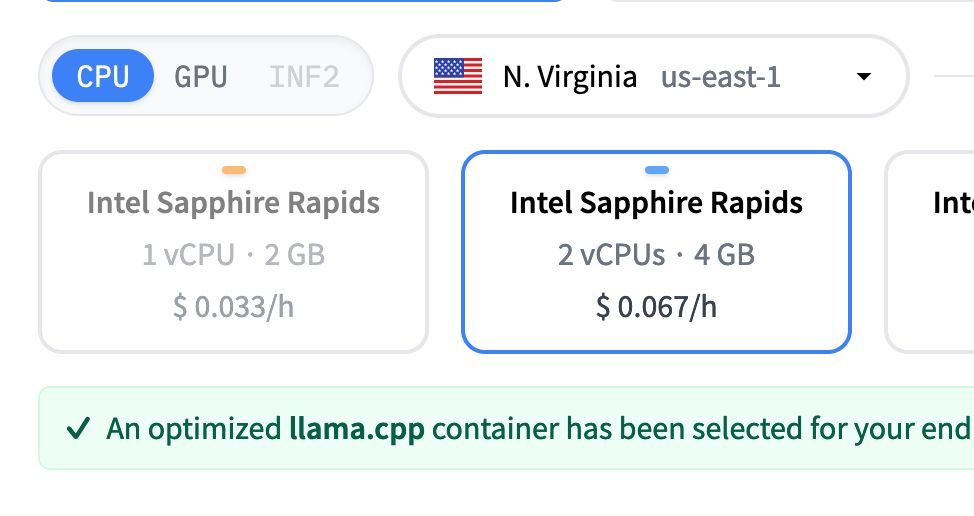
November 27, 2024 at 11:01 AM
Hugging Face inference endpoints now support CPU deployment for llama.cpp 🚀 🚀
Why this is a huge deal? Llama.cpp is well-known for running very well on CPU. If you're running small models like Llama 1B or embedding models, this will definitely save tons of money 💰 💰
Why this is a huge deal? Llama.cpp is well-known for running very well on CPU. If you're running small models like Llama 1B or embedding models, this will definitely save tons of money 💰 💰
🎨 Help to build an image preference dataset!
> Goal: Release an open-source image dataset, enabling the entire community to benefit from it.
> Requirements: All you need is a Hugging Face account and a willingness to contribute.
More in 🧵
> Goal: Release an open-source image dataset, enabling the entire community to benefit from it.
> Requirements: All you need is a Hugging Face account and a willingness to contribute.
More in 🧵

November 26, 2024 at 4:20 PM
🎨 Help to build an image preference dataset!
> Goal: Release an open-source image dataset, enabling the entire community to benefit from it.
> Requirements: All you need is a Hugging Face account and a willingness to contribute.
More in 🧵
> Goal: Release an open-source image dataset, enabling the entire community to benefit from it.
> Requirements: All you need is a Hugging Face account and a willingness to contribute.
More in 🧵
Reposted by Sara Han

Let's make AI more inclusive.
At @huggingface.bsky.social we'll launch a huge community sprint soon to build high-quality training datasets for many languages.
We're looking for Language Leads to help with outreach.
Find your language and nominate yourself:
forms.gle/iAJVauUQ3FN8...
At @huggingface.bsky.social we'll launch a huge community sprint soon to build high-quality training datasets for many languages.
We're looking for Language Leads to help with outreach.
Find your language and nominate yourself:
forms.gle/iAJVauUQ3FN8...
November 26, 2024 at 6:29 AM
Let's make AI more inclusive.
At @huggingface.bsky.social we'll launch a huge community sprint soon to build high-quality training datasets for many languages.
We're looking for Language Leads to help with outreach.
Find your language and nominate yourself:
forms.gle/iAJVauUQ3FN8...
At @huggingface.bsky.social we'll launch a huge community sprint soon to build high-quality training datasets for many languages.
We're looking for Language Leads to help with outreach.
Find your language and nominate yourself:
forms.gle/iAJVauUQ3FN8...
Reposted by Sara Han

"Naftali was assigned to train AI to recognize and weed out pornography, hate speech and excessive violence, which meant sifting through the worst of the worst content online for hours on end."
So much of AI is based on exploiting workers in precarious conditions 😔
www.cbsnews.com/news/labeler...
So much of AI is based on exploiting workers in precarious conditions 😔
www.cbsnews.com/news/labeler...

Labelers training AI say they're overworked, underpaid and exploited by big American tech companies
Digital workers in Kenya had to sift through horrific online content to train AI, but say they were underpaid, overworked, and got inadequate mental health support. So they're fighting back.
www.cbsnews.com
November 25, 2024 at 3:16 PM
"Naftali was assigned to train AI to recognize and weed out pornography, hate speech and excessive violence, which meant sifting through the worst of the worst content online for hours on end."
So much of AI is based on exploiting workers in precarious conditions 😔
www.cbsnews.com/news/labeler...
So much of AI is based on exploiting workers in precarious conditions 😔
www.cbsnews.com/news/labeler...
Argilla has reached the 4K stars on GitHub! ✨
Thanks to everyone for the support! We'll continue shipping new updates for you to curate your data easily ✍️ And, for sure, your feedback is more than welcome 🙌
Thanks to everyone for the support! We'll continue shipping new updates for you to curate your data easily ✍️ And, for sure, your feedback is more than welcome 🙌

November 25, 2024 at 9:51 AM
Argilla has reached the 4K stars on GitHub! ✨
Thanks to everyone for the support! We'll continue shipping new updates for you to curate your data easily ✍️ And, for sure, your feedback is more than welcome 🙌
Thanks to everyone for the support! We'll continue shipping new updates for you to curate your data easily ✍️ And, for sure, your feedback is more than welcome 🙌
Reposted by Sara Han

Making SmolLM2 more reproducible: open-sourcing our training & evaluation toolkit 🛠️ github.com/huggingface/...
Pre-training & evaluation code, synthetic data generation pipelines, post-training scripts, on-device tools & demos
Apache 2.0. V2 data mix coming soon!
Which tools should we add next?
Pre-training & evaluation code, synthetic data generation pipelines, post-training scripts, on-device tools & demos
Apache 2.0. V2 data mix coming soon!
Which tools should we add next?
GitHub - huggingface/smollm: Everything about the SmolLM & SmolLM2 family of models
Everything about the SmolLM & SmolLM2 family of models - GitHub - huggingface/smollm: Everything about the SmolLM & SmolLM2 family of models
github.com
November 24, 2024 at 7:16 AM
Making SmolLM2 more reproducible: open-sourcing our training & evaluation toolkit 🛠️ github.com/huggingface/...
Pre-training & evaluation code, synthetic data generation pipelines, post-training scripts, on-device tools & demos
Apache 2.0. V2 data mix coming soon!
Which tools should we add next?
Pre-training & evaluation code, synthetic data generation pipelines, post-training scripts, on-device tools & demos
Apache 2.0. V2 data mix coming soon!
Which tools should we add next?
Go to your HF profile and spot the differences. Could you find them?
.
.
.
Yes, you're right! You can now add your Bluesky account and also check your recent activity 🙌
.
.
.
Yes, you're right! You can now add your Bluesky account and also check your recent activity 🙌
November 23, 2024 at 11:36 AM
Go to your HF profile and spot the differences. Could you find them?
.
.
.
Yes, you're right! You can now add your Bluesky account and also check your recent activity 🙌
.
.
.
Yes, you're right! You can now add your Bluesky account and also check your recent activity 🙌
Reposted by Sara Han

We're big on transparency and love all things open at @huggingface.bsky.social so we thought, why not share our internal mission, vision, and values with everyone? Take a read and let us know what you think! It's such a special place!

November 22, 2024 at 10:32 PM
We're big on transparency and love all things open at @huggingface.bsky.social so we thought, why not share our internal mission, vision, and values with everyone? Take a read and let us know what you think! It's such a special place!
Reposted by Sara Han

A cool space from the community to explore the many open datasets we released from building Tulu 3 (SOTA open post training recipe).
Tülu 3, my favourite Open Source AI release ever
As @natolambert.bsky.social says, it sets the next era in open post-training.
My highlight? the data generation & open datasets
Want to deep dive into the data? Here's an Argilla @huggingface.bsky.social Space
huggingface.co/spaces/argil...
As @natolambert.bsky.social says, it sets the next era in open post-training.
My highlight? the data generation & open datasets
Want to deep dive into the data? Here's an Argilla @huggingface.bsky.social Space
huggingface.co/spaces/argil...

Tulu3 Awesome Datasets - a Hugging Face Space by argilla
Discover amazing ML apps made by the community
huggingface.co
November 22, 2024 at 3:58 PM
A cool space from the community to explore the many open datasets we released from building Tulu 3 (SOTA open post training recipe).
The SmolLM2 recipe isn't more of a secret! SmolTalk has been released on the Hub.
It uses a mix of public and synthetic data, including Magpie Ultra using distilabel 🚀
huggingface.co/datasets/Hug...
It uses a mix of public and synthetic data, including Magpie Ultra using distilabel 🚀
huggingface.co/datasets/Hug...

HuggingFaceTB/smoltalk · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
November 22, 2024 at 12:43 PM
The SmolLM2 recipe isn't more of a secret! SmolTalk has been released on the Hub.
It uses a mix of public and synthetic data, including Magpie Ultra using distilabel 🚀
huggingface.co/datasets/Hug...
It uses a mix of public and synthetic data, including Magpie Ultra using distilabel 🚀
huggingface.co/datasets/Hug...
Reposted by Sara Han

Excited to announce the SFT dataset used for @huggingface.bsky.social SmolLM2!
The dataset for SmolLM2 was created by combining multiple existing datasets and generating new synthetic datasets, including MagPie Ultra v1.0, using distilabel.
Check out the dataset:
huggingface.co/datasets/Hug...
The dataset for SmolLM2 was created by combining multiple existing datasets and generating new synthetic datasets, including MagPie Ultra v1.0, using distilabel.
Check out the dataset:
huggingface.co/datasets/Hug...

HuggingFaceTB/smoltalk · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
November 21, 2024 at 3:22 PM
Excited to announce the SFT dataset used for @huggingface.bsky.social SmolLM2!
The dataset for SmolLM2 was created by combining multiple existing datasets and generating new synthetic datasets, including MagPie Ultra v1.0, using distilabel.
Check out the dataset:
huggingface.co/datasets/Hug...
The dataset for SmolLM2 was created by combining multiple existing datasets and generating new synthetic datasets, including MagPie Ultra v1.0, using distilabel.
Check out the dataset:
huggingface.co/datasets/Hug...
✨ Time to introduce myself to the new followers!
I'm working on ML and advocacy. Till now, I have focused on building Argilla and distilabel. But I'll also share updates and cool stuff from the AI community, tools, or notebooks.
P.S. Maybe a bit of my 🐕 and 🎮 too!
I'm working on ML and advocacy. Till now, I have focused on building Argilla and distilabel. But I'll also share updates and cool stuff from the AI community, tools, or notebooks.
P.S. Maybe a bit of my 🐕 and 🎮 too!
November 21, 2024 at 12:14 PM
✨ Time to introduce myself to the new followers!
I'm working on ML and advocacy. Till now, I have focused on building Argilla and distilabel. But I'll also share updates and cool stuff from the AI community, tools, or notebooks.
P.S. Maybe a bit of my 🐕 and 🎮 too!
I'm working on ML and advocacy. Till now, I have focused on building Argilla and distilabel. But I'll also share updates and cool stuff from the AI community, tools, or notebooks.
P.S. Maybe a bit of my 🐕 and 🎮 too!