


Drew Bailey
@drewhalbailey.bsky.social
education, developmental psychology, research methods at UC Irvine
So hard! When there is no cross-lagged effect in this data generating model, RI-CLPM estimates one, but when there *is* one effect, the ARTS model doesn't! Not sure the paper bears much on whether cross-lagged effects are rare, but def on our ability to use these models without external info.
October 3, 2025 at 9:42 PM
So hard! When there is no cross-lagged effect in this data generating model, RI-CLPM estimates one, but when there *is* one effect, the ARTS model doesn't! Not sure the paper bears much on whether cross-lagged effects are rare, but def on our ability to use these models without external info.
I really like this paper dealing with the problem of “mischievous” responding in longitudinal panel data, by @joecimpian.bsky.social
journals.sagepub.com/doi/full/10....
journals.sagepub.com/doi/full/10....

Sage Journals: Discover world-class research
Subscription and open access journals from Sage, the world's leading independent academic publisher.
journals.sagepub.com
September 9, 2025 at 12:16 AM
I really like this paper dealing with the problem of “mischievous” responding in longitudinal panel data, by @joecimpian.bsky.social
journals.sagepub.com/doi/full/10....
journals.sagepub.com/doi/full/10....
Dag makhani: Causal inference and Indian cuisine
August 25, 2025 at 5:43 PM
Dag makhani: Causal inference and Indian cuisine
Like, the effect of dropping a bouncing ball on the velocity of the ball over time is a weird oscillating function?
August 19, 2025 at 3:55 PM
Like, the effect of dropping a bouncing ball on the velocity of the ball over time is a weird oscillating function?
Although field-specific authorship norms probably mostly just reflect the values of people in the field, I also think they can affect those values too. This seems like a good example! (I have some guesses about unintended consequences of tiny authorship teams too, btw.)
June 23, 2025 at 2:14 PM
Although field-specific authorship norms probably mostly just reflect the values of people in the field, I also think they can affect those values too. This seems like a good example! (I have some guesses about unintended consequences of tiny authorship teams too, btw.)
Reposted by Drew Bailey

6) LCGAs never replicate across datasets or in the same dataset. They usually just produce the salsa pattern (Hi/med/low) or the cats cradle (Hi/low/increasing/decreasing).
This has misled entire fields (see all of George Bonnano's work on resilience, for example).
psycnet.apa.org/fulltext/201...
This has misled entire fields (see all of George Bonnano's work on resilience, for example).
psycnet.apa.org/fulltext/201...
APA PsycNet
psycnet.apa.org
June 20, 2025 at 7:05 PM
6) LCGAs never replicate across datasets or in the same dataset. They usually just produce the salsa pattern (Hi/med/low) or the cats cradle (Hi/low/increasing/decreasing).
This has misled entire fields (see all of George Bonnano's work on resilience, for example).
psycnet.apa.org/fulltext/201...
This has misled entire fields (see all of George Bonnano's work on resilience, for example).
psycnet.apa.org/fulltext/201...
But I really hope we get 10 more years of strong studies now on the effects of large increases in access on outcomes for "always takers" and especially for elite students. There are lots of good reasons to expect these effects should differ. (2/2)
June 11, 2025 at 8:35 PM
But I really hope we get 10 more years of strong studies now on the effects of large increases in access on outcomes for "always takers" and especially for elite students. There are lots of good reasons to expect these effects should differ. (2/2)
Reposted by Drew Bailey

I investigated how often papers' significant (p < .05) results are fragile (.01 ≤ p < .05) p-values. An excess of such p-values suggests low odds of replicability.
From 2004-2024, the rates of fragile p-values have gone down precipitously across every psychology discipline (!)
From 2004-2024, the rates of fragile p-values have gone down precipitously across every psychology discipline (!)
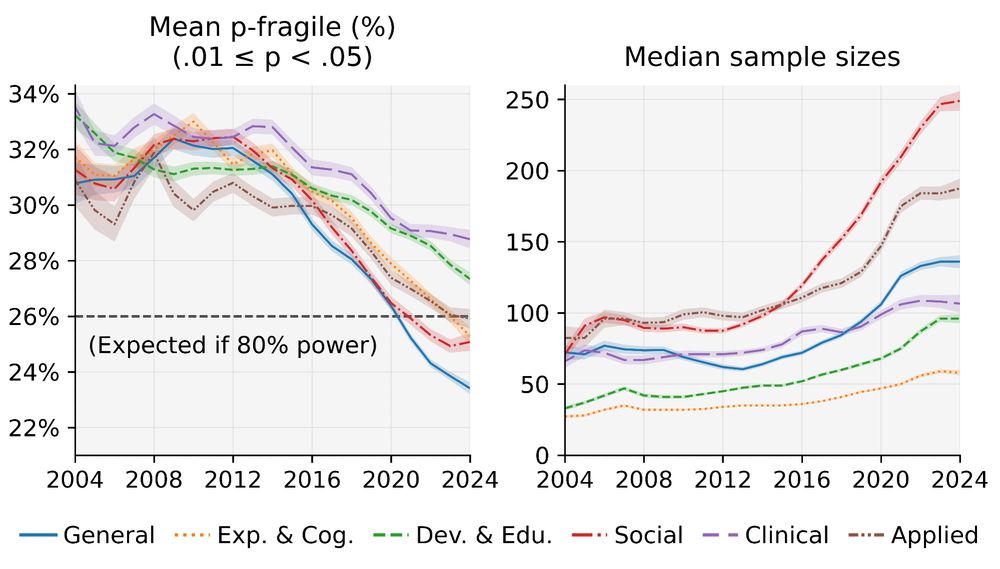
April 9, 2025 at 1:15 PM
I investigated how often papers' significant (p < .05) results are fragile (.01 ≤ p < .05) p-values. An excess of such p-values suggests low odds of replicability.
From 2004-2024, the rates of fragile p-values have gone down precipitously across every psychology discipline (!)
From 2004-2024, the rates of fragile p-values have gone down precipitously across every psychology discipline (!)
Hope to see at least one of these in each APS policy brief from now on!
May 15, 2025 at 7:57 PM
Hope to see at least one of these in each APS policy brief from now on!
(Not saying the public is right necessarily; you can get programs that pass a cost-benefit test with much smaller effects on test scores than laypeople want. But it is a problem for policymakers that the public wants them policy to deliver unrealistically sized effects.)
May 8, 2025 at 6:36 PM
(Not saying the public is right necessarily; you can get programs that pass a cost-benefit test with much smaller effects on test scores than laypeople want. But it is a problem for policymakers that the public wants them policy to deliver unrealistically sized effects.)
If you ask people what kinds of effects they’d need to decide to implement something new, they’re much bigger than realistically sized effects in ed policy. We’ve decided collectively to pretend this isn’t a problem and then get surprised at the backlash when it comes.
May 8, 2025 at 6:34 PM
If you ask people what kinds of effects they’d need to decide to implement something new, they’re much bigger than realistically sized effects in ed policy. We’ve decided collectively to pretend this isn’t a problem and then get surprised at the backlash when it comes.