



David Nordström
@davnords.bsky.social
Phd Student @ Chalmers
Deep Learning for Computer Vision.
Strengthen your ViTs: https://github.com/davnords/octic-vits
Deep Learning for Computer Vision.
Strengthen your ViTs: https://github.com/davnords/octic-vits
Reposted by David Nordström

Presenting today at #BMVC2025 our follow-up work on anisotropic rotation averaging which is particularly useful in global SfM. We propose a fast solver ACD and integrate robust optimization.
If you’re at the conference, welcome to come to our poster #516!
bmvc2025.bmva.org/proceedings/...
If you’re at the conference, welcome to come to our poster #516!
bmvc2025.bmva.org/proceedings/...

November 25, 2025 at 10:16 AM
Presenting today at #BMVC2025 our follow-up work on anisotropic rotation averaging which is particularly useful in global SfM. We propose a fast solver ACD and integrate robust optimization.
If you’re at the conference, welcome to come to our poster #516!
bmvc2025.bmva.org/proceedings/...
If you’re at the conference, welcome to come to our poster #516!
bmvc2025.bmva.org/proceedings/...
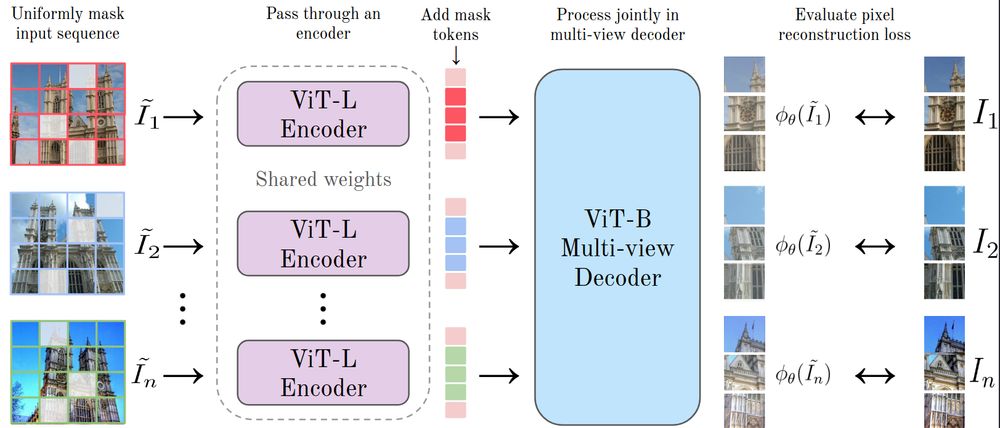
We are introducing MuM, a feature encoder (ViT-L) tailored for 3D vision tasks.
TLDR; Spiritual successor to CroCo with a simpler multi-view objective and larger scale. Beats DINOv3 and CroCo v2 in RoMa, feedforward reconstruction, and rel. pose.
arxiv.org/abs/2511.17309
github.com/davnords/mum
TLDR; Spiritual successor to CroCo with a simpler multi-view objective and larger scale. Beats DINOv3 and CroCo v2 in RoMa, feedforward reconstruction, and rel. pose.
arxiv.org/abs/2511.17309
github.com/davnords/mum
November 24, 2025 at 10:27 AM
We are introducing MuM, a feature encoder (ViT-L) tailored for 3D vision tasks.
TLDR; Spiritual successor to CroCo with a simpler multi-view objective and larger scale. Beats DINOv3 and CroCo v2 in RoMa, feedforward reconstruction, and rel. pose.
arxiv.org/abs/2511.17309
github.com/davnords/mum
TLDR; Spiritual successor to CroCo with a simpler multi-view objective and larger scale. Beats DINOv3 and CroCo v2 in RoMa, feedforward reconstruction, and rel. pose.
arxiv.org/abs/2511.17309
github.com/davnords/mum
Johan out here carrying Swedish CV academia with a 10 author absolute masterclass. Only the avatar can master all four elements (LiU, CTH, LTH and UvA).
Very strong and versatile model overall. RoMa v2 can match anything you'd like. Even @bokmangeorg.bsky.social 's hand annotated satellite images.
Very strong and versatile model overall. RoMa v2 can match anything you'd like. Even @bokmangeorg.bsky.social 's hand annotated satellite images.
RoMa v2 is now out! (github.com/Parskatt/rom..., arxiv.org/abs/2511.15706)
Here are the main improvements we made since RoMa:
Here are the main improvements we made since RoMa:


November 20, 2025 at 10:06 AM
Johan out here carrying Swedish CV academia with a 10 author absolute masterclass. Only the avatar can master all four elements (LiU, CTH, LTH and UvA).
Very strong and versatile model overall. RoMa v2 can match anything you'd like. Even @bokmangeorg.bsky.social 's hand annotated satellite images.
Very strong and versatile model overall. RoMa v2 can match anything you'd like. Even @bokmangeorg.bsky.social 's hand annotated satellite images.
Reposted by David Nordström

RoMa v2: Harder Better Faster Denser Feature Matching
@parskatt.bsky.social et 11 al.
tl;dr: in title.
Predict covariance per-pixel, more datasets, use DINOv3, adjust architecture.
arxiv.org/abs/2511.15706
@parskatt.bsky.social et 11 al.
tl;dr: in title.
Predict covariance per-pixel, more datasets, use DINOv3, adjust architecture.
arxiv.org/abs/2511.15706




November 20, 2025 at 9:08 AM
RoMa v2: Harder Better Faster Denser Feature Matching
@parskatt.bsky.social et 11 al.
tl;dr: in title.
Predict covariance per-pixel, more datasets, use DINOv3, adjust architecture.
arxiv.org/abs/2511.15706
@parskatt.bsky.social et 11 al.
tl;dr: in title.
Predict covariance per-pixel, more datasets, use DINOv3, adjust architecture.
arxiv.org/abs/2511.15706
Reposted by David Nordström

Turns out NLP is just vision

Z.ai released a paper very similar to DeepSeek-OCR on the same exact day (a few hours earlier afaict)
Glyph is just a framework, not a model, but they got Qwen3-8B (128k context) to handle over 1 million context by rendering input as images
arxiv.org/abs/2510.17800
Glyph is just a framework, not a model, but they got Qwen3-8B (128k context) to handle over 1 million context by rendering input as images
arxiv.org/abs/2510.17800

October 21, 2025 at 4:39 PM
Turns out NLP is just vision
These gentlemen show how not only colmap but also VGGT fail on spherical motion in their ICCV oral paper "Uncalibrated Structure from Motion on a Sphere".
I wonder if it is just a data issue for VGGT or if it is deeper than that. I mean VGGT was trained on mostly synthetic data. What do you think?
I wonder if it is just a data issue for VGGT or if it is deeper than that. I mean VGGT was trained on mostly synthetic data. What do you think?

October 22, 2025 at 12:21 AM
These gentlemen show how not only colmap but also VGGT fail on spherical motion in their ICCV oral paper "Uncalibrated Structure from Motion on a Sphere".
I wonder if it is just a data issue for VGGT or if it is deeper than that. I mean VGGT was trained on mostly synthetic data. What do you think?
I wonder if it is just a data issue for VGGT or if it is deeper than that. I mean VGGT was trained on mostly synthetic data. What do you think?
Reposted by David Nordström
Pro tip: For good Halloween vibes, use non-normalized RoPE on images larger than your training resolution and larger than the composite period of some of the RoPE-rotations. You might get scary ghost structures in your features.

October 16, 2025 at 2:53 PM
Pro tip: For good Halloween vibes, use non-normalized RoPE on images larger than your training resolution and larger than the composite period of some of the RoPE-rotations. You might get scary ghost structures in your features.
Reposted by David Nordström

RoMa now on PyPI under name of `romatch`

September 23, 2025 at 7:56 PM
RoMa now on PyPI under name of `romatch`
Reposted by David Nordström
Towards the Next Generation of 3D Reconstruction
@parskatt.bsky.social PhD Thesis.
tl;dr: would be useful in teaching image matching - nice explanations. (too) Fancy and stylish notation. Cool Ack section and cover image.
liu.diva-portal.org/smash/record...
@parskatt.bsky.social PhD Thesis.
tl;dr: would be useful in teaching image matching - nice explanations. (too) Fancy and stylish notation. Cool Ack section and cover image.
liu.diva-portal.org/smash/record...




September 18, 2025 at 6:25 AM
Towards the Next Generation of 3D Reconstruction
@parskatt.bsky.social PhD Thesis.
tl;dr: would be useful in teaching image matching - nice explanations. (too) Fancy and stylish notation. Cool Ack section and cover image.
liu.diva-portal.org/smash/record...
@parskatt.bsky.social PhD Thesis.
tl;dr: would be useful in teaching image matching - nice explanations. (too) Fancy and stylish notation. Cool Ack section and cover image.
liu.diva-portal.org/smash/record...
Reposted by David Nordström
And here is a link to the thesis itself: liu.diva-portal.org/smash/record...
Towards the Next Generation of 3D Reconstruction
liu.diva-portal.org
September 17, 2025 at 6:31 AM
And here is a link to the thesis itself: liu.diva-portal.org/smash/record...
Reposted by David Nordström

How to name your method: a comprehensive flow chart

September 13, 2025 at 3:32 PM
How to name your method: a comprehensive flow chart
Reposted by David Nordström
Born too late to explore the earth.
Born too early to explore the galaxy.
Born just in time to \nabla_{\theta}f_{\theta}
Born too early to explore the galaxy.
Born just in time to \nabla_{\theta}f_{\theta}
July 26, 2025 at 1:38 AM
Born too late to explore the earth.
Born too early to explore the galaxy.
Born just in time to \nabla_{\theta}f_{\theta}
Born too early to explore the galaxy.
Born just in time to \nabla_{\theta}f_{\theta}
Presented with my co-supervisor @bokmangeorg.bsky.social at #ICML25, fun time!

July 16, 2025 at 2:22 AM
Presented with my co-supervisor @bokmangeorg.bsky.social at #ICML25, fun time!
Reposted by David Nordström
Tomorrow at ICML [Tuesday 4:30 pm, poster W-213] @davnords.bsky.social and I will present our spotlighted flop paper. Come by and let us try to convince you that equivariant nets should be standard in vision tasks due to computational benefits! bsky.app/profile/bokm...

July 15, 2025 at 4:32 AM
Tomorrow at ICML [Tuesday 4:30 pm, poster W-213] @davnords.bsky.social and I will present our spotlighted flop paper. Come by and let us try to convince you that equivariant nets should be standard in vision tasks due to computational benefits! bsky.app/profile/bokm...
I am at ICML, happy to connect with all of you :)
July 14, 2025 at 2:03 PM
I am at ICML, happy to connect with all of you :)
Reposted by David Nordström
And today I'm presenting this work at #CVPR2025!
🗓️ Date: 16:00-18:00, Fri, Jun 13 (Today)
📍Place: Poster #115 in Session 2 (ExHall D)
💻 Code: github.com/ericssonrese...
🗓️ Date: 16:00-18:00, Fri, Jun 13 (Today)
📍Place: Poster #115 in Session 2 (ExHall D)
💻 Code: github.com/ericssonrese...
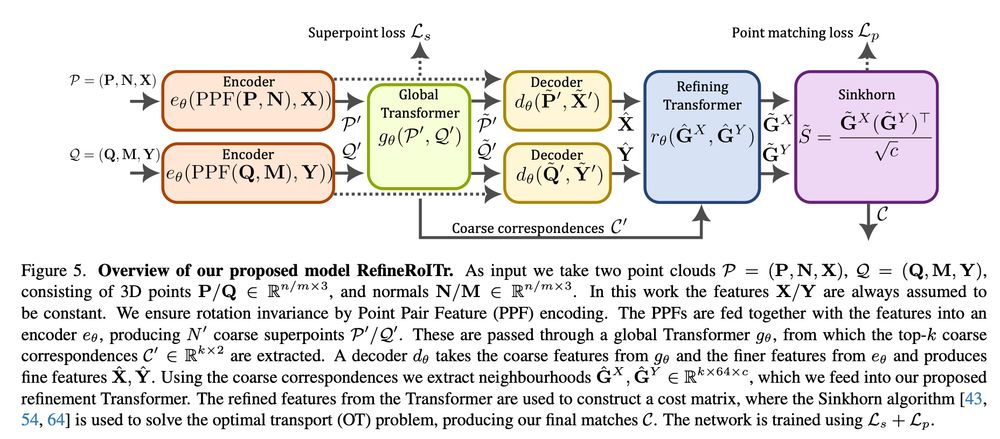
ColabSfM: Collaborative Structure-from-Motion by Point Cloud Registration
@parskatt.bsky.social , André Mateus, Alberto Jaenal
tl;dr: in title, learning to register SfM point clouds.
arxiv.org/abs/2503.17093
@parskatt.bsky.social , André Mateus, Alberto Jaenal
tl;dr: in title, learning to register SfM point clouds.
arxiv.org/abs/2503.17093



June 13, 2025 at 3:02 PM
And today I'm presenting this work at #CVPR2025!
🗓️ Date: 16:00-18:00, Fri, Jun 13 (Today)
📍Place: Poster #115 in Session 2 (ExHall D)
💻 Code: github.com/ericssonrese...
🗓️ Date: 16:00-18:00, Fri, Jun 13 (Today)
📍Place: Poster #115 in Session 2 (ExHall D)
💻 Code: github.com/ericssonrese...
Reposted by David Nordström

Reposted by David Nordström
As models become larger, more of their compute is spent in the MLP.
Turns out that this is perfect for octic equivariance, as our biggest gains are there!
Turns out that this is perfect for octic equivariance, as our biggest gains are there!

May 23, 2025 at 9:51 AM
As models become larger, more of their compute is spent in the MLP.
Turns out that this is perfect for octic equivariance, as our biggest gains are there!
Turns out that this is perfect for octic equivariance, as our biggest gains are there!
Want stronger Vision Transformers? Use octic-equivariant layers (arxiv.org/abs/2505.15441).
TLDR; We extend @bokmangeorg.bsky.social's reflection-equivariant ViTs to the (octic) group of 90-degree rotations and reflections and... it just works... (DINOv2+DeiT)
Code: github.com/davnords/octic-vits
TLDR; We extend @bokmangeorg.bsky.social's reflection-equivariant ViTs to the (octic) group of 90-degree rotations and reflections and... it just works... (DINOv2+DeiT)
Code: github.com/davnords/octic-vits

May 23, 2025 at 7:38 AM
Want stronger Vision Transformers? Use octic-equivariant layers (arxiv.org/abs/2505.15441).
TLDR; We extend @bokmangeorg.bsky.social's reflection-equivariant ViTs to the (octic) group of 90-degree rotations and reflections and... it just works... (DINOv2+DeiT)
Code: github.com/davnords/octic-vits
TLDR; We extend @bokmangeorg.bsky.social's reflection-equivariant ViTs to the (octic) group of 90-degree rotations and reflections and... it just works... (DINOv2+DeiT)
Code: github.com/davnords/octic-vits
GPT 4o's new image capabilities seem to be liked. The insinuation from OpenAI seems to be that it is not based on diffusion. I wonder how their work relates to the infamous NeurIPS paper "Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction" (arxiv.org/abs/2404.02905)

March 28, 2025 at 1:32 AM
GPT 4o's new image capabilities seem to be liked. The insinuation from OpenAI seems to be that it is not based on diffusion. I wonder how their work relates to the infamous NeurIPS paper "Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction" (arxiv.org/abs/2404.02905)
Reposted by David Nordström
New paper!
We merge SfM reconstructions with point cloud registration.
Link: arxiv.org/abs/2503.17093
Code: Not yet public, but coming later.
We merge SfM reconstructions with point cloud registration.
Link: arxiv.org/abs/2503.17093
Code: Not yet public, but coming later.

March 24, 2025 at 9:49 AM
New paper!
We merge SfM reconstructions with point cloud registration.
Link: arxiv.org/abs/2503.17093
Code: Not yet public, but coming later.
We merge SfM reconstructions with point cloud registration.
Link: arxiv.org/abs/2503.17093
Code: Not yet public, but coming later.
Reposted by David Nordström
New paper! (arxiv.org/abs/2503.13433), we look into improving the threshold roubustness of Random Sample Consensus (RANSAC) through (less biased) inlier noise scale estimation.

March 18, 2025 at 4:48 AM
New paper! (arxiv.org/abs/2503.13433), we look into improving the threshold roubustness of Random Sample Consensus (RANSAC) through (less biased) inlier noise scale estimation.
Reposted by David Nordström

Introducing VGGT (CVPR'25), a feedforward Transformer that directly infers all key 3D attributes from one, a few, or hundreds of images, in seconds!
Project Page: vgg-t.github.io
Code & Weights: github.com/facebookrese...
Project Page: vgg-t.github.io
Code & Weights: github.com/facebookrese...
March 17, 2025 at 2:08 AM
Introducing VGGT (CVPR'25), a feedforward Transformer that directly infers all key 3D attributes from one, a few, or hundreds of images, in seconds!
Project Page: vgg-t.github.io
Code & Weights: github.com/facebookrese...
Project Page: vgg-t.github.io
Code & Weights: github.com/facebookrese...
Reposted by David Nordström
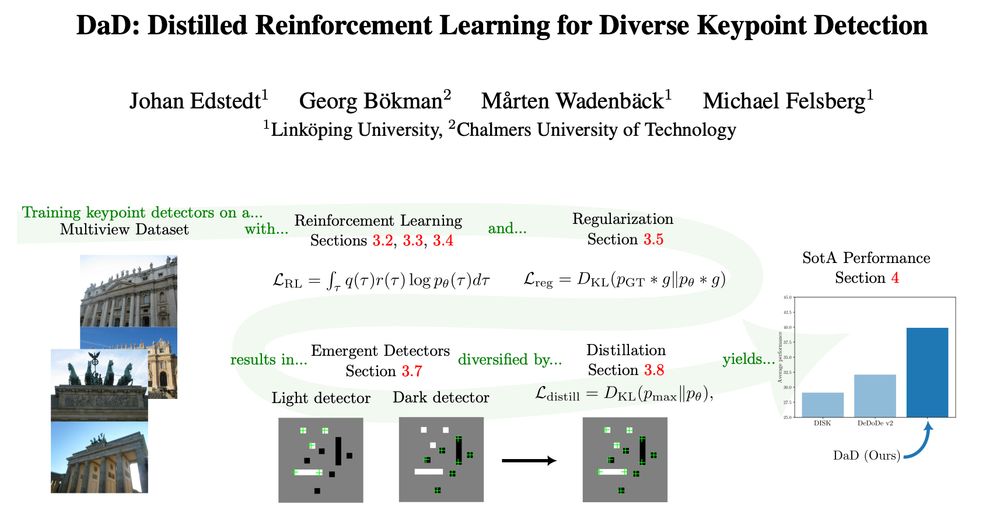
Introducing DaD, Part 2, a pretty cool keypoint detector.
Introducing DaD (arxiv.org/abs/2503.07347), a pretty cool keypoint detector.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
March 11, 2025 at 4:00 AM
Introducing DaD, Part 2, a pretty cool keypoint detector.
Reposted by David Nordström
We made a new keypoint detector named DaD, paper isn't up yet, but code and weights are:
github.com/Parskatt/dad
github.com/Parskatt/dad

March 10, 2025 at 7:53 AM
We made a new keypoint detector named DaD, paper isn't up yet, but code and weights are:
github.com/Parskatt/dad
github.com/Parskatt/dad